








Last Updated on 6월 26, 2024 by Jade(정현호)
안녕하세요
이번 블로그 글은 MySQL의 Semi-Sync 복제 환경에서 Source 데이터베이스의 장애 발생에 따른 장애조치(Failover) 상황과 관련되어 몇 가지 내용을 확인해보려고 합니다.
Contents
MySQL의 복제 방식
MySQL의 복제 방식은 구성하기 따라서 어떻게 분류하기에 따라서 여러가지로 정의나 표현할 수 있습니다.
본 내용을 다루기 전에 먼저 포스팅 글과 관련하여 MySQL 복제 방식을 확인해보도록 하겠습니다.
Async Replication(비동기화)
Async Replication은 비동기화이면서 MySQL의 표준 복제 방식입니다. MySQL은 기본적으로 예전부터 사용한 Async Replication 을 사용하게 됩니다.
Binary Log에는 MySQL의 모든 변경 사항이 기록이 되고 Replica DB 인스턴스에서는 이 Binary Log(이하 binlog) 를 이용하여 데이터 복제가 수행됩니다.
MySQL Async Replication(표준 비동기화 복제)는 다음과 같은 다이어그램 방식으로 복제가 진행됩니다.

<MySQL Async Replication>
복제 과정에서 Async(비동기) 방식으로 동작하기 때문에 Master 에서는 Replica(레플리카) DB 인스턴스의 복제 완료(성공) 여부 등을 확인하지 않고 Master 서버 중인 트랜잭션을 종료 및 결과 반환하게 됩니다.
복제(Replication) 토폴로지 시스템에서 완전 동기화(Sync)가 이와 같은 비동기화(Async) 경우 Source(소스) DB 인스턴스에서의 데이터 변경 량이나 Replica(레플리카) 서버의 부하 정도, 시스템 사용률, 네트워크 속도 등 여러가지 이유로 Replica DB 인스턴스에서 복제가 늦어질 수도(복제 지연) 있고 그에 따라 조회 시 Source(소스) 와 Replica(레플리카) 간에 데이터의 차이가 발생할 수 있습니다.
Semi-sync Replication(반 동기화)
Semi-sync Replication 복제 방식은 MySQL 5.5 버전에서 도입된 새로운 복제 방식으로 소스(Source) DB 인스터스에서 레플리카(Replica) DB 인스턴스로 전달된 변경 내용이 Relay log의 기록이 완료되었다는 메시지(신호)를 받고나서 처리중인 transaction의 결과를 요청한 application(client)에 결과를 반환해주는 방식입니다.

<MySQL Semi-sync Replication>
Async(비동기) 방식에 비하면 Semi-sync 방식이 클라이언트에 반환되는 응답 속도 성능이 조금 저하되긴 하지만 완전한 Sync(동기화, Replica 인스턴스에서 relay log 내용까지 DB에 적용까지 되는) 방식보다는 성능 저하가 덜 하고 레플리카 인스턴스까지는 일단 변경 사항이 전달되었기 때문에 소스 인스턴스와 레플리카 인스턴스사이의 데이터에 대한 동기화 나 안전성 측면에서 Async(비동기화) 방식에 비해 더욱 보장해줄 수 있게 됩니다.
Semi-sync(반동기) 복제 방식의 성능 저하는 Async(비동기) 복제에 비해 데이터 무결성을 높이는 대가입니다. 속도 저하의 정도는 최소한 커밋을 Replica 인스턴스로 보내고 Replica 인스턴스로부터 수신 확인을 기다리는 TCP/IP 왕복시간입니다.
이는 Semi-sync(반동기) 복제가 가까운 서버들 사이에서 빠른 네트워크로 통신할 때 가장 작동하며, 먼 서버들 사이에서 느린 네트워크로 통신할 때 가장 나쁘게 작동한다는 것을 의미합니다.
Semi-sync Replication 은 변경 내용에 대한 전달 시기(방법)에 따라서 after_commit(ver 5.5) 과 after_sync(ver 5.7) 방식으로 나뉘게 됩니다.

