









Last Updated on 8월 8, 2023 by Jade(정현호)
안녕하세요
이번 포스팅에서는 MySQL의 Multi-Threaded Replication(병렬 복제) 에 대해서 내용을 확인해 보도록 하겠습니다.
Contents
MTS introduction background
MySQL 버전 5.5 및 이전 버전에서 슬레이브의 바이너리 로그 applier(어플라이어, 적용자)는 단일 스레드였으며, Replica에서의 복제 지연은 시간이 지남에 더 커지는 근본적인 이유로는 Source 인스턴스에 비해 Replica 인스턴스의 applier(어플라이어, 적용자)의 처리량이 불충분하였기 때문입니다.
일반적으로 당시 시스템에서는 프로세서당 1코어에서 프로세서당 다중 코어로 사용 가능해지고 비지니스의 규모가 커짐에 따라서 Source 인스턴스에서는 변경량이 증가할 수밖에 없는 구조였지만 Replica 인스턴스는 여전히 단일 스레드 어플라이어로 쓰기가 처리되었기 때문에 다중 코어의 시스템의 장점을 다 활용할 수 없었습니다.
다중 코어 시스템이 보편화되었을 때 MySQL의 복제 동기화 역시도 적절한 병렬 처리를 위해서 다중 스레드 사용을 해야 했습니다.
이러한 측면에서 MySQL 5.6 버전 부터 병렬 복제 기능이 도입 되었습니다.

[Feature Preview - Multi-Threaded Replication Slaves]
MySQL 멀티 스레드 복제 기술 이전에 MySQL 기본 복제인 싱글 스레드 복제 및 Async 복제 방식에 대한 정보는 아래 포스팅을 확인 하시면 됩니다.

Multi-Threaded 방식
MySQL은 버전에 따라서 사용할 수 있는(지원되는) 멀티 스레드 방식의 차이가 있습니다.
MySQL 버전 5.6과 5.7에서 각각 추가되었으며 DATABASE 기반 방식 과 Logical Clock 기반 방식입니다.
DATABASE 기반
MySQL 5.6버전부터 서로 다른 데이터베이스(또는 스키마) 수행된 트랜잭션을 Replica 인스턴스에서 병렬 복제 동기화를 할 수 있는 DATABASE 기반 병렬 복제 기능이 도입되었습니다.
DATABASE 기반 병렬 복제 기능은 Replica 인스턴스에서 각 데이터베이스(스키마) 별로 Worker thread가 맡아서 복제 동기화를 처리하는 방식입니다.
이런 DATABASE 기반 병렬 복제는 데이터베이스 별로 Worker thread가 동작함에 따라서 특정 데이터베이스의 복제 작업이 완료되지 않았어도 다른 데이터베이스에서 복제 작업을 계속해서 진행할 수 있다는 것을 의미합니다.
코디네이터 스레드 역할을 하는 SQL 스레드는 실제로 변경 이벤트를 처리하는 Worker thread와 협업하여 복제를 진행하게 됩니다.
MySQL 5.6버전의 DATABASE 기반에서는 코디네이터 스레드가 Worker thread에게 작업을 분배(할당)하는 단위가 데이터베이스(스키마) 입니다.
하지만 이러한 DATABASE 기반 병렬 복제 동기화는 MySQL 서버에서 데이터베이스(스키마)가 하나만 존재하는 경우 멀티 스레드로 처리 할 수 없다는 단점 있습니다.
또한 MySQL 서버에서 여러 데이터베이스(스키마)가 있더라도 현실적으로 발생되는 변경 사항들이 데이터베이스별로 균등하지 않다는 점에 있습니다.
MySQL서버에 여러 데이터베이스(스키마)가 있더라도 발생되는 변경량은 특정 데이터베이스에 평중 될 수밖에 없기 때문에(균등하지 않기 때문에) Replica 인스턴스에서의 멀티 스레드의 처리는 사실상 큰 효과를 보기 어려운점이 있었습니다.
