








Last Updated on 11월 7, 2023 by Jade(정현호)
Contents
MHA Summary
HA 는 High Availability 의 약자로 고 가용성을 의미하며 장애 발생시 최대한 단축을 의미합니다.
MHA 는 Master High Availability 약자로 Master DB의 고가용성을 위해 Yoshinori Matsunobu(현 Facebook)에 의해 개발되었으며 GPL v2 라이센스 기반의 오픈소스입니다.

Master / Slave 구조의 Replication 환경에서 Master DB의 장애 발생시 수동으로 하는 Master를 변경을 사람이 개입되어 작업을 하다 보면 서비스 중단 시간이 길어지므로 자동화할 수 있는 기능을 만든 것입니다.
MHA에 의해서 장애 발생시 자동 Fail-Over(Master 승격)를 지원하고 Slave 중 가장 최신의 Slave DB를 Master DB로 승격시켜 고가용성을 유지시키는 역할을 하게 됩니다.
그리고 Slave DB 간에 binlog 적용의 차이를 해결하는 기능을 제공합니다.
또한 정해진 작업에 의한 사용자 임의의 Take-Over 와 Fail-Back 을 지원하며, 1:N(Slave) 를 지원합니다.
MHA의 기능 지원
MHA 는 MySQL의 고 가용성을 위해 아래와 같이 여러 기능에 대해서 지원하고 있습니다.
1. Master DB의 네트워크 단절(통신불가 나 3306포트 접속 불가)시 Fail-Over
2. Master DB의 mysqld 프로세스의 비정상 종료되어 DB 접속이 불가할 경우
3. Fail-Over시 기존 Master DB 와 새로운 Master DB 간의 최대한의 데이터 정합성 보장
-> show slave status : Second behind master 값을 확인하여 Slave 에서 복제가 더 될 내용이 남 아 있다면(동기화가 아직 완료되지 않았다면) Mater DB의 Binlog 을 읽어서 새로운 Master DB에 반영
-> 단 네트워크의 단절 및 서버의 전원장애나 Shutdown , Disk 장애(깨짐) 등으로 기존 Master 에서 데이터를 읽을 수 없는 예외 상황을 제외하고 최근까지 작성된 binlog 을 읽을 수 있다면 읽어서 새롭게 Master DB가 될 slave에 적용하여 정합성을 최대한 유지하기 위한 기능 지원
4. Slave DB 간의 적용된 Binlog 차이를 확인하여 복제 정합성 기능을 제공
5. Master DB 와 Slave DB간의 수동 Online 스위치 오버 및 데이터 정합성 유지
6. 복제에 대한 모니터링
7. MHA 0.56 부터는 MySQL 5.6 GTID 및 Multi-Threaded slave 기능을 지원
마스터 장애 조치 및 빠른 슬레이브 승격
MHA 는 일반적으로 몇 초 ~ 수십 초 만에 장애 조치를 수행할 수 있습니다
마스터DB의 오류를 감지하는 데 9-12 초 정도 소요되며, 선택적으로 스플릿 브레인을 방지하기 위해 마스터 시스템의 전원을 끄는 데 7-10 초, 새 마스터 DB에 차이가 발생한 릴레이 로그를 적용하는 데 몇 초가 소요되므로 총 다운 타임은 일반적으로 10-30 초 정도 소요됩니다.
MHA의 장애 발생시 Failover
MHA는 Master DB가 장애가 발생하게 되면 자동으로 페일오버를 수행하게 되며 대략 10~30초 사이에 최신의 Slave DB를 Master DB로 승격시켜서 다운타임을 최소화하게 됩니다.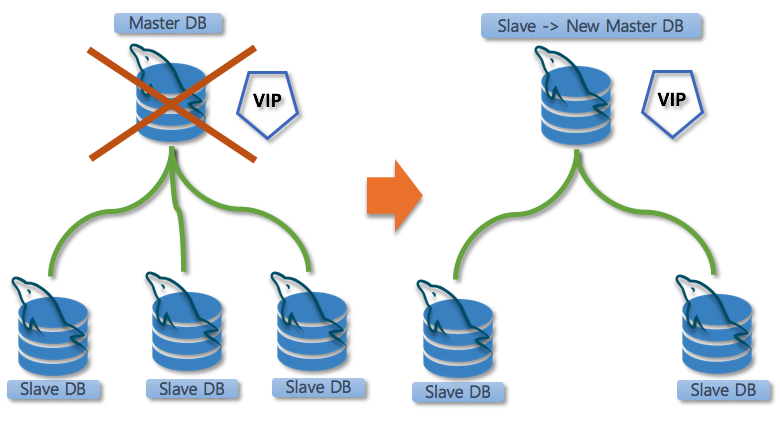
Master 1 : Slave N 의 구조로 사용되는 유형이 보통이기 때문에 Failover시 고려되어야 할 것이 어느 Slave가 Master 로 승격될지 구분되어야 하고 최신의 Slave DB 가 Master DB 로 승격된 이후에는 다른 슬레이브가 아직 모든 바이너리 로그 이벤트를 수신하지 않았을 가능성이 있습니다.