after_sync
MySQL 5.7 부터 도입 및 기본 설정이 된 after_sync 방식에 대해서만 간단히 살펴보도록 하겠습니다.

<Semi-sync: after_sync>
동작 방식은 간략하게 트랜잭션 Commit 요청 -> Binlog Flush/Commit -> Binlog dump send Event with ACK Request(Binlog dump thread는 ACK 요청과 함께 이벤트를 보냅니다.) -> Replica 인스턴스의 Relay Log 에 기록 -> Ack -> Engine Commit -> User Commit OK(End) 순으로 진행 됩니다.
after_sync 방식은 Binlog dump 을 binlog flush/commit 이후 전송하는 방식입니다.
misunderstanding
Semi-Sync 방식을 사용하면서 오해할 수 있는 내용은 크게 다음과 같은 3가지로 생각합니다.
- Semi-sync(반동기화)에서 Replica 인스턴스는 항상 최신의 데이터를 가지고 있다.
- Semi-sync는 복제 지연이 발생하지 않는다.
- Source 인스턴스가 장애가 발생하더라도 Semi-sync이기 때문에 Replica 인스턴스는 항상 최신의 데이터를 가지고 있다.
위의 3가지에 대해서는 모두 항상 그렇지는 않다(즉, 아니다) 라고 할 수 있습니다.
첫번째로 Semi-sync(반동기화)는 최신의 상태 데이터를 레플리카 인스턴스의 Relay log에 기록을 하고 클라이언트에 트랜잭션 완료 응답을 주기 때문에, 만약 클라이언트에서 트랜잭션 완료 응답을 받고 레플리카 인스턴스에서 데이터를 조회 시도한 경우 해당 변경 내역이 보이지 않을 수 있습니다.
왜냐하면 Relay log에 대해서 레플리카 인스턴스에 실제 반영까지 차이가 있을 수 있기 때문입니다. 즉 복제 지연이 아주 작더라도 있을 수가 있고 상황에 따라서 많은 복제 지연이 있을 수도 있기 때문입니다.
그래서 Semi-sync를 사용한 레플리카 인스턴스가 Source(소스) 인스턴스와 마찬가지로 항상 최신의 데이터를 가지고 있다 라고 개념적으로 말하기는 어렵습니다.
조회 시 소스 인스턴스와 레플리카 인스턴스가 같은 최신의 데이터를 가지고 있다고 보증하려면 Sync(동기화) 형태로 복제 방식을 사용해야 합니다.
두번째는 Semi-sync 에서도 복제 지연은 발생한다는 의미입니다. Semi-sync(반동기화) 복제 방식은 트랜잭션이 레플리카 인스턴스의 Relay log에 완료 응답을 받고 클라이언트에게 commit 완료 응답을 하기 때문에 relay log에 트랜잭션 내용이 레플리카 인스턴스에 실제로 반영하기까지 당연히 시간적인 차이가 있을 수밖에 없습니다.
실제로 Source 인스턴스에 많은 부하가 발생시키면 레플리카 인스턴스에서는 지연이 발생하는 것을 확인할 수 있습니다.
또한 레플리카 인스턴스에서 SQL Thread 만 중지하고 Source 인스턴스에서 데이터를 입력해도 지연이나 블러킹 없이 데이터 입력이 됩니다. 이 말의 의미는 Semi-sync 복제 방식은 레플리카 인스턴스의 Relay log까지의 반영된 것을 확인한다는 의미입니다.
세번째로 Source 인스턴스의 장애 발생시 Semi-sync 이기 때문에 레플리카 인스턴스는 항상 최신의 데이터를 가지고 있다 라는 내용으로 해당 내용이 포스팅 글에서 말하고자 하는 주요 내용입니다.
이 부분은 특정 HA 솔루션에서 특정 상황일 경우를 제외한 다른 HA솔루션을 사용하거나 사용자가 직접 Failover 하는 경우 등에서 적용될 수 있는 내용입니다.
Semi-sync를 사용하는 환경에서 다음과 같은 장애 발생 및 처리 시나리오를 살펴보겠습니다.
