







Last Updated on 3월 25, 2022 by Jade(정현호)
안녕하세요
이번 포스팅에서는 Orchestrator 의 Refactoring, 장애 감지(Failure Detection), Recovery 에 대해서 알아 보도록 하겠습니다.
Orchestrator 에 연재 글로 아래 이전 포스팅에서 연결되는 글 입니다
Contents
Topology Refactoring
Orchestrator 기능 중에서 Refactoring(리팩토링) 기능에 대해서 확인 해보도록 하겠습니다.
Clusters -> Dashboard 를 이동 하면 구성된 복제 토폴로지를 확인 할 수 있습니다.
구성된 MySQL 의 복제 구성 설정의 변경 없이 복제 대상의 Master 서버의 변경이나 Master<->Slave 간의 relocate(takeover)가 가능 합니다.

[orchestrator/pseudo-gtid.md]
리팩토링이나 Failover 실행시 GTID 사용하거나 또는 binlog pos 사용시에는 pseudo-gtid 설정이 필요 합니다.
포스팅에서는 binlog pos 방식의 복제 구성이 되어 있어서 pseudo-gtid 사용이 설정된 상태 입니다.
"AutoPseudoGTID": true
Slave Refactoring
Slave 간의 복제 토폴로지에 대한 리팩토링을 해보도록 하겠습니다.
아래는 포스팅 환경에서의 복제 토폴로지 상태 입니다.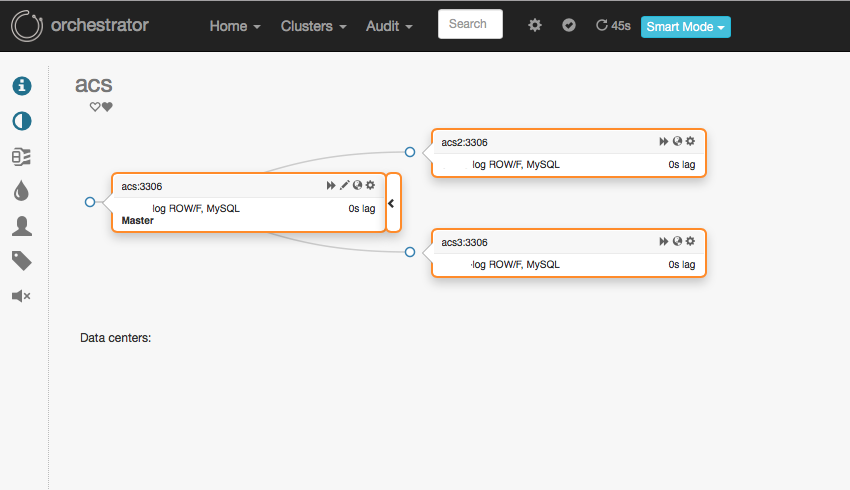
2개의 Slave 중에 1개 노드에서 다른 쪽 노드로 Drag&Drop 을 아래와 같이 진행을 하게 되면 relocate 되는 표시가 보이게 됩니다.
Master 노드에서 Drag 할때 클릭하는 위치에 따라서 다른 행동이 발생되게 됩니다.
Master 에서 이와 같이 Drag 할 경우 경우 아래 이미지와 같이 1 번 표시를 클릭 하여 오른쪽으로 슬라이드 확장 되는 창을(그림에서 2) 클릭 하여 Drag 해야 합니다.![]()
Slave 에서 Master 쪽으로 Drag 시 별도의 슬라이드 확장 창이 없어서 Slave 윈도우를 클릭 후 Drag 하면 됩니다.
변경되는 relocate 에 대한 팝업이 되고 acs node(master) 를 바라 보고 있는 acs3 node 가 acs2 node 로 변경된 다는 내용입니다.
