









Last Updated on 5월 6, 2024 by Jade(정현호)
안녕하세요.
이번 포스팅에서는 카프카 클러스터 설치에 대해서 확인해보려고 합니다.
카프카 연재 글로 아래 포스팅에서 이어지는 글입니다.
구성 환경
• 카프카 버전 : 2.8.2
• 주키퍼 버전 : 3.8.1
• 자바 버전 : 11
• OS : CentOS 7.8 or Rocky Linux 8.6
• OS User: 모든 작업은 root 유저로 진행하였습니다.
포스팅에서는 실제로 3대를 이용한 클러스터 구성과 한 서버에서 데몬3개를 설정과 구동하여 클러스터를 구성한 2가지 방법 모두에 대해서 설명되어 있습니다.
별도의 서버로 구성하는 유형에서는 VM을 통해서 서버 총 3대로 구성하였고 주키퍼 앙상블(Zookeeper Ensemble) 로 구성하기 위해서 3개의 서버에 각각 설치하고, 동일한 서버에 카프카를 설치하였습니다.
아래의 그림과 같이 구성하였습니다.
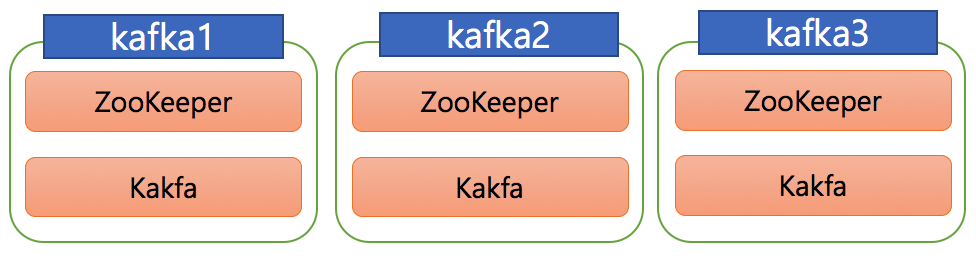
위의 이미지에서의 kafka1, kafka2 , kafka3 는 호스트네임 또는 /etc/hosts 지정한 호스트명을 의미합니다.
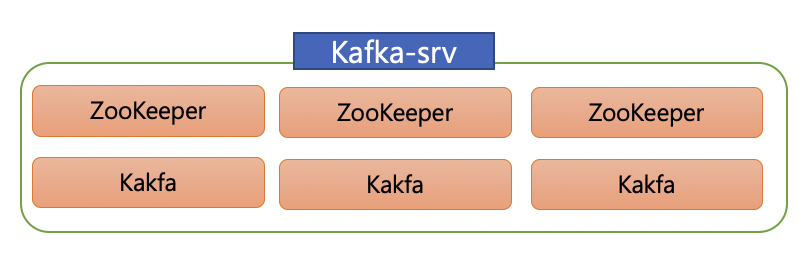
1개의 동일한 서버에서 모두 설치는 아래 이미지와 같이 1개 서버에서 주키퍼3개, 카프카 클러스터 구성(3개) 를 하는 것으로 디렉토리 및 설정 파일 그리고 포트 등을 변경해서 설치를 할 수 있습니다.
OS 환경 설정
카프카와 주키퍼를 설치하기 전에 몇 가지의 OS에서 먼저 설정 과 설치를 진행하도록 하겠습니다.
/etc/hosts 수정
모든 서버에서 아래와 같이 hosts 파일에 내용을 추가합니다
vi /etc/hosts ## 아래와 같은 유형으로 호스트 정보를 입력 192.168.56.51 kafka1 192.168.56.52 kafka2 192.168.56.53 kafka3
1개의 서버 설치하는 환경에서는 /etc/hosts 에서의 호스트 설정은 선택적으로 하시면 됩니다.
vi /etc/hosts 192.168.56.62 kafka-server
Java 설치
포스팅에서는 Java 11 버전을 설치하였습니다(OpenJDK), JDK 패키지를 설치하도록 하겠습니다.
• CentOS7(RHEL7) or OracleLinux7 또는 유사한 RPM 계열
yum makecache yum install java-11-openjdk.x86_64 ca-certificates
• RockyLinux8 or CentOS8 or OracleLinux8
$ sudo dnf install java-11-openjdk java-11-openjdk-devel
그 다음에는 /usr/bin 아래로 심볼릭 링크를 생성하도록 하겠습니다.
java_new_path=`sudo rpm -ql java-11-openjdk-headless | grep bin/java` mv /usr/bin/java /usr/bin/java.ori ln -s $java_new_path /usr/bin/java
그 다음으로 java 버전을 확인 합니다.