1) MySQL Source 인스턴스의 Crash가 발생하였거나, Source 인스턴스의 서버의 다운 또는 재시작 등에 의해서 장애가 발생하였습니다.
2) Source 인스턴스의 장애로 인하여 장애조치(Failover)가 수행되었고 Replica 인스턴스 중에서 하나가 새로운 Source 인스턴스로 프로모션(promotion, 승격) 되었습니다.
3) 이전의 Source 인스턴스는 Instance Recovery 과정을 거쳐서 인스턴스가 가동되었습니다.
4) 이전의 Source 인스턴스에서는 지금의(새로운) Source 인스턴스에서 볼 수 없는 더 최신의 데이터가 관찰됩니다.
위의 시나리오에서 4번 항목이 과연 가능한 것이고 어떤 것을 의미하는지를 살펴볼 필요가 있습니다.
4번 항목의 내용처럼 복구된 이전 소스 인스턴스에 더 최신의 트랜잭션 데이터가 있는 것은 정상입니다.
이것은 Semi-sync나 async 와 같은 MySQL 복제 토폴로지의 오류 등은 아닙니다.
Semi-sync 동작과 커밋에 대한 이해
Semi-sync 모드를 사용한 MySQL 복제 방식은 이전의 after_commit과 다르게 팬텀 읽기를 방지할 수 있다는 추가적인 이점과 함께 Semi-sync(반동기화)의 가장 주요한 목적인 클라이언트가 commit 에 대해서 승인받았다면 트랜잭션은 Replica 인스턴스에 복제되고 유지되는 기능을 제공합니다.
이 과정이 어떻게 작동하는지 이해하려면 MySQL이 트랜잭션을 커밋하는 방식을 자세히 조금 더 살펴봐야 합니다.
MySQL이 트랜잭션을 커밋할 때 다음 단계를 거칩니다.
- 스토리지 엔진(InnoDB)에서 트랜잭션을 준비(prepare) 합니다.
- 트랜잭션을 바이너리 로그에 기록합니다.
- 스토리지 엔진에서 트랜잭션을 완료합니다.
- 클라이언트에게 승인을 반환합니다.

Semi-sync(반동기화)와 Async(표준 비동기화) 복제는 동일한 방식으로 트랜잭션이 바이너리 로그에 기록된다는 점을 이해와 인식하는 것이 중요합니다.
즉, 위의 단계에서 Semi-sync(반동기화)와 Async(표준 비동기화) 복제는 2단계까지는 동일하게 작동합니다.
Semi-sync 복제 방식에서 트랜잭션의 복제 대기는 위의 단계 중에서 2단계와 3단계 사이에서 발생합니다. 이 시점에는 트랜잭션이 스토리지 엔진에서 트랜잭션 완료가 되지 않았으므로 다른 클라이언트에서는 아직 해당 데이터를 볼 수 없는 상황입니다.
그러나 지금과 같이 아직 트랜잭션이 완료되지 않은 경우 경우(시점)에서 Source(소스) 인스턴스가 비정상 종료(Crash) 발생하거나 서버가 재시작 등의 장애가 발생된 상황에서도 그 다음 인스턴스 시작 후에는 해당 트랜잭션(데이터)이 데이터베이스에 존재하게 됩니다.
이러한 상황을 더 자세하게 이해하려면 MySQL 및 InnoDB Crash(크래쉬, 충돌) 복구에 대해 자세히 살펴봐야 합니다.
InnoDB는 Crash 이후에 복구 과정 중에 완료되지 않은(위의 절차에서 트랜잭션 커밋의 3단계에 도달하지 않은) 트랜잭션을 롤백합니다.
따라서 아직 커밋되지 않은 트랜잭션(1단계에 도달하지 않음) 또는 아직 바이너리 로그에 기록되지 않은 트랜잭션(2단계에 도달하지 않음)은 InnoDB에서 Automation Recovery 후 데이터베이스에서는 존재하지 않습니다.
만약에 InnoDB가 바이너리 로그에 도달했지만(2단계) <<완료>>되지 않은(2단계 후 ~ 3단계 전) 트랜잭션을 롤백을 하게 된다면 Replica 인스턴스에 도달할 수 있었던 트랜잭션이 Source 인스턴스에서는 사라짐을 의미합니다.