LOGICAL CLOCK 기반
MySQL 5.7버전에서 위에서 설명한 5.6버전의 DATABASE 기반의 멀티 스레드 복제 동기화의 단점인 데이터베이스 별로의 병렬 복제에 대한 부분을 개선하여 데이터베이스별로 종속되지 않고 멀티 스레드 복제를 할 수 있는 LOGICAL CLOCK 방식이 기능이 새롭게 추가되었습니다.
LOGICAL CLOCK 방식은 같은 데이터베이스내에서도 멀티 스레드 복제 동기화가 가능한 기능 입니다.
사용자는 slave_parallel_type 파라미터를 통해서 DATABASE 또는 LOGICAL CLOCK을 선택 할 수 있습니다.
slave_parallel_type 파라미터는 버전에 따라서 다음과 같은 변경이 있습니다.
- slave_parallel_type 파라미터는 5.7 그리고 버전 8.0.26 까지는 기본값은 DATABASE 였습니다.
- slave_parallel_type 파라미터는 8.0.26 부터 파라미터 명이 slave_parallel_type 에서 replica_parallel_type 으로 대체 되었습니다.
- replica_parallel_type 파라미터는 8.0.27 버전부터 기본값이 LOGICAL_CLOCK 으로 되었습니다.
- 8.0.29 버전 부터 파라미터가 Deprecated 되어서 더이상 다른 값으로 변경되지 않습니다. 즉 8.0.29 버전 부터는 LOGICAL_CLOCK 만 사용 가능함을 의미 합니다.
Logical Clock 스케줄러(scheduler)는 같은 데이터베이스에서도 멀티 스레드 복제가 가능하도록 구현 및 추가되었습니다.
다만 이 접근 방식으로 달성할 수 있는 병렬 처리에는 근본적인 한계가 있는데, 이는 Source 인스턴스에서 병렬로 실행된 것으로 추정되는 트랜잭션의 수와 또는 같이 처리할 수 있는 묶음의 단위를 결정하는 기준과 관련되어 있습니다.
그것은 클라이언트의 수 또는 병렬 처리가 감지된 방식이 고려되며, Replica 인스턴스애서 처리할 트랜잭션의 수가 적으면 Replica 인스턴스에서는 여전이 여러 트랜잭션을 병렬로 실행할 수 없거나 그 효과가 미비할 수 있다는 점 입니다.
그래서 멀티 스레드 복제에서 중요한점은 Source 인스턴스에서 어떤 기준 또는 어떤 방식으로 얼마만큼을 병렬처리가 가능한 단위로 해줄 수 있는지가 LOGICAL CLOCK 방식에서의 관건이라고 할 수 있을 것 같습니다.
MySQL 5.7에서 LOGICAL CLOCK이 처음 도입되었을 때에는 동일한 바이너리 로그 그룹에서 함께 커밋된 트랜잭션만 Replica 인스턴스에서 멀티 스레드 복제 동기화가 가능하였지만, 추후 업데이트된 MySQL 5.7 마이너버전에서는 트랜잭션의 종속성 간격에 따라서 멀티 스레드 복제가 수행될 수 있도록 개선되었으며 그룹 커밋 경계(그룹 커밋 작업의 시작과 끝) 에서 보이는 직렬화 포인트의 영향을 줄였습니다.
직렬화 포인트(Serialization points)은 병렬 처리 환경에서 동시에 실행되는 작업들 간의 순차적으로 실행을 필요로 하는 지점을 의미 합니다. 이는 동시에 실행할 수 없는(병렬처리가 되지 않은), 즉 순차적으로 실행된다는 의미로 일관성을 유지하거나 충동을 방지하기 위해서 사용됩니다.
직렬화 포인트는 동시성 제어를 위한 중요한 요소이며, 병렬 처리 시스템이나 스케줄 등에서 성능과 일관성 사이의 균형을 조절하는 역할을 합니다.
위에서 설명한 내용과 같이 MySQL 5.7 버전 초기에 동일한 바이너리 로그 그룹에서 함께 커밋된 트랜잭션만 멀티 스레드 복제 동기화가 가능하였으나, 이 후 마이너 버전에서는 다음에서 설명할 커밋 처리 시점(Window)이 겹치는 트랜잭션을 멀티 스레드 복제로 처리할 수 있는 COMMIT_ORDER 방식으로 개선되었습니다.