/usr/bin/java -version openjdk version "11.0.14.1" 2022-02-08 LTS OpenJDK Runtime Environment 18.9 (build 11.0.14.1+1-LTS) OpenJDK 64-Bit Server VM 18.9 (build 11.0.14.1+1-LTS, mixed mode, sharing)
서버를 분리하여 설치
먼저 서버를 분리하여 설치를 하는 방식으로 설명하도록 하겠으며 포스팅에서는 3개의 서버(VM) 을 사용하였습니다.
주키퍼 설치
카프카에서는 빼놓을 수 없는 부분이 바로 주키퍼(ZooKeeper) 입니다. 주키퍼는 하둡의 서브 프로젝트 중 하나로 출발해 2011년에 아파치의 탑 레벨 프로젝트로 승격되었습니다.
주키퍼는 오늘날에 이르러 카프카를 비롯해 아파치 산하의 프로젝트 인 하둡, 나이파이(NiFi), 에이치베이스(HBase) 등 많은 분산 애플리케이션에서 코디네이터 역할을 하는 애플리케이션으로 사용되고 있습니다.
주키퍼는 여러 대의 서버를 앙상블(Ensemble,클러스터) 로 구성하고, 살아 있는 노드 수가 과반수 이상 유지된다면 지속적인 서비스가 가능한 구조입니다.
따라서 주키퍼는 반드시 홀수로 구성해야 하며, 홀수 구성인 3대로 구성하였습니다. 이것은 3개의 서버에 별도로 설치하는 것과 한 서버에서 설치하는 것 모두 공통 사항입니다.
포스팅에서는 ZooKeeper(주키퍼) 버전은 3.8.1 으로 설치하였습니다.
주키퍼에 대한 더 자세한 내용은 아래 포스팅을 참조하시면 됩니다.
설치 파일 다운로드 및 압축 해제
• 주키퍼 다운로드 페이지

• 직접 다운로드(wget) 및 압축해제
mkdir -p pkg cd pkg wget https://dlcdn.apache.org/zookeeper/zookeeper-3.8.1/apache-zookeeper-3.8.1-bin.tar.gz tar zxvf apache-zookeeper-3.8.1-bin.tar.gz -C /usr/local
설치파일 등의 작업은 pkg 라는 임의의 디렉토리 공간에서 진행하였으며 반드시 해당 디렉토리에서 해야 하는 것은 아닙니다.
설치위치는 /usr/local 아래에 설치를 진행하기 위해서 -C /usr/local 옵션을 사용하였습니다.
심볼릭 링크 설정 및 환경변수 설정
cd /usr/local chown -R root:root apache-zookeeper-3.8.1-bin ln -s apache-zookeeper-3.8.1-bin zookeeper # 환경변수 정보 파일에 입력 echo " export PATH=\$PATH:/usr/local/zookeeper/bin:/usr/local/kafka/bin" | tee -a ~/.bash_profile > /dev/null source ~/.bash_profile
압축을 해제한 다음 생성된 디렉토리에서 짧은 디렉토리 경로인 zookeeper 로 심볼릭 링크를 설정하였고, 주키퍼와 아래에서 설치할 카프카의 디렉토리 경로에 대해서 지금 단계에서 PATH 환경 변수에 추가하였습니다.
주키퍼를 앙상블로 구성하기 위해서는 주키퍼 dataDIR 디렉토리에 고유한 ID 값의 입력이 필요하며 myid 파일에 고유한 숫자를 입력 하면 됩니다.
서버 별로 1,2,3 으로 지정하도록 하겠으며 dataDIR 은 /usr/local/zookeeper/data 으로 사용하였습니다.
아래 내용을 각 서버별로 별도로 수행을 합니다.
## 첫번재 서버에서 mkdir -p /usr/local/zookeeper/data echo 1 > /usr/local/zookeeper/data/myid ## 두번째 서버에서 mkdir -p /usr/local/zookeeper/data echo 2 > /usr/local/zookeeper/data/myid ## 서번째 서버에서 mkdir -p /usr/local/zookeeper/data echo 3 > /usr/local/zookeeper/data/myid
그 다음은 주키퍼 conf 파일을 수정 작성하도록 하겠습니다. 기본적으로 제공되는 sample 파일을 사용도록 하겠습니다
cd /usr/local/zookeeper/conf cp zoo_sample.cfg zoo.cfg vi zoo.cfg
zoo.cfg 파일을 열어 아래와 같이 환경설정을 해줍니다.