이렇게 된다면 복제 토폴로지 환경에서 Source 와 Replica 인스턴스의 데이터가 불일치가 발생하고 복제 토폴로지 정합성을 위배할 수 있는 것일수도 있습니다.
그래서 트랜잭션이 바이너리 로그에 기록되었다면 해당 트랜잭션은 롤포워드(DB에 기록)를 해야 합니다.
위에서 설명한 Source 와 Replica 간의 데이터 불일치를 방지하려면 MySQL은 스토리지 엔진의 Crash 복구 전에 자체적인 Crash 복구를 수행하며, 이 복구는 바이너리 로그의 모든 트랜잭션이 <<완료>> 되었는지 확인을 하게 됩니다.
인스턴스 비정상종료(Crash) 시점에 트랜잭션이 2단계와 3단계 사이에 있다면 복구 중에 해당 트랜잭션에 대해서 완료 flag가 지정되고 롤포워드가 수행됩니다.
이러한 과정은 Semi-sync가 아닌 Async(표준 비동기화) 에서도 수행 및 발생할 수 있다는 점이 중요한 내용입니다.
정리하면 문제가 발생(Crash) 후에 재시작 복구된 이전 Source 인스턴스에서는 Replica 인스턴스에서 볼 수 없는 더 추가적인 새로운 트랜잭션 데이터를 볼 수 있다는 점은 MySQL 과 InnoDB의 Crash Recovery 를 수행하는 고유의 방식 때문입니다.
Semi-sync 복제 방식 사용시에 트랜잭션을 커밋하는 방식의 2단계와 3단계 사이에 복제 동기화 프로세스가 동작하고 그에 따라서 2단계와 3단계 사이에서 Async 복제 방식보다 상대적으로 시간적 소요(지연)가 되므로 Semi-sync 방식에서 더 자주 이러한 상황이 발생될 수 있지만 타이밍이 맞는다면 Async(표준 비동기화) 방식에서도 발생할 수는 있습니다.
MySQL의 Two-Phase Commit에 대한 더 자세한 내용은 다음의 포스팅 글을 참조하시면 됩니다.

Situation Reproduction
위에서 설명한 내용의 상황 재현은 크게 어렵지 않으며, 재현하기 위해서는 시스템의 사양이 조금 좋지 못하면서 짧은 시간안에 많은 트랜잭션을 수행을 하게 되면 보다 쉬운 재현이 가능합니다.
글에서는 다음의 그림처럼 테스트 시스템을 구성하였습니다.
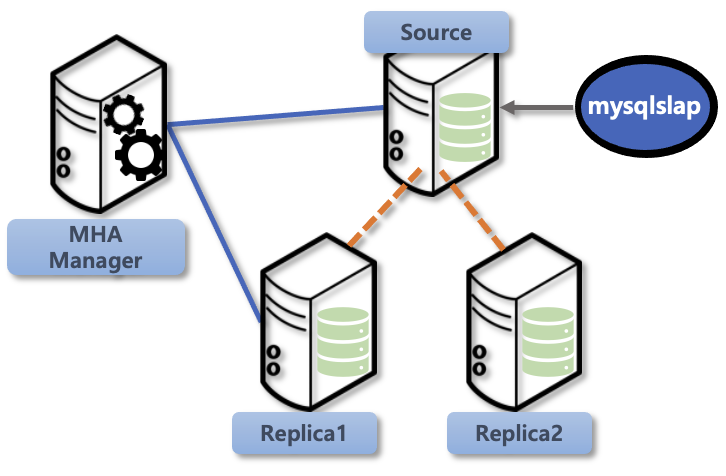
MySQL 3개 인스턴스를 사용하였고 2개의 인스턴스에서만 MHA HA 솔루션이 모니터링을 하고 있습니다. Replica 2번 인스턴스는 MHA 모니터링(관리) 대상이 아닙니다. 그리고 사용한 버전은 MySQL 8.0.34입니다.