OK 를 클릭 하면 토폴로지 리팩토링이 실행됩니다.![]()
위에서의 리팩토링을 실행한 내용과 같이 replication 구성이 변경 되었습니다.![]()
replication 상태를 조회를 해보면 아래와 토폴로지 정보와 같이 복제 정보가 변경된 것을 확인 할 수 있습니다.
mysql> show slave statusG
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: acs2
Master_User: repl_user
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: binlog-acs2.000004
Read_Master_Log_Pos: 11459153
Relay_Log_File: relay_log.000002
Relay_Log_Pos: 1142
Relay_Master_Log_File: binlog-acs2.000004
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
< ...중략... >
원복을 위해서는 다시 acs3 노드를 acs 노드로 Drag 를 하면 다시 relocate 가능 함을 확인 할 수 있습니다.![]()
Drop 을 하게 되면 relocate 정보 팝업이 되며, relocate 를 하기 위해서 내용을 확인 후 OK 를 클릭 합니다.![]()
다시 원래 대로의 복제 토폴로지로 변경된 것을 확인 할 수 있습니다.
Master Refactoring(Promote)
현재 구성 중인 복제 토폴로지 상태 입니다
Master <-> Slave 간의 TakeOver 를 하기 위해서는 Slave 윈도우를 Drag 를 하여 승격(Promote) 할 수 있습니다.
Drag&Drop 하는 위치에 따라서 relocate 와 promote 기능이 달라 집니다.
아래와 같은 위치에서는 relocate 가 되게 됩니다. ![]()
아래와 같은 위치로 이동 시키면 "Promote as Master" 메세지가 확인 되며, 해당 메세지가 확인 될 때 Slave Promote(승격) 가 가능 합니다.(Master <-> Slave)![]()
승격(Promote) 실행 시 아래와 같이 경고 팝업이 보이게 됩니다, OK 버튼을 클릭 하면 Graceful Master Takeover 가 실행 됩니다![]()
Promote 되면 실행한 Slave 노드가 Master 로 승격되고, 기존의 Master 노드가 Slave 가 되면서 빨간색 으로 표기 됩니다.![]()
마스터 승격 실행 후 아래와 같이 토폴로지 정보가 조금 틀려지게 표기되는 경우가 있습니다.
이런 경우 메뉴 -> Clusters -> Dashboard 를 통해서 몇 번 더 페이지를 들어가면(즉 페이지 Refresh) 토폴로지를 다시 로딩 하면서 정상적으로 표기가 됩니다![]()
토폴로지에서 기존 마스터(Slave 로 변경된) 노드를 클릭 하고 아래와 같이 컨트롤 메뉴에서 "Start replication" 를 클릭 하면 Slave 노드로 복제가 시작 됩니다.![]()
[참고] MySQL 에서 master_info_repository = 'TABLE' 를 설정하지 않을 때 Master 계정 정보관련하여 에러가 발생하게 됩니다.
master_info_repository = 'TABLE' 설정이 필요 합니다.
또한 설정 이후 Orchestrator 에서 접속하는 DB계정에 대해서도 권한이 부여가 되어야 합니다.
포스팅에서는 orchestrator 이름으로 계정을 사용 중입니다.
mysql> GRANT SELECT ON mysql.slave_master_info TO 'orchestrator'@'%';
![]()
정상 적으로 Replication 이 시작 되었다면 아래와 같이 true 로 확인 되게 됩니다.![]()
토폴로지 상황에서도 복제 시작이 완료 되면 정상 토폴로지 화면이 확인 됩니다. 이전의 Master node 였던 호스트를 다시 마스터 로 승격시키기 위해서는 위의 과정을 동일하게 진행 하면 됩니다.![]()
[참고] 복제 지연 발생시 : Promote 후 Master 에서 Slave 로 복귀 하거나 사용하는 과정에서 복제 지연 발생시, 토폴로지에서 경보가 확인 됩니다.![]()
구성 설정 화면에서 Refresh 를 하면 Replication Gap 의 변경 내역을 모니터링 할 수 있습니다.![]()
co-master Refactoring
Orchestrator 의 리팩토링 중에서 co-master 로의 변경도 있습니다. 해당 기능은 MySQL MMM 의 Active-Passive 또는 Active-Standby 형태로 Multi Master Replication 으로 구성이 변경됩니다.