## 사용하는 환경에 따라서 디렉토리를 설정 합니다. ## 디렉토리는 생성이 필요할 수 있습니다. dataDir=/usr/local/zookeeper/data ## 포트변경없이 그대로 사용하였습니다. clientPort=2181 ## 주키퍼는 실행하게되면 기본으로 admin server를 기동하는데 8080 port 을 사용합니다. ## 8080 은 여러 애플리케이션(또는 데몬) 에서 사용되는 포트라서 중복이 될수도 있습니다. ## 그래서 포스팅에서는 변경하였습니다. admin.serverPort=8888 ## server.N : 주키퍼를 앙상블로 구성을 위한 설정 으로 server.myid 형식으로 지정합니다. ## 2888:3888은 기본 포트이며, 앙상블 내 노드끼리 연결 및 리더 선출에 사용하는 포트 입니다. ## kafka1 , kafka2, kafka3 은 /etc/hosts 에 설정된 호스트명 입니다. server.1=kafka1:2888:3888 server.2=kafka2:2888:3888 server.3=kafka3:2888:3888
CodeBlock 안의 각 항목별 내용을 참조하시면 됩니다
주키퍼를 시작 과 종료하는 방법은 여러가지가 있을 수 있고, 포스팅에서는 systemd 를 사용하여 사용/중지하는 방법을 사용하였습니다. systemd 에서 사용하기 위해서 service 파일을 먼저 생성하도록 하겠습니다.
파일명은 /etc/systemd/system/zookeeper.service 이며 vi 등의 편집기로 작성을 하면 되며 파일 내용은 아래와 같습니다.
[Unit] Description=Zookeeper Daemon Documentation=https://zookeeper.apache.org Requires=network.target After=network.target [Service] Type=forking WorkingDirectory=/usr/local/zookeeper User=root Group=root ExecStart=/usr/local/zookeeper/bin/zkServer.sh start /usr/local/zookeeper/conf/zoo.cfg ExecStop=/usr/local/zookeeper/bin/zkServer.sh stop /usr/local/zookeeper/conf/zoo.cfg ExecReload=/usr/local/zookeeper/bin/zkServer.sh restart /usr/local/zookeeper/conf/zoo.cfg TimeoutSec=10 Restart=on-abnormal [Install] WantedBy=default.target
위의 service 파일에서 ExecStart 를 비롯한 경로를 포함한 내용은 사용하는 환경에 맞게 경로를 변경해서 사용하시면 됩니다.
파일 작성이 모두 완료되었다면 아래와 같이 주키퍼 서비스 활성화 및 시작을 하도록 하겠습니다.
systemctl daemon-reload systemctl enable zookeeper systemctl start zookeeper
서비스가 시작되었다면 각 서버별로 아래와 같이 주키퍼 status 를 확인해 보도록 하겠습니다.
[root@kafka1]# /usr/local/zookeeper/bin/zkServer.sh status /usr/bin/java ZooKeeper JMX enabled by default Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg Client port found: 2181. Client address: localhost. Client SSL: false. [root@kafka2]# /usr/local/zookeeper/bin/zkServer.sh status /usr/bin/java ZooKeeper JMX enabled by default Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg Client port found: 2181. Client address: localhost. Client SSL: false. Mode: follower [root@kafka3]# /usr/local/zookeeper/bin/zkServer.sh status /usr/bin/java ZooKeeper JMX enabled by default Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg Client port found: 2181. Client address: localhost. Client SSL: false. Mode: leader
주키퍼 3개 중에서 3번째 서버가 leader 로 확인되고, 1,2번 서버는 follower 임을 확인할 수 있습니다.
Kafka 설치
이번에는 카프카를 설치해보도록 하겠습니다. 포스팅에서는 카프카 2.8.2 버전/Scala 2.13 버전으로 설치하였습니다.
• Kafka 다운로드 페이지
파일 다운로드 및 압축해제
mkdir -p ~/pkg cd ~/pkg wget https://archive.apache.org/dist/kafka/2.8.2/kafka_2.13-2.8.2.tgz tar xvf kafka_2.13-2.8.2.tgz -C /usr/local
이전에 주키퍼 와 동일하게 임의의 디렉토리에서 다운로드 및 압축해제를 진행하도록 하겠습니다.