멀티 스레드 복제 환경에서 Replica 인스턴스에서 실제로 변경 이벤트를 처리하는 Worker thread에 대한 개수는 slave_parallel_workers 파라미터를 통해서 할 수 있습니다.
다음은 slave_parallel_workers 파라미터는 설정 관련 정보이며, 버전에 따라서 아래와 같이 변경 되었습니다.
- slave_parallel_workers 파라미터는 0부터 1024까지 설정 가능하며 기본값은 0 입니다.
- MySQL 8.0.26 버전에서 파라미터 이름이 replica_parallel_workers 으로 대체 되었습니다.
- MySQL 8.0.27 버전부터 replica_parallel_workers 파라미터의 기본값은 0에서 4로 변경 되었습니다.
- MySQL 8.0.30 버전부터는 0에 대한 설정이 Deprecated 되었으며, 향후 버전에서는 파라미터가 제거 됩니다.
코디네이터 스레드와 워커스레드
멀티 스레드 복제 기능을 사용하면 Replica 인스턴스에서 코디네이터 스레드와 워커스레드를 확인 할 수 있습니다.
mysql> show full processlist; +------+-------------+---------+-------+--------------------------------------------------------+------+ | Id | User | Command | Time | State | Info | +------+-------------+---------+-------+--------------------------------------------------------+------+ | 1441 | system user | Connect | 23285 | Waiting for master to send event | NULL | | 1442 | system user | Query | 1 | Slave has read all relay log; waiting for more updates | NULL | | 1443 | system user | Query | 1 | Waiting for an event from Coordinator | NULL | | 1444 | system user | Query | 17 | Waiting for an event from Coordinator | NULL | | 1445 | system user | Query | 190 | Waiting for an event from Coordinator | NULL | | 1446 | system user | Query | 780 | Waiting for an event from Coordinator | NULL | +------+-------------+---------+---------+------------------------------------------------------+------+ * 가로 길이에 따라서 일부 컬럼은 편집되어 있습니다.
위의 조회 결과에서 ID 1441 가 I/O 스레드이고, 1442가 코디네이터 스레드(SQL 스레드) 이고, 1443~1446까지가 워커 스레드 입니다.
위의 결과를 통해서 slave_parallel_workers(replica_parallel_workers) 는 4개라는 것을 확인할 수 있습니다.
slave_parallel_workers(replica_parallel_workers) 파라미터 0 또는 1로 설정하면 replica_parallel_type 또는 slave_parallel_type 및 replica_preserve_commit_order 또는 slave_preserve_commit_order 파라미터는 사실상 사용되지 않으며(영향을 받지 않으며) 무시 됩니다.
매뉴얼에서는 다음과 같은 내용이 있습니다.
- replica_parallel_workers을 1로 설정시 단일 어플라이어 스레드가 동작하고 코디네이터 스레드는 사용 되지 않음
다만 확인해보면 1에서는 여전히 코디네이터 스레드와 워커 스레드가 확인 됩니다.
또한 MySQL 8.0.30 버전에서 replica_parallel_workers 파라미터가 Deprecated 되었지만 테스트 환경인 MySQL 8.0.31 버전에서 여전히 replica_parallel_workers=0 으로 설정이 가능 하였습니다.
• replica_parallel_workers=0
mysql> select @@version; +-----------+ | @@version | +-----------+ | 8.0.31 | +-----------+ mysql> show variables like 'replica_parallel_workers'; +--------------------------+-------+ | Variable_name | Value | +--------------------------+-------+ | replica_parallel_workers | 0 | +--------------------------+-------+ mysql> show full processlist; +----+-----------------+---------+------+----------------------------------------------------------+-----------------------+ | Id | User | Command | Time | State | Info | +----+-----------------+---------+------+----------------------------------------------------------+-----------------------+ | 5 | system user | Connect | 54 | Waiting for source to send event | NULL | | 6 | system user | Query | 54 | Replica has read all relay log; waiting for more updates | NULL | | 10 | root | Query | 0 | init | show full processlist | +----+-----------------+---------+------+----------------------------------------------------------+-----------------------+
다만 MySQL 8.0.30 이후 버전에서 replica_parallel_workers을 1로 설정하고 재시작(또는 시작시) MySQL 서버 로그에는 다음과 같은 메세지가 기록되는것은 확인할 수 있습니다.