[https://mysql-mmm.org/mysql-mmm.html]
co-master 리팩토링을 실행 하기 위해서는 아래와 같이 마스터 노드의 윈도우를 Drag 하여 Second Master 노드로 만들려는 Slave 노드로 Drop 해야 합니다. Slave 로 Drag 하면 "MAKE CO MASTER" 라고 표기 됩니다.![]()
팝업 메세지 확인 후 OK 를 클릭 하면 리팩토링이 실행 됩니다.![]()
실행이 완료 되면 아래와 같은 모양의 토폴로지로 변경되게 됩니다. Master(포스팅에서는 acs 노드) 를 대상으로 복제가 수행되는 형태는 동일 하지만 Master 노드에서 변경이 발생되게 됩니다.![]()
마스터(acs node)에서 조회한 내용과 같이 Master 노드가 Slave Node(acs2) 를 대상으로 Replication 이 되고 있는 것을 확인 할 수 있습니다.
mysql> select @@hostname;
+------------+
| @@hostname |
+------------+
| acs |
+------------+
mysql> show slave statusG
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: acs2
Master_User: repl_user
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: binlog-acs2.000004
Read_Master_Log_Pos: 26392338
Relay_Log_File: relay_log.000002
Relay_Log_Pos: 322
Relay_Master_Log_File: binlog-acs2.000004
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
< ... 중략 ....>
그래서 Multi Master 구조의 형태로 변경이 된 상태가 됩니다.
MySQL acs2 노드를 클릭하여 설정 및 상세 내역을 보면 Replication running = true 로 복제가 수행중임을 알 수 잇으며, Read Only 의 경우 true 로 아직 Read-Only 상태로 확인되고 있습니다.![]()
다시 원복하기 위해서는 마스터 노드(acs) 를 클릭하여 설정 화면으로 이동 합니다.
인스턴스 설정 창에서 "Reset replica" 를 클릭 하면 Slave Node(acs2) 를 바라보면 Master Node 가 이전 과 같이 변경 되게 됩니다.![]()
장애조치 - Failover
마스터 노드(인스턴스) 의 장애 상황시 진행에 대해서 확인 해보도록 하겠습니다.
Failure Detection
현재 토폴로지 구성 상태 입니다.
이 상태에서 Master DB 인스턴스를 종료 해보도록 하겠습니다.
~]# systemctl stop mysqld ~]# ps -ef| grep mysqld | grep -v grep ~]#
장애를 발생 시킨 후 Clusters-> Dashboard 로 이동하게 되면 정상적 장애 감지(Failure Detection)가 된 것을 확인 할 수 있습니다.
토폴로지 상태에서 아래와 같이 3 / 1 / 2 로 표기 된 내역을 볼 수 있습니다.
1개 Replica Set(복제셋) 이 3개의 인스턴스로 구성되어 있으며, 3개중 1개(검은색)가 문제가 있고, 2개의 Slave 는 붉은 색으로 Replication 불가 상태를 나타 냅니다. 그 아래는 정상인 상태의 토폴로지의 상태 예시 입니다.![]()
노드 Set 별 토폴로지 화면 으로 이동하면 아래와 같이 우측에 !(느낌표) 버튼을 클릭하여 각 노드 별 에러 내역을 확인할 수 있습니다![]()
또한 conf.json 에서 설정한 경로와 파일명에서도 Failure 가 감지됩니다
~]# cd /usr/local/orchestrator/log ~]# tail recovery.log Detected DeadMaster on acs:3306. Affected replicas: 2
* 포스팅에서는 경로를 변경하여 진행하였습니다 기본 경로 및 파일명은 /tmp/recovery.log 입니다.
* 파일에는 계획하여 별도로 실행한 리팩토링 작업에 대한 내용도 기록이 됩니다.
Manual Recovery(Failover)
위에서 장애가 발생된 내역에 대해서 장애 조치인 Recovery(Failover) 를 실행해야 합니다.
MySQL Orchestrator 에서의 기본 설정은 Manual Recovery(Failover) 입니다 즉 사용자가 장애에 대해서 확인 후 특정 Slave 노드를 선택하여 승격(Promote) 진행하여 장애 처리(Failover) 를 진행 해야 합니다.