/usr/local 아래에 설치를 진행하였습니다.
심볼릭 링크 설정
cd /usr/local ln -s kafka_2.13-2.8.2 kafka
카프카는 디폴트로 1GB heap 사이즈가 설정되며 EC2 프리티어나 VM과 같은 메모리가 부족한 테스트 환경이나 DEV 환경에서는 카프카 실행시 사용하는 브로커의 힙 메모리를 변경해서 사용할 필요가 있을 수 있습니다.
포스팅에서는 메모리를 조금 더 줄이기 위해서 아래와 같이 설정하였습니다(필수적인 것은 아님)
echo $KAFKA_HEAP_OPTS export KAFKA_HEAP_OPTS="-Xms500m -Xmx500m" echo $KAFKA_HEAP_OPTS echo "export KAFKA_HEAP_OPTS=\"-Xms500m -Xmx500m\"" \ >> ~/.bash_profile
참고로 아래는 내용은 Linked 에서 가장 바쁘게 사용되는 클러스터에 대한 설정과 통계지표 값입니다.
JVM
-Xms6g -Xmx6g -XX:MetaspaceSize=96m -XX:+UseG1GC -XX:MaxGCPauseMillis=20
-XX:InitiatingHeapOccupancyPercent=35 -XX:G1HeapRegionSize=16M
-XX:MinMetaspaceFreeRatio=50 -XX:MaxMetaspaceFreeRatio=80
통계
60 brokers 50k partitions (replication factor 2) 800k messages/sec in 300 MBps inbound, 1 GBps + outbound
튜닝은 상당히 공격적으로 보이지만 해당 클러스터의 모든 브로커는 GC pause time의 90%는 약 21ms이며, 초당 young GC는 1개 미만입니다
이제 카프카 클러스터 설정을 해보도록 하겠습니다. 클러스터 설정은 server.properties를 통해 할 수 있습니다.
## 로그용 디렉토리 mkdir -p /usr/local/kafka/logs ## 클러스터 설정 vi /usr/local/kafka/config/server.properties
server.properties 내용은 아래와 같이 설정하도록 하겠습니다.
## broker.id 에 대한 내용을 설정하도록 하겠습니다. 각 서버별 카프카의 server.properties 에서 broker.id 을 다르게 설정이 필요 합니다. ## 아래 와 같이 서버마다 다른 값으로 설정해주시면 됩니다. # 첫번째 서버의 경우 broker.id=1 #두번째 서버의 경우 broker.id=2 # 세번째 서버의 경우 broker.id=3 isteners=PLAINTEXT://:9092 <-- 주석해제 # listeners - 카프카 브로커가 내부적으로 바인딩하는 주소. # advertised.listeners - 카프카 프로듀서, 컨슈머에게 노출할 주소 이며 설정하지 않을 경우 디폴트로 listners 설정이 적용됩니다. - listeners 포트와 advertised.listeners 포트를 다르게 사용하지 않을 경우 listeners 옵션만 주석해제를 해도 됩니다. ## 토픽의 파티션 세그먼트가 저장될 로그 디렉토리 위치 경로를 입력 합니다. ## 포스팅에서는 해당 경로를 위에서 생성 하였습니다. log.dirs=/usr/local/kafka/logs ## 주키퍼 정보를 입력하면 되며, 주키퍼 앙상블로 구성하였기 때문에 3개의 주키퍼 정보를 모두 입력 해야 합니다. ## 3개의 클러스터인 만큼 그 다음 클러스터들을 다 쓴다음 맨 뒤에 ## /kafka-test-1 라고 포스팅에서는 추가하도록 하겠습니다. ## 사용하는 이유는 znode 의 디렉토리를 루트노드가 아닌 하위 디렉토리로 설정해 주는 의미로 하나의 주키퍼에서 여러 클러스터를 구동할 수 있게 하기 위해서 입니다. ## 명칭은 kafka-test-1 로 하지않아도 되며 포스팅에서의 예시 입니다. ## 그래서 아래와 같이 작성 하면 됩니다 zookeeper.connect=kafka1:2181,kafka2:2181,kafka3:2181/kafka-test-1
카프카의 시작, 중지도 systemd 를 통해서 하기 위해서 service 파일을 작성하도록 하겠습니다.