The syntax '--replica-parallel-workers=0' is deprecated and will be removed in a future release.
Please use '--replica-parallel-workers=1' instead.
• replica_parallel_workers=1
mysql> select @@version; +-----------+ | @@version | +-----------+ | 8.0.31 | +-----------+ mysql> show variables like 'replica_parallel_workers'; +--------------------------+-------+ | Variable_name | Value | +--------------------------+-------+ | replica_parallel_workers | 1 | +--------------------------+-------+ mysql> show full processlist; +----+-------------+---------+------+----------------------------------------------------------+-----------------------+ | Id | User | Command | Time | State | Info | +----+-------------+---------+------+----------------------------------------------------------+-----------------------+ | 5 | system user | Query | 46 | Replica has read all relay log; waiting for more updates | NULL | | 6 | system user | Connect | 46 | Waiting for source to send event | NULL | | 7 | system user | Connect | 46 | Waiting for an event from Coordinator | NULL | | 10 | root | Query | 0 | init | show full processlist | +----+-------------+---------+------+----------------------------------------------------------+-----------------------+ ID 5 : 코디네이터 스레드 ID 7 : 워커 스레드
LOGICAL CLOCK
MySQL 멀티스레드 복제 동기화 방식은 계속적인 개선이 이루어지고 있으며, 멀티 스레드 복제를 사용할 경우 대부분 사용하고 있는 LOGICAL CLOCK 방식에 대해서 더 자세하게 확인해보도록 하겠습니다.
COMMIT_ORDER
LOGICAL CLOCK 방식에서 트랜잭션간의 병렬로 처리할 수 있는 범위 또는 기준에 대해서 3가지 방식이 존재하며 binlog_transaction_dependency_tracking 파라미터에 의해서 설정할 수 있습니다.
이전에 설명한 내용과 같이 LOGICAL CLOCK이 처음 도입되었을 때에는 동일한 바이너리 로그 그룹에서 함께 커밋된 트랜잭션만 멀티 스레드 방식이 가능하였으며, 그 이후에는 COMMIT_ORDER 방식이 적용되었습니다.
LOGICAL CLOCK 세부 방식에는 COMMIT_ORDER 이외에 WRITESET , WRTIESET_SESSION 이 있으며 binlog_transaction_dependency_tracking 파라미터에 의해서 설정할 수 있습니다.
binlog_transaction_dependency_tracking 파라미터는 MySQL 5.7.22 버전과 MySQL 8.0 버전에서 추가된 파라미터로 파라미터가 추가되면서 기존의 COMMIT_ORDER에서 WRITESET , WRTIESET_SESSION 두가지 방식이 추가되었습니다.
MySQL 5.7버전에서 LOGICAL CLOCK 도입시 초기에 사용하였던 방식(동일한 바이너리 로그 그룹에서 함께 커밋된 트랜잭션만 같이 처리) 및 COMMIT_ORDER , WriteSet방식 모두 바이너리 로그 그룹 커밋과 깊은 연관성이 있습니다.
바이너리 로그 그룹 커밋에 대한 자세한 내용은 아래 포스팅을 참조하시면 됩니다.
LOGICAL CLOCK 방식은 어떤 단위로 또는 어떤 입자의 크기나 정도로 트랜잭션을 병렬화를 할 것인지가 중요한 부분입니다.
이것은 2-Phase 커밋과 바이너리 그룹 커밋과 연관 되어있습니다.
2-Phase 커밋은 Prepare 와 COMMIT(Engine Commit) 부분으로 나눌수 있으며 Prepare 와 Engine Commit 사이에서 커밋된 트랜잭션에 대해서 바이너리 로그에 쓰기가 이루어지게 됩니다.
바이너리 로그 그룹 커밋은 트랜잭션 하나하나를 바이너리 로그에 쓰기(fsync)를 하지 않고 특정 주기안에서 트랜잭션을 묶어서(그릅화) 쓰기를 하는 방식으로 성능을 높이는 기능입니다.