2개 인스턴스만 MHA에서 모니터링 하고 있기 때문에 Source 인스턴스 문제시 Replica 1 인스턴스가 Source 인스턴스로 승격(promotion) 될 것이며, 향후에 더 자세히 설명할 MHA binlog 복구 대상은 Replica 1만 수행될 것입니다.
소스 DB인스턴스에 데이터 입력은 mysqlsap을 통해서 진행하였으며 mysqlsap에 대한 내용은 다음 포스팅을 참조하시면 됩니다.

mysqlsap 수행시 concurrency는 200으로 iterations는 1로 하였으며 실행 후 2초 뒤에 MySQL 인스턴스를 kill -9 명령어로 비정상 종료하는 순서로 진행하였습니다.
테스트시 MHA HA를 사용하지 않은(매니저 시작하지 않음) 환경에서 먼저 진행하였고, 그 다음에는 MHA가 동작하는 환경에서 테스트하였습니다.
mysqlsap 으로 데이터 입력 후 2초뒤 MySQL 인스턴스를 비정상 종료(Crash) 하였을 때 다음과 같은 데이터 입력 상황을 확인할 수 있습니다.
MHA 미사용
1 Source 인스턴스에 2개의 Replica 인스턴스가 Semi-sync 복제 방식 구성된 상태에서 mysqlslap 을 부하를 입력 후 Source 인스턴스를 비정상 종료(kill -9) 후에 Replica 인스턴스에서 조회 결과입니다.
Replica 데이터 상태 확인
## Replica 1 mysql> select count(id) from test1.t1; +-----------+ | count(id) | +-----------+ | 1635 | +-----------+ ## Replica 2 mysql> select count(id) from test1.t1; +-----------+ | count(id) | +-----------+ | 1642 | +-----------+
2개 레플리카 인스턴스에서 입력된 데이터가 차이가 있는 것은 복제시 시스템(서버) 상태에 따른 복제 속도의 영향이 있을 수도 있고, 또는 Semi-sync 방식을 사용하기 때문에 관련 파라미터 기본값 1에 의해서 여러 Replica 인스턴스 중에서 1개의 Replica 인스턴스에서 응답이 있을 경우 commit 완료를 처리하고 그 다음 트랜잭션 처리를 계속 이어가기 때문에 2개 인스턴스의 데이터 입력 상태가 다를 수 있습니다.
그러면 Semi-sync 복제 방식이기 때문에 Replica 2 인스턴스 데이터가 가장 최신의 데이터가 맞을까요?
비정상 종료(Crash)가 된 Source 인스턴스를 시작을 해서 데이터를 확인해보도록 하겠습니다. 비정상 된 Source 인스턴스를 다시 기동하기 전에 확인을 위해 2개 Replica 인스턴스에서 명시적으로 복제를 중지하도록 하겠습니다.
replica1-mysql> stop replica; replica2-mysql> stop replica;
Source 인스턴스 시작
[inst1-mysql]$ ./mysql.server start
Source 인스턴스 데이터 확인
mysql> select count(id) from test1.t1; +-----------+ | count(id) | +-----------+ | 1798 | +-----------+
가장 최신의 데이터를 가지고 있다고 생각할 수 있는 Replica 2 인스턴스보다 비정상 종료되었던 Source 인스턴스 데이터가 많은(더 최신의) 데이터를 가지고 있는 것을 확인할 수 있습니다.
만약 Source 인스턴스가 장애가 발생하였고 HA 솔루션에 의해서 Failover가 발생하였고 장애가 발생한 Source 인스턴스가 Replica 인스턴스 유형으로 해서 새로운 Source 인스턴스에 접속하여 복제를 수행하도록 복제 토폴로지 구성원으로 조인하게 된다면 어떻게 될까요?
새로운 Source 가 가장 최신의 데이터를 가지고 있다고 생각하고 있었으나 추가된 Replica 인스턴스 멤버가 더 많은 더 최신의 데이터를 보유하고 있는 데이터상의 불일치 상태가 발생하게 되는 것입니다.
이런 상황은 위에서 설명한 것처럼 "트랜잭션이 바이너리 로그에 기록되었다면 해당 트랜잭션은 롤포워드" 에 의해서 복구가 된 것이기 때문입니다.