파일 경로는 /etc/systemd/system/kafka.service 이며 편집기로 아래 내용을 입력하면 됩니다.
[Unit] Description=Apache Kafka server (broker) Requires=network.target remote-fs.target zookeeper.service After=network.target remote-fs.target zookeeper.service [Service] Type=forking User=root Group=root Environment='KAFKA_HEAP_OPTS=-Xms500m -Xmx500m' ExecStart=/usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties ExecStop=/usr/local/kafka/bin/kafka-server-stop.sh LimitNOFILE=16384:163840 Restart=on-abnormal [Install] WantedBy=multi-user.target
위의 서비스 파일에서 사용하는 환경 마다 다른 경로는 맞게 변경해서 사용하시면 되며, 카프카 힙 메모리 관련해서 KAFKA_HEAP_OPTS="-Xms500m -Xmx500m" 내용과 동일한 의미로 Environment 에 설정된 것을 확인할 수 있습니다.
파일이 작성이 되었다면 아래와 같이 카프카 서비스 활성화 및 시작을 합니다.
systemctl daemon-reload systemctl enable kafka systemctl start kafka
동일 서버에서 설치
이번에는 동일한 한 서버에서 주키퍼3개(앙상블)와 카프카 클러스터(3개) 를 구성하는 내용에 대해서 확인해보도록 하겠으며, config의 각 설명은 위에서의 내용을 참고하시면 되며, 해당 장은 설치에 대해서만 간략하게 기술하도록 하겠습니다.
자바 및 공통 환경 설정에 대한 내용은 OS 환경 설정 을 참조하시면 됩니다.
주키퍼 설치
주키퍼 설치를 위해서 다운로드 및 압축 해제를 진행하도록 하겠습니다.
카프카에서의 주키퍼에 대한 내용은 아래 포스팅을 참조하시면 됩니다.
• 주키퍼 다운로드 페이지
다운로드 및 압축해제
wget https://dlcdn.apache.org/zookeeper/zookeeper-3.8.1/apache-zookeeper-3.8.1-bin.tar.gz tar zxvf apache-zookeeper-3.8.1-bin.tar.gz -C /usr/local
포스팅에서는 주키퍼 설치 경로는 /usr/local 아래에서 진행하였습니다.
소유권 변경 및 심볼릭 링크 생성
cd /usr/local # 소유권 변경 chown -R root:root apache-zookeeper-3.8.1-bin # 심볼릭 링크 생성 ln -s apache-zookeeper-3.8.1-bin zookeeper
디렉토리 생성 및 id 입력
주키퍼를 앙상블로 구성하기 위해서는 주키퍼 dataDIR 디렉토리에 고유한 ID 값의 입력이 필요 하며 myid 파일에 고유한 숫자를 입력하면 됩니다.
디렉터리 별로 1,2,3 으로 지정하도록 하겠으며 dataDIR 은 data1, data2, data3 으로 사용하였습니다.
포스팅에서의 주키퍼 디렉토리는 /usr/local/zookeeper 입니다.
mkdir -p /usr/local/zookeeper/data1 echo 1 > /usr/local/zookeeper/data1/myid mkdir -p /usr/local/zookeeper/data2 echo 2 > /usr/local/zookeeper/data2/myid mkdir -p /usr/local/zookeeper/data3 echo 3 > /usr/local/zookeeper/data3/myid
주키퍼 설정 파일 생성
sameple 파일을 통해서 3개의 config 파일을 복제하여 생성하도록 하겠습니다.
cd /usr/local/zookeeper/conf cp zoo_sample.cfg zoo1.cfg cp zoo_sample.cfg zoo2.cfg cp zoo_sample.cfg zoz3.cfg
설정 파일 수정
위에서 생성한 설정 파일을 수정하도록 하겠습니다.
server.(myid 의 id)= 서버 아이피: peer 와 peer 끼리 연결 포트
-> 앙상블 내 노드끼리 연결 및 리더 선출에 사용하는 포트입니다.
서버를 분리해서 설치할 경우 각 포트는 각 서버마다 동일하게 설정하지만 동일 서버에 모두 설치하기 때문에 다르게 지정하여야 합니다.