토폴로지 에서 장애가 감지된 마스터 노드는 Recover 라는 Select Box 가 보이게 됩니다. "Recover" 를 클릭하면 승격할 Slave 노드를 선택 할 수 있습니다.![]()
포스팅에서는 acs2 노드를 승격 하였으며 승격 후 아래와 같이 acs2 와 acs3 노드가 묶여 있으며 장애가 발생된 acs 노드(이전의 마스터 인스턴스) 는 별도로 분리 되어 있는 것을 확인 할 수 있습니다.![]()
acs2 인스턴스가 Master 로 승격된 상태로 1개의 Slave 인스턴스(acs3 인스턴스) 로 구성된 Replica Set 이 된 상태 입니다.![]()
다운된(장애가 발생된) acs 노드의 MySQL 을 시작(기동) 을 하도록 하겠습니다(복구되었다는 시나리오)
~]# systemctl start mysqld
acs2 , acs3 노드로 구성된 복제 Set 에 추가 하기 위하여 acs 노드 인스턴스에서 change master 를 실행 하도록 하겠습니다.
포스팅에서는 GTID 를 사용하지 않고 binlog pos 방식을 사용하고 있습니다. binlog pos 과 파일명 없이 change master 로 복제 구성시 여러 Replication 에러가 발생하게 됩니다
테이블 존재, 데이터 중복, 데이터 삭제시 데이터 없음, 테이블 없음 등등 ..
이런 경우는 여러 방법을 통해서 사용해야할 binlog pos 과 파일을 알아 낼수 있으며 포스팅에서는 3가지 방법에 대해서 언급하도록 하겠습니다.
확인되는 binlog pos 와 파일명을 통해서 장애가 발생되어 복제에서 제외된 인스턴스를 다시 복제 Set 에 추가하도록 하겠습니다.
먼저 acs3 인스턴스에 접속하여 확인할 수 있습니다.
1) Slave 인스턴스인 acs3 접속하여 mysql.slave_master_info 조회하여 확인 할 수 있습니다.
mysql> select *
from mysql.slave_master_info\G
*************************** 1. row ***************************
Number_of_lines: 25
Master_log_name: binlog-acs2.000004 <------
Master_log_pos: 26637928 <------
Host: acs2
User_name: repl_user
User_password: repl_user
Port: 3306
Connect_retry: 60
Enabled_ssl: 0
< ... 중략 ... >
2) 또는 mysqld 로그를 통해서도 확인 할 수 있습니다.
~]# grep "initialized, starting replication" mysqld.err | tail -1 [Note] Slave SQL thread for channel '' initialized, starting replication in log 'binlog-acs2.000004' at position 26637928, <---------------- relay log '/usr/local/mysql/data/relay_log.000001' position: 4
* 가로 길이가 길어서 개행 되어 있습니다.
3) Orchestrator 웹 콘솔에도 확인 할 수 있습니다.
메뉴 -> Audit -> Recovery 로 이동 합니다.![]()
발생한 장애 복구(Recovery) 와 연관된 기록을 찾아서 DeadMaster 를 클릭 합니다![]()
저장된 Audit 기록을 통해서도 Binlog pos 과 파일명을 확인 할 수 있습니다.![]()
위의 방법 등에서 확인한 정보를 통해 acs(장애 복구된 인스턴스) 노드에서 change master 를 실행 하면 됩니다.
mysql> CHANGE MASTER TO MASTER_HOST='acs2', MASTER_PORT=3306, MASTER_USER='repl_user', MASTER_PASSWORD='repl_user', MASTER_LOG_FILE='binlog-acs2.000004', MASTER_LOG_POS=26637928; mysql> start slave;
복제 구성이 정상적으로 이루어졌다면 토폴로지에도 반영되어 아래와 같이 Slave 인스턴스로 추가 된 것을 확인 할 수 있습니다.![]()
Slave 로 추가된 acs 노드 인스턴스를 Master 로 변경하기 위해서는 위에서 진행한 Master Refactoring(Promote) 내용을 참조하시면 됩니다.
Automated Recovery(Failover)
Automated Recovery 실행 될 때 승격이 되는 노드를 전부(*) 또는 특정 1개 노드(인스턴스) 를 지정할 수 있습니다.
conf.json 에서 설정하지 않으면 Recovery 는 Manual Recovery 가 기본(Default) 입니다. 일부 파라미터의 수정이 필요 하며 일부 4가지 파라미터에 대해서 내용을 먼저 확인 해보도록 하겠습니다.