(상세한 내용은 이전 포스팅 참조)
기존의 잠금 기반 방식에서는 다음과 같이 커밋 처리 시점이 전혀 겹치지 않은 두 트랜잭션은 병렬로 실행 될 수 없었습니다.
Tx1 : -P----bin_write-------bin_fsync----Engine_Commit-->
Tx2 : ---P----bin_write-----bin_fsync----Engine_Commit-->
Tx2 : -----P----bin_write---bin_fsyncC---Engine_Commit-->
P : Prepare
[그림1]
위의 그림1를 보면 그룹 커밋의 대상이 되는 트랜잭션은 모두 Prepare 상태가 되어 있습니다. Prepare가 되었다는 것은 트랜잭션에서 변경을 처리하는 행의 변경(업데이트 또는 삭제)이 완료되었음을 의미합니다.
여러 트랜잭션이 동시에 가능한 것은 같은 행이 아님을 의미하고, 즉 Row Lock으로 인한 경합이 발생하지 않았따는 것을 의미합니다.
만약 같은 행에 대해서 갱신을 하였다라면 트랜잭션은 Row Lock이 걸려서 대기하고 있는 상태 일 것이며, Lock 획득하고 있는(Lock Holder 스레드) 선행 트랜잭션이 종료(Commit의 완료 또는 Rollback)가 될 때까지 기다리고 있어야 할 것입니다.
어떠한 트랜잭션도 잠금에 의해 대기하지 않고 Prepare가 되었다는 것은 여러 트랜잭션이 같은 행을 변경하지 않았음을 의미하게 되는 것 입니다. 그러므로 여러 트랜잭션은 Replica 인스턴스에서 복제 동기화를 수행할 때 병렬로 동기화(적용)하여도 Lock 잠금 대기에 대한 걱정할 필요가 없이 병렬 복제가 가능할 수 있습니다.
그런데 Replica 인스턴스에서는 트랜잭션이 트랜잭션간의 Lock 경합을 하지 않고 병렬로 같이 진행할 수 있다는 정보를 알고 있어야 Worker thread 분배 등의 잘 처리될 수 있을 것입니다.
그래서 병렬 복제 동기화를 할 수 있는 이러한 정보를 Replica 인스턴스에게 제공을 해야 하고 그에 따라서 last_committed 와 sequence_number 라는 두가지 논리적 타임스탬프 정보를 바이너리 로그내에서 추가하여 함께 기록되게 됩니다.
두 값은 논리적인 카운터의 값을 가져오는 시점은 각각 다릅니다.
- sequence_number: 이것은 주어진 바이너리 로그의 첫 번째 트랜잭션에 대해 1, 두 번째 트랜잭션에 대해 2 입니다. 이러한 논리적 번호 매기기는 각 바이너리 로그 파일에서 1부터 다시 시작됩니다.
- last_committed: 현재 트랜잭션 이전에 커밋된 가장 최신의 트랜잭션의 sequence_number 값이 되며, 이 값은 항상 sequence_number보다 작습니다.
위의 설명과 같이 바이너리 로그가 새로운 파일로 변경되면(File Rotation) sequence_number는 1부터 시작되고, last_committed는 sequence_number보다 작기 때문에 0 부터 시작됩니다.
이 처럼 중요한 관점은 트랜잭션의 병렬 실행이 가능할지를 판단하는 기준은 last_committed와 sequence_number의 오버랩 여부, 같은 윈도우 내에 있는지 여부입니다.
PREPARE : P1 COMMIT : C1
| |
TRX1 | |
--------------------------------------------------->
| |
| <-- 오버랩 --> |
| (같은 윈도우) |
PREPARE : P2 | COMMIT: C2
TRX2 | | |
---------------------------------------------------->
[그림2]
위의 그림2에서 두 트랜잭션 TRX1,TRX2가 있다고 할 경우 각각의 last_committed 와 sequence_number는 P1, P1 그리고 P2,C2 로 표현 하고 있습니다.
트랜잭션 TRX1가 먼저 COMMIT 된 상황의 예시이며, 이 트랜잭션 범위 중에서 오버랩되는 관계는 P1<=P2 그리고 P2 <=C1 인 경우 입니다.
