









Last Updated on 4월 27, 2024 by Jade(정현호)
Contents
1. 새로운 기능이 도입된 이유
MySQL 에서 Block Nested-Loop 와 Batched Key Access Joins 그리고 Multi Range Read(MRR) 을 도입 및 추가한 이유로는 쉽게 Join Method 인 Nested Loop 조인의 한계점을 보완하고 개선하기 위해서입니다.
조인되는 Driven 테이블 컬럼에 인덱스가 없을 경우 오라클의 보통의 경우 hash 조인으로 수행되게 됩니다(예전이나 상황에 따라서 Merge Join 으로 수행될 수도 있음) 하지만 Join Method 가 Nested Loop 조인의 경우 Driving 테이블의 추출 건수만큼 Driven(Inner) 테이블 Full Scan 을 반복적으로 스캔을 해야 합니다. 이럴 경우 절대적으로 성능 저하를 일으키게 됩니다.
이러한 많은 건수의 Nested-Loop 조인의 상황을 조금이라도 해소하고 도움이 되고자 Block Nested-Loop 와 Batched Key Access Joins(그리고 Multi Range Read(MRR)) 이라는 기능이 추가된 것입니다 근본적인 해결책이라고 생각하기 보다는 Nested-Loop 조인만 사용 가능한 상황(버전)에서의 차선책입니다.
이 부분은 MySQL 8.0.18 버전에서 드디어 Hash Join 추가되면서 어느정도 대용량 조인에 대해서 해결할 수 있게 되었습니다.
2. Block Nested-Loop
Block Nested-Loop(이하 BNL) 방식은 별도의 버퍼인 조인 버퍼를 이용하여 Driving 되는 테이블의 레코드를 조인 버퍼에 저장한 후에 Driven 테이블(후행 테이블)을 스캔하면서 조인 버퍼를 탐색하는 방식입니다
당연히 BNL 을 사용하지 않는 Nested-Loop 에 비해 BNL 를 사용하는 것이 빠릅니다. 하지만 Nested Loop 조인에 대한 차선책일 뿐 근본적인 해결책은 아닙니다
BNL 알고리즘의 원리를 다시 설명 드리면 Driving 테이블의 결과를 조인 버퍼에 저장하고 메모리 루프의 각 데이터 행을 전체 버퍼의 레코드와 비교하여 내부 루프의 스캔 횟수를 줄일 수 있습니다.
간단한 예를 들면 Driving 테이블의 결과 루프의 결과 집합에는 1000 행의 데이터가 있고 Driven 테이블(내부 테이블, Inner 테이블) 은 NLJ(Nested-Loop Join) 알고리즘을 사용하게 되면 1000 번 스캔 해야 하지만 BNL 알고리즘을 사용하는 경우 예를 들어 100개 행 집합을 비교한다면 먼저 Driving 테이블 결과를 조인 버퍼에 설정하고 저장한 다음 Driven 테이블의 각 데이터 행을 사용하여 100 개 행의 결과 집합과 비교합니다.
한 번에 100 개의 데이터 행과 비교할 수 있으므로 내부 테이블에는 실제로 1000/100 = 10 회 로 루프 순환하면서 NLJ보다 9/10 감소하게 되는 것입니다.
Driving 테이블의 row를 조인 버퍼에 더이상 데이터를 채울 수 없는 시점, 즉 Driving 테이블 조건에 해당하는 데이터를 모두 처리할 때까지 반복 수행합니다. 여기서 조인되어지는 Driven(후행 테이블)의 스캔하는 횟수는 조인 버퍼에 데이터가 적재되는 횟수와 동일하게 됩니다.
optimizer_switch 시스템 변수에서 block_nested_loop 값은 Block Nested-Loop 알고리즘을 사용하는지 여부를 제어하게 되며 기본적으로 block_nested_loop 활성화되어 있습니다.
mysql> show variables like 'optimizer_switch%'\G
*************************** 1. row ***************************
Variable_name: optimizer_switch
Value: index_merge=on,index_merge_union=on,index_merge_sort_union=on
,index_merge_intersection=on,engine_condition_pushdown=on,
index_condition_pushdown=on,mrr=on,mrr_cost_based=on
,block_nested_loop=on <-------------------
,batched_key_access=off,materialization=on
,semijoin=on,loosescan=on,firstmatch=on,duplicateweedout=on,
subquery_materialization_cost_based=on,use_index_extensions=on,
condition_fanout_filter=on,derived_merge=on,prefer_ordering_index=on
EXPLAIN 출력에서 Extra 에 Using join buffer(Block Nested Loop) 이 표시 되며 BNL이 사용됨을 의미합니다.