• zoo1.cfg
dataDir=/usr/local/zookeeper/data1 clientPort=2181 admin.serverPort=8881 server.1=kafka-server:28881:38881 server.2=kafka-server:28882:38882 server.3=kafka-server:28883:38883
• zoo2.cfg
dataDir=/usr/local/zookeeper/data2 clientPort=2182 admin.serverPort=8882 server.1=kafka-server:28881:38881 server.2=kafka-server:28882:38882 server.3=kafka-server:28883:38883
• zoo3.cfg
dataDir=/usr/local/zookeeper/data3 clientPort=2183 admin.serverPort=8883 server.1=kafka-server:28881:38881 server.2=kafka-server:28882:38882 server.3=kafka-server:28883:38883
주키퍼 실행
아래와 같이 주키퍼 3개를 실행합니다
cd /usr/local/zookeeper ./bin/zkServer.sh start ./conf/zoo1.conf ./bin/zkServer.sh start ./conf/zoo2.conf ./bin/zkServer.sh start ./conf/zoo3.conf
Kafka 설치
이번에는 카프카를 설치하도록 하겠습니다.
• 카프카 다운로드 페이지
다운로드 및 압축해제
wget https://archive.apache.org/dist/kafka/2.8.2/kafka_2.13-2.8.2.tgz tar xvf kafka_2.13-2.8.2.tgz -C /usr/local
포스팅에서는 설치 위치를 /usr/local 아래로 사용하였습니다.
심볼릭 링크 생성 및 로그 디렉토리 생성
동일 서버에서 카프카를 실행하기 때문에 디렉토리를 각각 생성을 합니다.
cd /usr/local ln -s kafka_2.13-2.8.2 kafka mkdir -p /usr/local/kafka/log1 mkdir -p /usr/local/kafka/log2 mkdir -p /usr/local/kafka/log3
serverN.properties 파일생성
server.properties 파일을 통해서 3개의 properties 을 복사하여 생성합니다.
cd /usr/local/kafka/config/ cp server.properties server1.properties cp server.properties server2.properties cp server.properties server3.properties
properties 설정
각 파일별로 아래와 같이 설정을 합니다.
• server1.properties
broker.id=1 listeners=PLAINTEXT://:9092 log.dirs=/usr/local/kafka/log1 zookeeper.connect=localhost:2181,localhost:2182,localhost:2183
• server2.properties
broker.id=2 listeners=PLAINTEXT://:9093 log.dirs=/usr/local/kafka/log2 zookeeper.connect=localhost:2181,localhost:2182,localhost:2183
• server3.properties
broker.id=3 listeners=PLAINTEXT://:9094 log.dirs=/usr/local/kafka/log3 zookeeper.connect=localhost:2181,localhost:2182,localhost:2183
카프카 실행
/usr/local/kafka ./bin/kafka-server-start.sh -daemon ./config/server1.properties ./bin/kafka-server-start.sh -daemon ./config/server2.properties ./bin/kafka-server-start.sh -daemon ./config/server3.properties
토픽 생성과 메세지 전송 테스트
카프카 설치 및 클러스터 구성이 완료되었기 때문에 Topic(토픽)을 생성하고 메세지를 전송해보도록 하겠습니다.
카프카를 이용한다는 의미는 다시 말해 카프카로 메세지를 주고받는다는 의미입니다.
카프카로 메세지를 전송하는 실습을 진행하기에 앞에서 가장 먼저 해야 할 일은 토픽을 생성하는 것입니다.
일반적으로 프로듀서가 카프마로 메세지를 전송할 때 카프카로 그냥 전송하는 것이 아니라, 카프카의 특정 토픽으로 전송하게 됩니다.
카프카가 설치된 서버로 ssh 로 접속한 다음에 kafka-topic.sh 를 통해서 토픽을 생성하도록 하겠습니다.
토픽 생성
kafka-topics.sh --bootstrap-server kafka1:9092 \ --create --topic test-overview01 \ --partitions 1 --replication-factor 3 Created topic test-overview01.
위에서는 파티션 1개 그리고 복제본 수 3개로 설정한 토픽을 생성하였고 토픽명은 test-overview01 입니다.
추가로 창을 하나 더 오픈하고, 먼저 1개의 창에서 프로듀서 역할로 메세지를 보내 보도록 하겠습니다.
먼저 컨슈머 측의 창에서 카프카에 접속하도록 하겠습니다.
-- consumer kafka-console-consumer.sh --bootstrap-server kafka1:9092 --topic test-overview01
컨슈머에서는 접속 후 아무런 동작이 일어나지는 않습니다 왜냐면 지금 아무런 메세지를 토픽에 보내고 있지 않기 때문에 입니다.