이런 경우에 동시에 PREPARE된 시간대, 즉 트랜잭션의 변경 시점이 같은 윈도우(Window)에 있다고 볼 수 있고, 같이 병렬 처리가 가능한 같은 윈도우내에 있다고 표현할 수 있을 것 같습니다.
이와 같이 같은 윈도우내에서 또는 이와 같은 오버랩 별로 병렬 처리를 한다라는 의미를 다시 생각을 해보면 LOGICAL CLOCK 방식에서는 Source 인스턴스에서는 모아서(그룹화) binlog에 기록하는 바이너리 로그 그룹 커밋 기능이 필요함을 의미하고, 그룹 커밋이 일어나지 않는다면 병렬처리는 사실상 불가능 해집니다.
각 트랜잭션 별로 COMMIT과 바이너리 로그에 개별적으로 작성되었을 경우 Replica 인스턴스에서도 모아서 병렬처리가 불가능 하기 때문입니다.
그래서 생각해볼 부분으로는 Source 인스턴스에서 오버랩 되는 COMMIT, 같이 병렬 처리 가능한 단위로 묶을 수 있는 트랜잭션을 어떻게 늘릴 수 있는지에 대한 고민일 것입니다.
그래서 멀티스레드 복제의 잘 사용하고 위해서는(사용성을 높이기 위해서는) 바이너리 로그 그룹 커밋 설정을 조정(튜닝)해야 합니다.
이 부분은 뒤에서 다시 설명하도록 하겠습니다.
Replica 인스턴스에서 복제 동기화시에 Source 인스턴스로 부터 전달받은 오버랩된 여러 트랜잭션에 대해서 Source 인스턴스와 같은 순서로 복제가 된다고 보장을 단정 지을 수는 없습니다.
예를 들어 Source 인스턴스에서 조금 더 뒤에(나중에) COMMIT을 트랜잭션이 처리량이 많고 오래 걸리는 상황이 일어날 수도 있으며, 이 처럼 Source 인스턴스와 Replica 인스턴스의 트랜잭션 COMMIT 순서가 바뀌게 될 경우 바뀐 COMMIT 순서에 따라서 데이터의 정합성의 문제 또는 쿼리 결과가 달리지거나 릴레이 로그에서 실행된 트랜잭션의 시퀀스 간격이 생기는등에 대해서 걱정을 할 수도 있습니다.
그래서 LOGICAL_CLOCK 방식이 추가되면서 같이 추가된 기능(파라미터)이 slave_preserve_commit_order 입니다.
이 파라미터를 활성화 하면(ON) Replica 인스턴스에서 여러 Worker thread 가 동작하여 각각 여러 변경 이벤트를 동시에 처리하여도 릴레이 로그에서에 기록된 순서대로 실행된 트랜잭션 시퀀스의 간격을 방지하고 복제본에서 원본과 동일한 트랜잭션 기록을 보존합니다.
즉, slave_preserve_commit_order 파라미터는 Source 인스턴스에서 커밋된 순서를 Replica 인스턴스에서도 같은 순서로 처리되도록 하는 설정입니다.
기능 사용의 예시
Replica 인스턴스에서 트랜잭션을 멀티 스레드로 처리하는 과정에서 트랜잭션의 순서가 잘못될 수도 있습니다.
그에 따라서 Source 인스턴스에는 존재하지만, Replica 인스턴스에는 존재하지 않은 상태 또는 조회시에 Source 인스턴스에서의 조회결과와 Replica 인스턴스에서의 조회 결과가 달라질 수도 있습니다.
보통의 경우 문제가 되지 않을 수 있으나, 사용하는 애플리케이션에 따라서 해당 애플리케이션이 트랜잭션의 커밋 순서에 의존하여 처리하는 경우 문제가 발생할 수 있습니다.
[Source 인스턴스]
S1 : T1 테이블에 1을 입력
S2 : T1 테이블에 2을 입력
S3 : T1 테이블을 조회(select * from T1)
위의 명령어가 병렬로 실행이 되고 S1(세션1)의 트랜잭션이 커밋을 하기전에 S2의 트랜잭션이 먼저 커밋을 하였다고 가정합니다.