2-1 테스트 데이터 생성
포스팅에서 사용할 테스트 테이블 및 데이터 생성을 하도록 하겠습니다.
mysql> create database test_db;
mysql> use test_db;
--프로시저 생성
DELIMITER $$
DROP PROCEDURE IF EXISTS gen_data$$
CREATE PROCEDURE gen_data(
IN v_rows INT
)
BEGIN
DECLARE i INT DEFAULT 1;
create table tb_test1(
no bigint,
col1 varchar(100),
col2 varchar(100),
col3 varchar(100)
);
WHILE i <= v_rows DO
INSERT INTO tb_test1 (no , col1, col2 , col3 )
VALUES(concat(i), concat('col1-',i), concat('col2-',i), concat('col3-',i));
SET i = i + 1;
END WHILE;
END$$
DELIMITER ;
-- 데이터 생성
mysql> call gen_data(10000);
-- 조인 대상 테이블 생성
mysql> create table tb_test2
as
select * from tb_test1;
Query OK, 10000 rows affected (0.09 sec)
2-2 플랜 확인 및 테스트
Block Nested Loop 조인이 사용되면 아래와 같이 Extra 항목에서 확인할 수 있게 되며 데이터 량 조회 조건 등에 따라서 결과는 상이하나 BNL 이 동작할 수 있는 조건에서는 보편적으로 BNL 이 더 좋은 성능을 보여주게 됩니다.
-- BNL 사용시 mysql> explain select * from tb_test1 a INNER JOIN tb_test2 b ON a.no=b.no and a.no between 1 and 5000; +----+--------+-------+------+------+------+------+----------+----------------------------------------------------+ | id | type | table | type | key | ref | rows | filtered | Extra | +----+--------+-------+------+------+------+------+----------+----------------------------------------------------+ | 1 | SIMPLE | a | ALL | NULL | NULL | 9149 | 11.11 | Using where | | 1 | SIMPLE | b | ALL | NULL | NULL | 9149 | 10.00 | Using where; Using join buffer (Block Nested Loop) | +----+--------+-------+------+------+------+------+----------+----------------------------------------------------+ -- BNL 미사용시 : 힌트로 제어 가능 mysql> explain select /*+ no_bnl(b) */ * from tb_test1 a INNER JOIN tb_test2 b ON a.no=b.no and a.no between 1 and 5000; +----+-------------+-------+------+---------------+------+---------+------+------+----------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------+---------------+------+---------+------+------+----------+-------------+ | 1 | SIMPLE | a | ALL | NULL | NULL | NULL | NULL | 9149 | 11.11 | Using where | | 1 | SIMPLE | b | ALL | NULL | NULL | NULL | NULL | 9149 | 10.00 | Using where | +----+-------------+-------+------+---------------+------+---------+------+------+----------+-------------+ -- 실제 수행 mysql> set profiling=1; mysql> select * from tb_test1 a INNER JOIN tb_test2 b ON a.no=b.no and a.no between 1 and 5000; mysql> select /*+ no_bnl(b) */ * from tb_test1 a INNER JOIN tb_test2 b ON a.no=b.no and a.no between 1 and 5000; mysql> show profiles\G *************************** 1. row *************************** Query_ID: 1 Duration: 2.20080325 <---- 2 초 Query: select * from tb_test1 a INNER JOIN tb_test1 b ON a.no=b.no and a.no between 1 and 5000 *************************** 2. row *************************** Query_ID: 2 Duration: 16.32182325 <---- 16 초 Query: select /*+ no_bnl(b) */ * from tb_test1 a INNER JOIN tb_test1 b ON a.no=b.no and a.no between 1 and 5000 mysql> set profiling=0;
* Plan 결과는 가로 길이를 줄이기 위해서 일부 컬럼은 편집되어 있습니다.
이와 같이 BNL 이 사용가능한 조건이나 데이터 량에 따라 BNL 알고리즘 사용시 사용 유무에 따른 성능 차이가 확연하게 확인되는 것을 알 수 있습니다.
3. Multi Rang Read
Multi Range Read(MRR) 는 MySQL 5.6 에서 새로 추가된 옵티마이저 기능입니다. 보조 인덱스인 Non-Clustered Index에서 Range Scan을 사용하여 테이블의 행을 읽게 되는 경우 테이블에 대한 랜덤 디스크 액세스가 많이 발생할 수 있게 됩니다.