비정상 종료된 Source 인스턴스를 시작하였을 때 mysqld 로그를 살펴보면 다음과 같은 내용을 확인할 수 있습니다.
[MY-010855] [Server] Recovering after a crash using /usr/local/mysql/data/binlog [MY-010229] [Server] Starting XA crash recovery... [MY-013911] [Server] Crash recovery finished in binlog engine. No attempts to commit, rollback or prepare any transactions. [MY-013033] [InnoDB] Transaction 32297 in prepared state after recovery [MY-013034] [InnoDB] Transaction contains changes to 1 rows < ...중략 ...> [MY-013035] [InnoDB] 157 transactions in prepared state after recovery [MY-010224] [Server] Found 157 prepared transaction(s) in InnoDB [MY-013911] [Server] Crash recovery finished in InnoDB engine. Successfully committed 157 internal transaction(s). [MY-010232] [Server] XA crash recovery finished.
비정상 종료된 후 그 다음 시작시 MySQL과 InnoDB는 여러 복구 절차를 진행하며 그 과정 중에서 확인할 수 있는 메세지입니다.
Recovery 를 위해서 binlog를 이용한다는 내용과 몇 개의 prepared(준비된) 트랜잭션을 찾았고 복구했다는 내용과 XA 트랜잭션을 recovery 하였다는 내용을 확인할 수 있습니다.
확인해본 것과 같이 Semi-sync 환경에서 항상 Replica 인스턴스가 가장 최신의 데이터를 가지고 있다라고 할 수는 없을 것 같습니다.
MHA 사용
이번에는 MHA HA 솔루션을 사용했을 경우 테스트입니다. MySQL 을 사용하면서 장애조치를 할 수 있는 HA는 여러가지가 있을 것입니다. 다만 MHA HA 솔루션 다른 HA 솔루션과 다른 특정 기능이 있기 때문에 같이 MHA를 통해서 추가로 내용을 확인해보려고 합니다.
Source 인스턴스 Kill 후, Failover 수행 전
MHA에 등록된 Replica 1
mysql> select count(id) from test1.t1; +-----------+ | count(id) | +-----------+ | 1041 | +-----------+
MHA에서 모니터링하지 않는 Replica 2
mysql> select count(id) from test1.t1; +-----------+ | count(id) | +-----------+ | 1178 | +-----------+
위의 상황은 Source 인스턴스가 mysqlslap 을 통해 데이터 입력 중간에 kill 된 상황으로 MHA에 의해서 아직 failover 프로세스가 진행되지는 않은 시점의 데이터 상태입니다.
MHA - Failover 수행 후
New Source 인스턴스(이전 Replica 1)
mysql> select count(id) from test1.t1; +-----------+ | count(id) | +-----------+ | 1185 | +-----------+
MHA에 의해 Failover가 수행된 후 승격(Promotion) 되어서 새로운 Source 인스턴스가 된 이전 Replica 1 을 다시 조회를 해보면 이전과 다르게 데이터가 증가한 것을 확인할 수 있습니다.(1041 -> 1185)
이제 kill 에 의해서 비정상 종료된 이전 Source 인스턴스를 재시작 후에 데이터를 조회해보도록 하겠습니다.
Crash 된 이전 Source 인스턴스
# 인스턴스 기동 [mysql]$ ./mysql.server start # 인스턴스 기동 후 데이터 조회 mysql> select count(id) from test1.t1; +-----------+ | count(id) | +-----------+ | 1185 | +-----------+
위의 조회결과에서 확인할 수 있는 것처럼 비정상 종료된 이전 Source 인스턴스와 새로운 Source 인스턴스(이전 Replica 1)이 데이터가 같은 것을 알 수 있습니다.
이것은 MHA HA 솔루션의 고유한 기능으로 장애가 발생한 Source 인스턴스와 새로운 Source 인스턴스간의 로그 파일과 로그 포지션을 확인하여 차이나는 트랜잭션에 대해서 장애가 발생한 Source DB 서버의 binlog 내용을 새로운 Source DB에 적용하는 과정이 진행되며, MHA Failover 진행 내역에서 다음과 같은 내용을 확인할 수 있습니다.