S3(세션3)에서 조회시 다음과 같은 결과 중 하나를 얻게 됩니다.
- S1 및 S2 커밋전에 조회를 한 경우 T1의 조회결과는 없음
- S1이 커밋된 후 S2가 커밋되기전에 조회를 한 경우는 조회결과는 1이 확인됨
- S1과 S2 모두 커밋된 이후 조회한 경우는 1과 2 모두 확인할 수 있음
[Replica 인스턴스]
Replica 인스턴스에서는 다른 순서로 커밋이 될 수 있습니다.
W1 : T1 테이블에 1을 입력
W2 : T1 테이블에 2을 입력
S3 : T1 테이블을 조회(select * from T1)
W2(Worker thread2)의 트랜잭션을 커밋하기 전에 W1가 트랜잭션을 커밋하였다고 가정을 합니다. S3(세션3)에서 조회시 다음과 같은 결과 중 하나를 얻게 됩니다.
- W1 및 W2 커밋전에 조회를 한 경우 T1의 조회결과는 없음
- W2(워커 스레드2)가 커밋된 이후 W1이 커밋되기전에 T1을 조회한 경우는 조회결과는 1이 확인됨 <!!--문제
- W1과 W2 모두 커밋된 이후 조회한 경우는 1과 2 모두 확인할 수 있음
이와 같이 애플리케이션 또는 클라이언트에서 쿼리시 Source 인스턴스와 Replica 인스턴스의 중간 상태가 동일해야 하는 경우 slave_preserve_commit_order를 ON 으로 설정해서 사용해야 합니다.
해당 파라미터의 설정의 변경시 이미 복제 동기화가 활성화 중이라면 복제를 중지 후에 파라미터를 변경하고 다시 복제를 시작해야 합니다.
또한 해당 파라미터는 멀티 스레드 복제의 방식 중에서 LOGICAL_CLOCK 방식과 연관이 되어있는 파라미터로 LOGICAL_CLOCK 으로 사용할 경우 영향을 받습니다.
slave_preserve_commit_order 파라미터의 기능적 특성 및 버전별 변경 사항에 대해서 다음과 같습니다.
- MySQL 8.0.19 버전부터는 Replica 인스턴스에서 slave_preserve_commit_order=ON 설정하기 위해서 바이너리 로그 및 log_savle_updates 활성화는 필요하지 않습니다.
활성화 하지 않아도 slave_preserve_commit_order=ON 으로 설정 가능 합니다. - 모든 릴리스에서 slave_message_commit_order=ON 사용하려면 slave_parallel_type이 Logical_CLOCK 으로 설정되어 있어야 합니다.
- slave_preserve_commit_order 파라미터는 MySQL 8.0.26 버전에서 파라미터명이 replica_preserve_commit_order 으로 대체 되었습니다.
- MySQL 8.0.27 이전 버전까지는 기본값은 OFF 이며, 8.0.27 버전 부터 기본값이 ON 으로 변경되었습니다.
- MySQL 8.0.27부터는 Replica 인스턴스에 대해 멀티스레딩이 기본적으로 활성화되어 있으므로(기본적으로 slave_message_workers=4) slave_message_commit_order의 기본값은 ON이고, slave_slave_type 파라미터의 기본값도 LOGICAL_CLOCK 입니다.
- MySQL 8.0.27부터는 slave_parallel_workers가 1로 설정된 경우에 slave_preserve_commit_order(또는 replica_preserve_commit_order) 설정이 무시됩니다. slave_parallel_workers가 1로 설정된 경우 트랜잭션 순서가 보존되기 때문입니다.
그룹 커밋 싱크 주기
MySQL의 멀티 스레드 복제와 바이너리 그룹 커밋은 아주 밀접한 관계가 있으며, 이전에 설명한 내용으로 Replica 인스턴스에서 병렬 처리를 하기 위해서는 병렬 처리가 가능하게끔 Source 인스턴스에서 트랜잭션이 모아서(그룹화 하여) Replica 인스턴스로 전달해주는 부분이 관건이라고 할 수 있습니다.