• RecoverMasterClusterFilters
Master 장애 대해서 자동 복구할 클러스터 를 지정하는 옵션 입니다.
예를 들어 "thiscluster","thatcluster" 와 같이 기술되어 있다면 여러 클러스터(Replica Set) 에서 지정된 2개 thiscluster 와 thatcluster 에 대해서만 자동 Master 장애 복구가 실행 됩니다.
클러스터명을 명시적으로 입력 할 수 있으며 정규식 패턴으로도 입력 가능 합니다.
"RecoverMasterClusterFilters": [
"myoltp", // cluster name includes this string
"meta[0-9]+", // cluster name matches this regex
"alias=olap", // cluster alias is exactly "olap"
"alias~=shard[0-9]+" // cluster alias matches this pattern
]
• RecoverIntermediateMasterClusterFilters
해당 파라미터는 복제 구성에서 중간 Master 에 대한 복구 여부를 설정하는 파라미터 입니다.
• PromotionIgnoreHostnameFilters
Slave 노드 중에서 Master 로 Promote(승격) 대상에서 제외 할 Hostname(노드) 를 입력 합니다.
RecoverMasterClusterFilters 와 동일하게 정규식 을 사용하여 패턴으로 입력 할 수 도 있습니다.
입력 하지 않으면 가용한 Slave 노드 중에서 승격되게 됩니다.
• RecoveryPeriodBlockSeconds
장애가 발생 후 자동 복구가 되면 위의 파라미터에 지정한 시간 동안은 자동 복구를 차단 하게 됩니다 Default 3600 (초) 입니다
이 것은 플랩 방지 메커니즘 이라고 합니다(This is an anti-flapping mechanism.)
한번 장애가 발생 되어서 자동 복구가 수행 된다면 3600초 안에는 장애가 발생 되어도 자동 복구가 수행되지 않음을 의미 합니다.
해당 시간은 운영 정책에 따라서 더 짧게 변경하는 것을 고려 해 볼 수 있을 것 같습니다
포스팅에서는 테스트 등을 위해서 해당 시간을 조정(짧게) 하여 설정 하였습니다.
Automated Recvery 가 동작하기 위해서 conf.json 을 파일을 수정 하도록 하겠습니다.
~]# cd /usr/local/orchestrator
~]# cp -rp orchestrator.conf.json cp orchestrator.conf.json.back
~]# vi orchestrator.conf.json
### 파일 변경 내역 ###
(1) 변경 없음
"PromotionIgnoreHostnameFilters": [],
(2) 3600 -> 10
"RecoveryPeriodBlockSeconds": 10,
(3) _master_pattern_ -> *
"RecoverMasterClusterFilters": [
"*"
],
(4) _intermediate_master_pattern_ -> *
"RecoverIntermediateMasterClusterFilters": [
"*"
],
포스팅에서는 먼저 PromotionIgnoreHostnameFilters 는 변경하지 않고 나머지 3개 파라미터만 변경 하였습니다.
변경 후 Home -> Status -> Reload configuration 을 클릭하여 변경한 configuration 을 재 적용을 합니다.![]()
아래 이미지는 지금 복제 구성의 토포롤지 상황 입니다
(이전 acs 노드와 acs2 간의 relocate 하였습니다)
마스터 DB 인스턴스를 중지 하도록 하겠습니다(장애 발생)
~]# systemctl stop mysqld ~]# ps -ef| grep mysqld | grep -v grep ~]#
마스터 DB 인스턴스가 장애가 감지가 되면 자동으로 Recovery(Failover) 가 실행 됩니다.