아래 이미지가 보조 인덱스에서 Index range scan 이후 테이블에 대해서 랜덤 디스크 액세스가 발생되는 내용을 표현한 것입니다.
Multi Range Read(MRR)는 이러한 Random I/O를 Sequential I/O로 처리할 수 있도록 도와주는 기능으로, Non-Clustered Index를 통해 Range Scan을 하는 경우, 바로 데이터를 조회하지 않고 어느 정도 rowid(primary key) 값들을 Random 버퍼(MySQL: read_rnd_buffer_size / MariaDB: mrr_buffer_size)에 채운 다음, 버퍼 내용을 정렬하여 최대한 rowid(primary key) 순서대로 데이터를 접근할 수 있도록 해주는 기능입니다.
Disk-Sweep Multi-Range Read (MRR) 최적화를 통해 MySQL은 먼저 인덱스만 스캔하고 관련 행에 대한 키를 수집하여 범위 스캔에 대한 랜덤 디스크 액세스 수를 줄이려고 합니다. 아래 이미지와 같이 버퍼를 통해 키를 정렬하게 되고 기본 키의 순서를 사용하여 테이블에서 행이 검색하게 됩니다. Disk-sweep MRR의 사용 목적은 랜덤 디스크 액세스 수를 줄이고 대신 테이블 데이터를 보다 순차적으로 스캔하는 것입니다.
MySQL 5.6 버전에서의 옵티마이저에 개선 사항 중 하나로써 Index Condition Pushdown과 함께 Multi Range Read 기능이 도입되었습니다. 그래서 아래 테스트 진행 시 조회되는 건수에 따라서 MRR 동작 대신 Index Condition Pushdown 이 동작될 수도 있습니다
(mrr_cost_based=on 이기 때문에 mrr 사용시 비용을 분석을 하게 됩니다.)
파라미터는 on 이 default 입니다.
# optimizer_switch
set optimizer_switch = 'mrr=on'; // default
set optimizer_switch = 'mrr=off';
# 버퍼 사이즈 설정
set read_rnd_buffer_size = xxxx ;
3-1 테스트 데이터 생성
포스팅에서 사용할 테스트 테이블 및 데이터 생성을 하도록 하겠습니다. 위에서 생성한 테이블을 이용하여 사용하도록 하겠습니다.
-- 테스트를 위해 데이터 증가 mysql> insert into tb_test1 select * from tb_test1 union all select * from tb_test1 union all select * from tb_test1 union all select * from tb_test1 union all select * from tb_test1; -- 4회 추가 수행 mysql> select count(*) from tb_test1; 12960000 -- 인덱스 생성 alter table tb_test1 add index idx1 (col1);
3-2 플랜 확인 및 테스트
mrr 플랜 확인 및 수행속도 차이 등에 대해서 확인해보도록 하겠습니다 mrr 에 대한 비용 추정은 너무 비관적입니다. Cost가 높게 산정되어 mrr 기능을 수행하기 위해서 파라미터를 조정하면서 테스트를 하겠습니다.
3-2-1 Plan 확인
TEST1 은 MRR 을 유도 하기위해서 파라미터를 설정 후 Plan 을 확인하였으며, TEST2 다시 index condition pushdown 으로 수행되도록 파라미터를 설정하였습니다.
-- TEST1 mysql> set optimizer_switch='index_condition_pushdown=off'; mysql> set optimizer_switch='mrr=on'; mysql> set optimizer_switch='mrr_cost_based=off'; mysql> explain select * from tb_test1 force index(idx1) where col1 between 'col1-1' and 'col1-500'; +----+-------------+----------+-------+---------------+------+---------+------+---------+----------+------------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+----------+-------+---------------+------+---------+------+---------+----------+------------------------+ | 1 | SIMPLE | tb_test1 | range | idx1 | idx1 | 403 | NULL | 6485928 | 100.00 | Using where; Using MRR | +----+-------------+----------+-------+---------------+------+---------+------+---------+----------+------------------------+ -- TEST2 mysql> set optimizer_switch='index_condition_pushdown=on'; mysql> set optimizer_switch='mrr_cost_based=on'; mysql> set optimizer_switch='mrr=off'; mysql> explain select * from tb_test1 force index(idx1) where col1 between 'col1-1' and 'col1-500'; +----+-------------+----------+-------+---------------+------+---------+------+---------+----------+-----------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+----------+-------+---------------+------+---------+------+---------+----------+-----------------------+ | 1 | SIMPLE | tb_test1 | range | idx1 | idx1 | 403 | NULL | 6485928 | 100.00 | Using index condition | +----+-------------+----------+-------+---------------+------+---------+------+---------+----------+-----------------------+
3-2-2 실행 결과
read_rnd_buffer_size 사이즈를 1M, 16M 그리고 index condition pushdown 으로 수행 3가지에 대해서 확인해보도록 하겠습니다.