• MHA Failover 시
Phase 3.2: Saving Dead Master's Binlog Phase Phase 3.3: Determining New Master Phase Phase 3.4: New Master Diff Log Generation Phase Phase 3.5: Master Log Apply Phase
서버가 다운이 되었거나 서버 자체가 재시작 되는 장애가 발생시에 Source DB의 binlog 파일을 확인할 수 없기 때문에 위와 같은 절차는 수행할 수 없게 되고, 위의 절차 없이 Failover가 진행되면 처음 테스트한 내용처럼 이전의 Source DB가 더 최신의 데이터를(또는 더 많은 데이터를) 가지고 있는 상태가 됩니다.
MHA와 다르게 별도의 추가적인 절차가 없이 Failover 가 진행되는 다른 보통의 HA 솔루션의 경우 해당 시스템에서 데이터 변경에 대한 동시성이 높을수록 높은 확률로 이와 같은 현상이 발생할 수 있습니다.
conclusion
MySQL에서는 binlog와 관련되어 Two-Phase Commit(XA)이 동작하며 그리고 이 동작은 복제 환경에서 Replica로 데이터 복제 상황을 고려합니다. 그래서 위와 같이 특정 상황에서, binlog에 작성된 트랜잭션에 대해서 다시 복구를 진행하게 되고 복제 환경에서 서버(또는 DB)에 장애 발생시 장애 조치(Failover)를 수행하면 상황에 따라서 데이터의 문제가 발생될 수 있다는 점을 확인하였습니다.
MySQL 문서에서도 다음과 같은 내용이 명시적으로 표기되어 있습니다.
With semisynchronous replication, if the source crashes and a failover to a replica is carried out, the failed source should not be reused as the replication source, and should be discarded. It could have transactions that were not acknowledged by any replica, which were therefore not committed before the failover.
번역을 하면 다음과 같습니다.
"반동기 복제를 사용하면 소스(Source,Master)가 장애가(Crash, 충돌)발생하고 복제본(Replica)에 대한 장애 조치(Failover)가 수행되는 경우 실패한 소스를 복제 소스로(Replica인스턴스로) 재사용해서는 안 되며 폐기해야 합니다. 복제본(Replica)에서 승인하지 않은 장애 조치 전에 커밋되지 않은 트랜잭션이 있을 수 있습니다.(이전 Source 인스턴스에서)"
MySQL 문서에서도 위의 테스트 상황과 동일한 내용으로 문제가 발생한 Source 인스턴스에 더 최신의 데이터(더 많은 데이터)가 있을수 있음을 설명하고 있고 Failover 후 Read Replica 인스턴스로 사용하지 말라고 설명하고 있습니다.
이와 같은 상황을 고려하여 facebook에서는 MySQL이 스토리지 엔진에서 아직 "완료"되지 않은 트랜잭션을 롤백 하도록 하는 형태로 수정하여 사용하였다고 하는 내용도 예전에 Percona Live에서 공유된 적이 있었으며, 예전에 운영 환경에서도 운영정책으로 장애가 발생된 이전 Source 인스턴스는 Read Replica로 재사용하지 않고 폐기하여 재구성 후 Read Replica 로 사용하도록 하는 정책도 있었습니다.
이번에는 MySQL의 Semi-sync(반동기), HA Failover 상황, Two-Phase Commit 과 같은 여러 기술과 발생할 수 있는 상황에 대해서 살펴보았으며 여기서 글을 마무리하도록 하겠습니다.
Reference
Reference URL
• mysql.com/replication-semisync
• percona/about-semi-synchronous-replication
연관된 다른 글


Principal DBA(MySQL, AWS Aurora, Oracle)
핀테크 서비스인 핀다에서 데이터베이스를 운영하고 있어요(at finda.co.kr)
Previous - 당근마켓, 위메프, Oracle Korea ACS / Fedora Kor UserGroup 운영중
Database 외에도 NoSQL , Linux , Python, Cloud, Http/PHP CGI 등에도 관심이 있습니다
purityboy83@gmail.com / admin@hoing.io