- 로그 내역
Detected UnreachableMaster on acs:3306. Affected replicas: 2 Detected DeadMaster on acs:3306. Affected replicas: 2 Will recover from DeadMaster on acs:3306 Recovered from DeadMaster on acs:3306. Failed: acs:3306; Promoted: acs2:3306 (for all types) Recovered from DeadMaster on acs:3306. Failed: acs:3306; Successor: acs2:3306
Clusters -> Dashboard 로 이동 하면 Automated Recovery 가 완료 되어 Master(acs 노드, 호스트) 는 분리가 된 상태이고, acs2 는 승격이 완료 된 상태이고 acs3 는 acs2(새로운 마스터) 호스트를 대상으로 복구 구성이 완료 된 상태를 확인 할 수 있습니다.
Automated Recovery 가 설정 되면 Dashboard 에서는 하트 표시가 되게 됩니다.![]()
acs2 는 마스터로 승격이 완료 되었고, acs3 는 새로운 복제 구성이 된 상태 입니다.![]()
기존의 Master 서버(acs 호스트) 의 장애 복구가 완료 되면 이전의 방법 과 같이 복제 설정(change master) 을 하면 됩니다.
change master 를 해서 복제 slave 구성이 완료 되면 아래 와 같이 복제 토폴로지가 다시 구성이 완료 됩니다.![]()
이번에는 PromotionIgnoreHostnameFilters 를 설정하여 장애 복구를 시도 해보도록 하겠습니다.
conf.json 파일에 아래와 같이 설정하였고 Reload Configuration 을 실행 하였습니다.
"PromotionIgnoreHostnameFilters": ["acs2"],
conf.json 파일 수정 및 Reload Configuration 을 실행 하였다면 다시 master 인스턴스를 다운(장애 발생)을 하도록 하겠습니다.
~]# systemctl stop mysqld ~]# ps -ef| grep mysqld | grep -v grep ~]#
위에서 설정한 것 처럼 acs2 호스트가 아니라 다른 Slave 노드인 acs3 노드에서 승격(Promote) 가 된 것을 확인 할 수 있습니다.![]()
Ignore Filters 사용시 주의사항
위에서 Promotion 대상 제외에 대한 설정인 PromotionIgnoreHostnameFilters 파라미터에 acs2 호스트를 지정하여 설정 하였고 그에 따라 Master 인스턴스 장애 발생시 Master 로 acs3 호스트가 승격된 상태 입니다.
이 상태에서 acs2 <-> acs3 노드 간에 takeover(promote) 를 실행 보도록 하겠습니다.
아래 이미지와 같이 Drag 하여 Promote as Master 를 수행 합니다.![]()
팝업 되는 메세지에서 OK 를 클릭 합니다.![]()
acs2 호스트를 승격 시키기 위해서 Promote 를 실행하면 아래와 같이 에러가 발생되게 됩니다.
PromotionIgnoreHostnameFilters 룰에 설정되어 있기 때문에 불가능 한 것 입니다.![]()
그럼 이번에는 Master 인 acs3 인스터스를 다운해서 failover(Recovery) 를 진행 해보도록 하겠습니다.
~]# systemctl stop mysqld ~]# ps -ef| grep mysqld | grep -v grep ~]#
장애가 발생되면 Automated Recovery(Failover) 가 진행되지 않고 아래와 같이 acs2(승격이 될 대상 인스턴스) 도 빨간색으로 표시 되면서 문제가 발생되었음을 확인 할 수 있습니다.![]()
로그에서 몇 가지 내용을 확인 할 수 있습니다.
• recovery.log 내역
Detected DeadMaster on acs3:3306. Affected replicas: 1 Will recover from DeadMaster on acs3:3306 < Promote 된다는 내용이 없음 >
• orchestrator.log 내역
INFO topology_recovery: Failure: no replica promoted. INFO auditType:recover-dead-master instance:acs3:3306 cluster:acs3:3306 message:Failure: no replica promoted. INFO topology_recovery: chooseCandidateReplica: no candidate replica found
위에서 설정한 PromotionIgnoreHostnameFilters 파라미터를 다시 원복(설정 호스트 없음) 하여 테스트를 진행 하도록 하겠습니다.
변경 파일 : orchestrator.conf.json
"PromotionIgnoreHostnameFilters": ["acs2"],
아래와 같이 원복 합니다.
"PromotionIgnoreHostnameFilters": [],
그 다음 configuration 파일을 reload 합니다.![]()
위에서 종료한 acs3(마스터) 인스턴스틀 시작하여 정상화 후에 다시 인스턴스를 종료하여 장애 상황을 재현 합니다.