이러한 일관성 문제를 방지하려면 새 (승격된) 마스터에서 복제를 시작하기 전에 손실된 binlog 이벤트 (아직 모든 슬레이브에 도달하지 않은)를 식별하고 각 슬레이브에 차례로 적용해야 합니다.
이런 다른 Slave 간의 동기화, 정합성 문제는 사람이 개입하여 하게 되면 이 작업은 매우 복잡하고 수동으로 수행하기 어려울 수 있습니다
그래서 이런 부분을 MHA를 통해 비교적 쉽고 빠르게 장애처리 및 Failover 를 할 수 있게 됩니다.
장애시 수행되는 Failover 절차

[mha4mysql-manager/wiki/Architecture]
Master DB의 장애가 발생 시 아래와 같은 흐름으로 Failover 가 진행되게 됩니다.
1. Master DB의 장애 발생되면 MHA 가 감지를 하게 됩니다.
2. Slave DB 중 가장 최신의 Slave DB를 선택하여 Master DB 로 승격하게 됩니다.
승격 시 아래의 데이터를 참조하여 대상을 선정하게 됩니다.
1) show slave status\G 와 각 slave DB의 relay log를 확인
2) relay log 에서 end_log_pos 값 비교
3. Slave DB 중 데이터 복제가 가장 느린 Slave(i) DB에서 SQL 스레드가 릴레이로그에 기록된 모든 이벤트 실행(executes)을 하게 되고 이 과정이 끝날 때까지 다음 과정은 대기하게 됩니다.
4. Slave(i) DB 가 적용한 마스터 DB의 로그 파일과 로그 포지션 정보 를 최신의 Slave DB(마스터로 승격된) 가 읽은 바이너리 로그 파일, 로그 포지션을 비교하여 차이가 발생하는 부분의 트랜잭션을 Slave(i)에 반영하게 됩니다.
5. 마지막으로 최신의 Slave DB(마스터로 승격된)는 반영된 바이너리 로그 포지션 이후 ~ 장애가 발생된 시점의 마지막 Master DB의 바이너리 로그 포지션 차이를 적용하면 장애시점의 Master DB의 데이터 시점까지 복구가 완료되게 됩니다
장애가 발생한 Master DB의 바이너리 로그 포지션 차이를 적용하면 모든 슬레이브 DB는 장애시점의 Master DB 데이터까지는 복구가 완료가 됩니다.
이 과정은 Master DB 서버가 접근이 가능하며, 장애시점의 Binlog 를 읽을 수 있을 경우에 수행됩니다.
만약 물리적인 서버 자체의 문제가 있어서 서버에 접속이 불가능하다면 위의 과정(5번)은 수행할 수 없습니다.
MHA 와 Lossless Replication
반 동기식 복제 - Semi Sync/Lossless Replication
MySQL에서는 Lossless Replication 인 Semi-Sync Replication을 Mysql 5.5 버전부터 지원합니다.
[Semi Sync - after_sync Replication]
이는 Master DB에서 데이터 변경이 되면 Slave 어딘가에 반드시 변경이력(relay log)이 남아있다는 것을 보장하게 됩니다.
그래서 이러한 Semi Sync/Lossless Replication 은 Crash(장애)가 발생한 Master DB 에만 BinLog Event 존재하게 되는 위험한 상황을 최소화하게 됩니다.
위에서 언급 한것처럼 1:N 구성으로 slave 가 단수 존재 할때 반 동기식 복제는 ** 적어도 하나 ** (전부는 아님) 슬레이브 DB가 커밋시 마스터로부터 binlog 이벤트를 수신하도록 보장합니다.