-- 출력 결과를 /dev/null 로 보냄 pager > /dev/null PAGER set to '> /dev/null' -- read_rnd_buffer_size 1M 로 설정 mysql> set read_rnd_buffer_size = 1048576; mysql> set optimizer_switch='index_condition_pushdown=off'; mysql> set optimizer_switch='mrr=on'; mysql> set optimizer_switch='mrr_cost_based=off'; mysql> select * from tb_test1 force index(idx1) where col1 between 'col1-1' and 'col1-500'; 5764608 rows in set (37.06 sec) <--- -- read_rnd_buffer_size 16M 로 상향 조정 mysql> set read_rnd_buffer_size = 16777216; mysql> set optimizer_switch='index_condition_pushdown=off'; mysql> set optimizer_switch='mrr=on'; mysql> set optimizer_switch='mrr_cost_based=off'; mysql> select * from tb_test1 force index(idx1) where col1 between 'col1-1' and 'col1-500'; 5764608 rows in set (30.86 sec) <--- -- index_condition_pushdown 기능 활성화 및 mrr 기능 off mysql> set optimizer_switch='index_condition_pushdown=on'; mysql> set optimizer_switch='mrr_cost_based=on'; mysql> set optimizer_switch='mrr=off'; mysql> select * from tb_test1 force index(idx1) where col1 between 'col1-1' and 'col1-500'; 5764608 rows in set (52.23 sec) <--- -- optimizer_switch 기본값으로 변경(원복) mysql> SET optimizer_switch=default; -- pager 설정 원복 mysql> pager Default pager wasn't set, using stdout.
이와 같이 넓은 범위의 index range scan 에 대한 상황으로 테스트를 진행해 본 결과 Multi Range Read(MRR) 기능은 보조 인덱스(Non-Clustered Index) 에서의 넓은 범위의 range scan 에 대해서 도움이 될 수 있는 부분을 확인하였습니다.
Multi Range Read(MRR) 를 확인해본 이유는 그 다음에 언급할 Batched key Access(BKA) 조인 알고리즘에서 Multi Range Read(MRR) 기능을 사용하고 있기 때문입니다.
4. Batched Key Access Joins
Batched Key Access Joins(BKA) 는 MySQL 5.6 에서 새롭게 추가된 조인 알고리즘 있습니다. 위에서 언급한 것 처럼 Batched Key Access(BKA) 조인 알고리즘이 Multi Range Read(MRR) 기능을 사용하고 있습니다.
그래서 Multi Range Read(MRR) 기능과 Batched Key Access(BKA) 에 대한 다이어그램은 아래와 같습니다.
일반적인 Nested Loop 조인(NLJ) 의 경우 Driving Table(선행 테이블)에서 조회되는 값으로 조인되는 Driven Table(Inner 테이블, 후행 테이블) 을 접근하게 되며 조인시 데이터 저장 순서대로 조회를 하는 것이 아니기 때문에 랜덤 액세스, 랜덤 I/O가 발생되게 됩니다.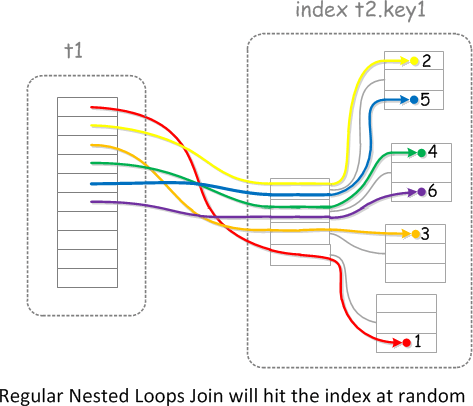
그래서 MySQL 5.6 버전에서 도입된 Batched Key Access(BKA)는 Nested Loop 조인(NLJ)의 Random I/O 발생을 줄이기 위해 Multi Range Read(MRR) 기능을 사용하게 됩니다.
4-1 Batched Key Access Joins 실행 요약
먼저 읽게 되는 Driving Table(선행 테이블) 에서 조회되는 값들을 먼저 조인 버퍼(join_buffer_size)를 채우게 됩니다.