~] systemctl start mysqld <-- 복제 상황 정상화로 만듬 --> <-- 다시 인스턴스 종료 --> ~]# systemctl stop mysqld ~]# ps -ef| grep mysqld | grep -v grep ~]#
마스터인 acs3 인스턴스가 종료(장애 상황) 하면 아래와 같이 3개로 분리된 모습을 확인 할수 있습니다.![]()
호스트를 클릭하면 아래와 같이 슬레이브는 없지만 승격이 완료 되어 마스터로 표기되는 정상 인스턴스 내역을 확인할 수 있습니다.![]()
이와 같이 장애가 다수 발생하여 Failover가 연속적으로 일어나도 Slave 노드가 다수가 존재한다면 PromotionIgnoreHostnameFilters 가 적용 되어도 문제가 없을수도 있습니다
(물론 패턴으로 다수로 지정되어 있다면 위와 같은 상황이 나타날수는 있음)
PromotionIgnoreHostnameFilters 를 사용하여 Slave 노드 중에 백업 인스턴스나나 배치 전용 인스턴스를 지정하여 장애 발생시 승격 대상에서 제외 하는 정책을 수립하는데 사용할 수 있을 것 같습니다
다만 위와 같은 상황, 즉 Promote Candidate Node 가 없는 경우 설정을 변경하기 전까지 Promote 가 제한 된 다는 점은 특이사항임으로 상기를 시킬 필요는 있을 것 같습니다.
Recovery acknowledge
Recovery acknowledge 는 장애 감지 및 복구(Recovery) 이후 복구가 완료 되었음을 승인 또는 확인 하는 과정 입니다.
Recovery acknowledge 를 완료 해야 다시 발생하는 장에 대한 자동 장애 복구가 가능한 상태가 됩니다. 이전에 파라미터에서 언급 된 RecoveryPeriodBlockSeconds 파라미터에서 설정한 시간안에서 복구 가능 여부와 연관되어 있습니다.
자동 복구가 수행되면 RecoveryPeriodBlockSeconds(Default 3600 초) 파라미터에서 설정 한 시간안에서는 다시 자동 복구가 차단 되게 됩니다.
플래핑(연속적인 중단 및 리소스 제거를 야기하는 연쇄 오류) 현상을 방지하기 위해서 입니다.
자동 복구 이후 Recovery acknowledge 를 명시적으로 수행을 하게 되면 자동 복구가 가능하게 됩니다(복구 차단 해제)
메뉴 -> Audit -> Recovery 순으로 이동 합니다. ![]()
Recovery 된 여러 내역이 리스트업 됩니다 그 중에서 Recovery Acknowledge 할 클러스터 내역에서 DeadMaster 를 클릭 합니다. ![]()
그 다음 Audit 내역에서 Acknowledge 버튼을 클릭 합니다.![]()
간단하게 메세지 나 사유를 입력 하고 OK 버튼을 클릭 하면 과정이 완료가 됩니다.![]()
여기 까지 해서 Orchestrator 의 Refactoring, 장애 감지(Failure Detection), Recovery 에 대해서 알아 보았습니다.
다음 포스팅에서는 VIP 사용 관련된 내용을 확인 해보도록 하겠습니다.
이어지는 다음 글
Ref.
github.com/orchestrator/docs
관련된 다른 글






Principal DBA(MySQL, AWS Aurora, Oracle)
핀테크 서비스인 핀다에서 데이터베이스를 운영하고 있어요(at finda.co.kr)
Previous - 당근마켓, 위메프, Oracle Korea ACS / Fedora Kor UserGroup 운영중
Database 외에도 NoSQL , Linux , Python, Cloud, Http/PHP CGI 등에도 관심이 있습니다
purityboy83@gmail.com / admin@hoing.io


mysql 8.0 에서 caching_sha2_password을 사용하는 경우 오류가 발생하여, change replication source to 할 때 옵션으로 get_source_public_key = 1 을 넣어줘야 하는데, orchestrator 에서는 어떻게 해 줘야 하나요?