문제는 장애 발생시 모든 slave DB가 Master DB의 binlog 이벤트를 수신하지 못했을 가능성이 있습니다.
이럴 경우 slave 에서 수신하지 못한 이벤트를 적용을 해줘야 새로운 master 와 기존의 slave 간의 데이터 일관성 문제등을 해결할 수 있게 됩니다.
MHA는 이러한 일관성 문제를 처리하는 기능을 제공함으로 Semi-Synchronous 복제와 MHA를 모두 사용하여 "데이터 손실이 거의 없음"과 "슬레이브 일관성"을 모두 달성할 수 있습니다.
또한 MHA 0.56 버전부터는 Multi-Threaded slave 기능을 지원하며 MySQL 5.7 에서는 단점을 개선한 LOGICAL_CLOCK 방식의 도입되었습니다.
따라서 Multi-Threaded slave 사용시 replication 복제 성능이 이전보다 향상되었음으로 MHA을 사용할 때 Semi-Sync Replication 와 Multi-Threaded slave(LOGICAL_CLOCK) 를 사용하는 것이 binlog event loss 를 방지하면서 Replication 의 성능향상을 기대할 수 있는 설정일 것 같습니다.
[참고] MySQL Semi-Sync Replication 은 아래 포스팅을 참조하시면 됩니다.


MHA New Features
√ MHA 0.57 New Features
Code cleanup: Disconnecting properly on connection checks
plaintext 형태 패스워드에 대해서 Masking 처리
긴 Update 에 대한 체크시 event schedueler 무시
Ping 추가를 위해 InnoDB 사용
Create/delete 테스트를 위한 테이블을 InnoDB 대신 MyISAM 으로 사용
√ MHA 0.56 New Features
MySQL 5.6 GTID 지원
( If GTID and auto position is enabled, MHA automatically does failover using GTID syntax)
MySQL 5.6 Multi-Threaded slave 지원
MySQL 5.6 binlog checksum 지원
mysqlbinlog streaming hosts 지원
In some cases, people use binlog archiving servers via streaming mysqlbinlog.
MHA supports that by [binlog] section. This works with GTID. If [binlog] is added,
MHA checks the hosts and if it has more binlog events than other slaves,
MHA uses these events for recovery.
사용자 정의(Custom) mysql and mysqlbinlog 경로 지원
Master와의 연결 확인을 위해서 ping_type=INSERT 을 추가
=> Master가 쓰기를 불가 할 경우 유용합니다.(i.e. disk error)
master_ip_online_change_script 에 --orig_master_is_new_slave, --orig_master_ssh_user and --new_master_ssh_user 항목이 추가되었습니다.
purge_relay_logs 을 위해 --socket and --defaults-file 이 추가되었습니다.
* MHA 0.58 의 New Feature 에 대한 wiki 가 존재하지 않습니다.
MHA Component
MHA 는 MHA manager 와 MHA node 로 구성되어 있습니다.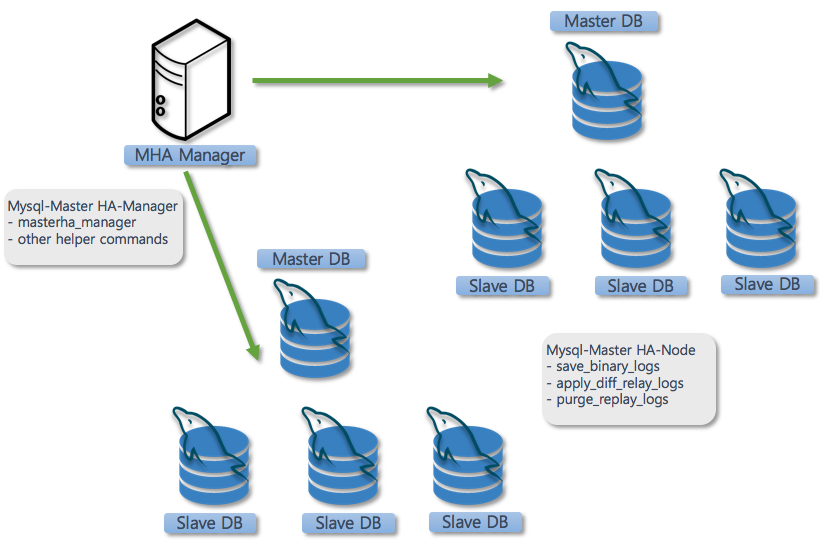
매니저 패키지
마스터와 슬레이브DB 쌍(pair)을 이루어 같이 관리할 수 있습니다.