버퍼가 채워지면 BKA 알고리즘은 버퍼의 모든 행에 대해 조인할 Driven Table(Inner 테이블, 후행 테이블)에 액세스하기 위한 키(rowid(primary key))를 빌드 하게 됩니다.
빌드 된 키는 MRR 인터페이스를 사용하여 연산을 하게 되고 MRR 엔진 기능은 최적의 방식으로 인덱스에서 조회를 수행하여 키에서 찾은 Driven Table(Inner 테이블, 후행 테이블)의 행을 가져오게 되고 됩니다.
가져온 일치하는 행을 조인 버퍼의 레코드 와 연결하여 맞는지 확인하여 최종적으로 결과값으로 출력하게 됩니다.
4-2 플랜 확인 및 테스트
BKA 조인 알고리즘의 플랜 확인 및 실행 테스트를 진행하도록 하겠습니다. 먼저 5.7버전 기준으로 optimizer_switch default 값을 아래와 같습니다.
-- default optimizer_switch 조회
mysql> show variables like 'optimizer_switch'\G
*************************** 1. row ***************************
Variable_name: optimizer_switch
Value: index_merge=on,index_merge_union=on,
index_merge_sort_union=on,index_merge_intersection=on,
engine_condition_pushdown=on,index_condition_pushdown=on,
mrr=on,mrr_cost_based=on,
block_nested_loop=on,batched_key_access=off,
materialization=on,semijoin=on,
loosescan=on,firstmatch=on,duplicateweedout=on,
subquery_materialization_cost_based=on,
use_index_extensions=on,condition_fanout_filter=on,
derived_merge=on,prefer_ordering_index=on
batched_key_access 의 default 는 off 입니다 사용을 위해서는 on 으로 변경이 필요 하며 이전 테스트와 마찬가지로 mrr_cost_based 는 off 로 설정하고 진행하도록 하겠습니다
4-2-1 플랜 확인
테스트는 이전에 사용하였던 테이블을 다시 사용하겠으며 인덱스 1개만 추가로 생성해서 사용하도록 하겠습니다. optimizer_switch=default 일 경우와 BKA 조인 사용시로 나눠서 확인하도록 하겠습니다.
-- 인덱스 생성 alter table tb_test1 add index idx2 (no); -- 먼저 optimizer_switch=default 일 경우 플랜 mysql> set optimizer_switch=default; mysql> explain select * from tb_test2 a INNER JOIN tb_test1 b ON a.no=b.no and b.no between 1 and 50000; +----+-------------+-------+------------+------+---------------+------+---------+--------------+-------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+------+---------+--------------+-------+----------+-------------+ | 1 | SIMPLE | a | NULL | ALL | NULL | NULL | NULL | NULL | 10278 | 100.00 | Using where | | 1 | SIMPLE | b | NULL | ref | idx2 | idx2 | 9 | test_db.a.no | 1267 | 100.00 | NULL | +----+-------------+-------+------------+------+---------------+------+---------+--------------+-------+----------+-------------+ -- batched_key_access=on 으로 설정 후 플랜 mysql> SET optimizer_switch='mrr_cost_based=off,batched_key_access=on'; mysql> SET join_buffer_size=16777216; mysql> explain select * from tb_test2 a INNER JOIN tb_test1 b ON a.no=b.no and b.no between 1 and 50000; +----+-------------+-------+------+---------------+------+---------+--------------+-------+----------+----------------------------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------+---------------+------+---------+--------------+-------+----------+----------------------------------------+ | 1 | SIMPLE | a | ALL | NULL | NULL | NULL | NULL | 10278 | 100.00 | Using where | | 1 | SIMPLE | b | ref | idx2 | idx2 | 9 | test_db.a.no | 1267 | 100.00 | Using join buffer (Batched Key Access) | +----+-------------+-------+------+---------------+------+---------+--------------+-------+----------+----------------------------------------+
4-2-2 실행 확인
-- 출력 결과를 /dev/null 로 보냄 mysql> pager > /dev/null PAGER set to '> /dev/null' -- batched_key_access = on, 활성화일 경우 mysql> SET optimizer_switch='mrr_cost_based=off,batched_key_access=on'; mysql> SET join_buffer_size=16777216; mysql> select * from tb_test2 a INNER JOIN tb_test1 b ON a.no=b.no and b.no between 1 and 50000; 12960000 rows in set (2 min 38.10 sec) <--- optimizer_switch 기본값으로 변경(원복) mysql> SET optimizer_switch=default; select * from tb_test2 a INNER JOIN tb_test1 b ON a.no=b.no and b.no between 1 and 50000; 12960000 rows in set (3 min 28.88 sec) <---
여기까지 Block Nested-Loop Join, Multi Range Read(MRR), Batched Key Access Joins 에 대해서 확인해보았습니다. Nested Loop Join 에서 조금이라도 개선된 성능을 필요로 한다면 이와 같은 알고리즘을 적절히 유도해서 사용해보는 것도 도움이 될 거라 생각이 됩니다.