다시 프로듀서에 First message 라고 입력(엔터) 하면 컨슈머에서도 출력이 되는 것을 확인할 수 있습니다.
-- producer kafka-console-producer.sh --bootstrap-server kafka1:9092 --topic test-overview01 > First message
생성한 토픽 목록을 확인해보기 위해서는 아래와 같이 list 명령어를 통해서 조회할 수 있습니다.
[root]# kafka-topics.sh --bootstrap-server kafka1:9092 --list __consumer_offsets test-overview01
이번 포스팅은 주키퍼와 카프카 클러스터 구성을 확인해 보았고 여기서 정리하도록 하겠습니다.
Reference
Reference URL
• cloudera.com/zookeeper-ports
• confluent.io/kafka/deployment#jvm
• confluent.io/versions#java-sys-req
• github.com/jcustenborder
관련된 다른 글

Principal DBA(MySQL, AWS Aurora, Oracle)
핀테크 서비스인 핀다에서 데이터베이스를 운영하고 있어요(at finda.co.kr)
Previous - 당근마켓, 위메프, Oracle Korea ACS / Fedora Kor UserGroup 운영중
Database 외에도 NoSQL , Linux , Python, Cloud, Http/PHP CGI 등에도 관심이 있습니다
purityboy83@gmail.com / admin@hoing.io
카프카 정리를 잘 하셨네요.
안녕하세요
제가 다시 보았을 때 다시 잘 기억 할 수 있도록 정리하다 보니 조금 더 신경 쓴 것 같습니다.
친절한 코멘트 감사합니다.
좋은 하루 되세요
관심을 조금만 가져봅니다 ㅎㅎㅎ
안녕하세요
관심과 댓글 감사합니다.
좋은 하루 되세요~!
잘 읽었습니다. 감사합니다.
코멘트 감사합니다.
좋은 하루되세요
카프카와 주키퍼의 로그 위치를 알 수 있을까요?
안녕하세요
설치 디렉토리 아래 log 또는 logs 디렉토리 안의 파일을 찾아보시면 될 것 같습니다.
감사합니다.
로그 위치는 찾았습니다.
그리고 connector라는걸 기동해야 하지 않나요?
카프카를 사용하는 방식은 다양하고
그중 하나가 커넥터를 이용하는 것 입니다.
커넥터를 이용하려면 kafka connect를 기동해야 합니다.
동일 서버에 Kafka 구성하는 방법대로 똑같이 진행한 것같은데......
Kafka 브로커 기동 시 에러가 발생하네요. 혹시 조언해주실 수 있으실까요?
[2024-05-03 16:49:49,606] INFO Socket error occurred: localhost/127.0.0.1:2181: 연결이 거부됨 (org.apache.zookeeper.ClientCnxn)
[2024-05-03 16:49:49,706] INFO Opening socket connection to server localhost/127.0.0.1:2182. Will not attempt to authenticate using SASL (unknown error) (org.apache.zookeeper.ClientCnxn)
[2024-05-03 16:49:49,707] INFO Socket error occurred: localhost/127.0.0.1:2182: 연결이 거부됨 (org.apache.zookeeper.ClientCnxn)
[2024-05-03 16:49:50,807] INFO Opening socket connection to server localhost/127.0.0.1:2183. Will not attempt to authenticate using SASL (unknown error) (org.apache.zookeeper.ClientCnxn)
안녕하세요
주키퍼가 정상적으로 구동중인게 맞는지요? 주키퍼를 먼저 확인해봐주세요
그리고 지금 설치에 사용하신 카프카 버전은 어떻게 되시나요?
감사합니다.
주키퍼 확인해보라고 해서......
주키퍼 실행하는 부분의 명령어 수정하니 되네요.
./bin/zkServer.sh start ./conf/zookeeper1.conf
./bin/zkServer.sh start ./conf/zookeeper2.conf
./bin/zkServer.sh start ./conf/zookeeper3.conf
./bin/zkServer.sh start ./conf/zoo1.cfg
./bin/zkServer.sh start ./conf/zoo2.cfg
./bin/zkServer.sh start ./conf/zoo3.cfg
내용에서도 수정해주세요. 아주 큰 도움되었습니다. 감사해요.
피드백 감사합니다.
블로그 본문 내용 수정하였습니다.
감사합니다.