masterha_manager : 자동화된 마스터DB 모니터링 및 장애 조치 명령 수행
other helper scripts : 수동으로 마스터DB 페일 오버, 온라인 마스터DB 스위치, Connection 체크 등 기타 작업 수행
노드 패키지
모든 MySQL 서버에 배포
• save_binary_logs : 액세스 가능한 경우 마스터의 바이너리 로그 복사
• Apply_diff_relay_logs : 최신의 슬레이브 DB에서 차이가 나는 릴레이 로그 생성하고 모든 차이가 나는 binlog 이벤트를 적용
• purge_relay_logs : SQL 스레드를 중지하지 않고 릴레이 로그를 삭제
MHA Manager 는 MySQL 마스터의 모니터링, 마스터의 장애 조치 제어 등과 같은 관리 프로그램을 포함하고 있습니다.
MHA Node 는 MySQL의 바이너리, 릴레이 로그 파싱, 릴레이 로그를 다른 슬레이브에 적용해야 하는 릴레이 로그 위치 식별, 대상 슬레이브에 이벤트 적용 등과 같은 장애 조치에 도움이 되는 스크립트가 있습니다.
MHA Node 는 각 MySQL 서버에서 실행됩니다.
MHA Manager 에서 장애 조치를 수행할 때 MHA Manager 에서 SSH를 통해 MHA Node 를 연결하고 필요할 때 MHA Node 명령을 실행합니다.
그렇기 때문에 MHA 구성전이나 구성과정에서 MHA Manager 서버와 MHA 노드간에는 패스워드 입력 없이 SSH 접속이 가능한 인증이 설정되어야 합니다.
MHA Custom Extension
MHA에는 몇 가지 사용자 정의 Custom Extension 을 제공합니다.
예를 들어 MHA는 사용자 지정 스크립트를 호출하여 마스터의 IP 주소를 업데이트 할 수 있습니다
(마스터의 IP 주소를 관리하는 글로벌 카탈로그 데이터베이스 업데이트, 가상 IP 업데이트 등)
IP 주소를 관리하는 방법은 사용자의 환경에 따라 다르며 MHA는 특정 방식을 강요하지 않고 사용자가 수정하여 사용할 수 있게 하고 있습니다.
MHA manager 에는 다음의 샘플 스크립트가 포함되어 있습니다. 해당 스크립트를 수정하여 사용하면 됩니다.
- secondary_check_script : 여러 네트워크 경로에서 마스터DB 가용성을 확인합니다.
- master_ip_failover_script : 응용 프로그램에서 사용되는 마스터의 IP 주소를 갱신합니다.
- shutdown_script: Master DB의 강제 종료합니다.
- report_script: 리포트를 전송하는데 사용합니다.
- init_conf_load_script : 초기 구성 파라미터를 로드 하기 위해 사용합니다.
- master_ip_online_change_script : 마스터 IP 주소를 주소를 갱신합니다.
이것은 마스터의 페일 오버에는 사용하는 게 아니라 온라인 마스터DB 스위치에 사용됩니다.
Reference
Reference link.
https://github.com/yoshinorim/mha4mysql-manager
https://github.com/yoshinorim/mha4mysql-node
https://github.com/yoshinorim/mha4mysql-manager/wiki
https://www2.slideshare.net/matsunobu/automated-master-failover
Book.
DBA를 위한 MySQL 운영 기술
이어지는 다음 글 - MySQL 5.7(+VIP사용) 환경의 내용
MySQL 8.0(RockyLinux8+ProxySQL) 내용
연관된 다른 글






Principal DBA(MySQL, AWS Aurora, Oracle)
핀테크 서비스인 핀다에서 데이터베이스를 운영하고 있어요(at finda.co.kr)
Previous - 당근마켓, 위메프, Oracle Korea ACS / Fedora Kor UserGroup 운영중
Database 외에도 NoSQL , Linux , Python, Cloud, Http/PHP CGI 등에도 관심이 있습니다
purityboy83@gmail.com / admin@hoing.io