이 포스팅은 MySQL 8.0 의 Hash Join 에서 BNL 과 BKA 에 대해서 간략하게 언급된 내용이 있어서 그 부분의 내용을 풀어보고자 작성하게 되었습니다. 그러면 동일한 쿼리에 대해서 8.0 의 Hash Join 을 이용하게 된다면 얼만큼의 차이를 보이게 되는지도 확인해보았습니다.
MySQL 8.0(8.0.23) 의 default optimizer_switch 값 입니다.
mysql> show variables like 'optimizer_switch'\G
*************************** 1. row ***************************
Variable_name: optimizer_switch
Value: index_merge=on,index_merge_union=on,
index_merge_sort_union=on,
index_merge_intersection=on,engine_condition_pushdown=on,
index_condition_pushdown=on,mrr=on,
mrr_cost_based=on,
block_nested_loop=on, <--
batched_key_access=off,materialization=on,
semijoin=on,loosescan=on,
firstmatch=on,duplicateweedout=on,
subquery_materialization_cost_based=on,
use_index_extensions=on,condition_fanout_filter=on,
derived_merge=on,use_invisible_indexes=off,skip_scan=on,
hash_join=on, <--
subquery_to_derived=off,
prefer_ordering_index=on,
hypergraph_optimizer=off,
derived_condition_pushdown=on
위에서 테스트한 테이블 2개를 MySQL 8.0 으로 그대로 dump 하여 사용하였으며 먼저 Plan 부터 확인해보면, hash join 으로 수행하기 위해서 ignore index 힌트를 사용하였습니다.
mysql> EXPLAIN FORMAT=TREE
select *
from tb_test2 a INNER JOIN tb_test1 b IGNORE INDEX (idx2)
ON a.no=b.no
and b.no between 1 and 50000\G
*************************** 1. row ***************************
EXPLAIN: -> Inner hash join (b.`no` = a.`no`) (cost=12660796546.06 rows=487889)
-> Table scan on b (cost=5542.07 rows=12562474)
-> Hash
-> Filter: (a.`no` between 1 and 50000) (cost=1027.65 rows=10034)
-> Table scan on a (cost=1027.65 rows=10034)
실제로 수행을 하게 되면 아래와 같은 결과로 확인되었습니다.
-- 출력 결과를 /dev/null 로 보냄 mysql> pager > /dev/null PAGER set to '> /dev/null' -- 쿼리 실행 : hash join 으로 수행됨 mysql> select * from tb_test2 a INNER JOIN tb_test1 b IGNORE INDEX (idx2) ON a.no=b.no and b.no between 1 and 50000; 12960000 rows in set (18.38 sec)
수행하는데 약 18초 가량 소요되었습니다. 위에서 BKA 로 수행하는데 2분 38초가 소요된 것에 비해 상당한 차이가 나는 것을 확인할 수 있습니다. MySQL8.0 에서 Hash Join 이 추가되면서 대량의 데이터를 핸들링 하는데 더 수월하게 되었음을 확인할 수 있습니다.
5. Reference
Reference Link
dev.mysql.com/mrr-optimization.html [Link]
runebook.dev/multi-range-read-optimization [Link]
https://blog.naver.com/seuis398/70159183472 [Link]
https://blog.naver.com/parkjy76/221069454499 [Link]
https://gywn.net/2012/07/improve-mariadb-mysql [Link]
관련된 다른 글




Principal DBA(MySQL, AWS Aurora, Oracle)
핀테크 서비스인 핀다에서 데이터베이스를 운영하고 있어요(at finda.co.kr)
Previous - 당근마켓, 위메프, Oracle Korea ACS / Fedora Kor UserGroup 운영중
Database 외에도 NoSQL , Linux , Python, Cloud, Http/PHP CGI 등에도 관심이 있습니다
purityboy83@gmail.com / admin@hoing.io