Source 서버의 트랜잭션이 많지 않거나 오버랩 된 트랜잭션이 많지 않을 경우 복제 동기화시 멀티 스레드 사용으로 인한 효과를 보기가 어렵거나 미비할 수밖에 없습니다. 그래서 Source 인스턴스에서는 바이너리 그룹 커밋에 대해서 보다 많은(가급적 많은) 트랜잭션이 하나의 그룹으로 묶이도록 해야할 필요성이 있습니다.
그와 관련된 파라미터가 binlog_group_commit_sync_delay 와 binlog_group_commit_sync_no_delay_count 파라미터이고 설정에 따라서 그룹 커밋되는 트랜잭션의 수를 늘릴 수 있습니다.
해당 파라미터는 Source 인스턴스에서 트랜잭션의 처리 속도(커밋 속도)에 대해서 일부분 느리게 처리하는 대신에 바이너리 로그에 대한 쓰기 부하를 줄이고(I/O 부하 감소), Replica 인스턴스에서는 더 많은 병렬 복제 동기화를 할 수 있는 방법이라고 할 수 있습니다.
해당 값을 더 크게 증가하여 늘리게 된다면 Source 인스턴스에서 실행되는 애플리케이션(또는 클라이언트)의 트랜잭션 처리가 늦어지게 되어서 영향 또는 문제가 될 수도 있기 때문에 적절한 파라미터 값의 설정이 필요 합니다.
너무 과도 하게 해서도 그렇다고 너무 적게 해서도 않되기 때문에 데이터베이스의 로드의 정도 및 시스템 클래스를 고려하여 파라미터의 설정 및 추가적이 모니터링을 통해 다시 파라미터 값의 변경 등으로 시스템에 맞는 적절한 값을 찾는 과정은 필요할 것으로 생각 됩니다.
WRITESET 방식
WRITESET 기반 방식은 MySQL 5.7.22 과 8.0.1 버전에서 도입된 방식으로, 트랜잭션의 커밋 처리 시점이 아닌 트랜잭션이 변경한 데이터를 기준으로 병렬 처리 가능 여부를 결정하는 기능입니다.
기존(기본값: COMMIT_ORDER) 기반 방식에서는 이전에 설명과 같이 트랜잭션간 커밋 시점(Window)가 동일한, 즉 오버랩 된 트랜잭션에 대해서 Replica 인스턴스에서 병렬로 복제를 처리할 수 있으며, 반대로 커밋 시점이 오버랩 되지 않은(겹치지 않은) 트랜잭션은 병렬로 실행될 수 없었습니다.
MySQL 8.0.1이 출시되면서 멀티스레드 복제에 대해서 변경하는 데이터를 기반(기준)으로 트랜잭션의 종속성(transaction dependencies)을 추적하는 새로운 방법이 도입되었으며, 그에 따라서 오버랩 되지 않은 트랜잭션도 Replica 인스턴스에서 병렬 복제 처리를 적용할 수 있게 되었습니다.
기존의 잠금 기반 방식에서는 다음과 같이 커밋 처리 시점이 전혀 겹치지 않은 두 트랜잭션은 병렬로 실행될 수 없었습니다.
WRITESET 기반 방식에서는 여러 트랜잭션이 서로 다른 데이터를 변경하는 경우 Replica 인스턴스에서 복제를 병렬로 처리할 수 있게 하는 기능입니다.
즉, 커밋 시점이 오버랩 되지 않아도 동일한 데이터를 변경하지 않은 트랜잭션들은 Replica 인스턴스에서 병렬로 복제 처리가 가능함을 의미입니다.
WRITESET 에 대한 이해를 돕기 위해 다음과 같은 상황을 예시로 같이 확인해보도록 하겠습니다.

[그림3]
위 그림3의 워크로드는 Replica 인스턴스에서 실행되면 T1과 T2를 병렬로 실행한 다음 T3만 복제를 실행하고 그 다음 T4와 T5를 병렬로 실행하고 그 다음 T6만 실행하고 마지막으로 T7과 T8을 함께 실행할 수 있습니다.
Source 인스턴스에서 WRITESET 방식을 사용하여 트랜잭션 종속성 추적을 사용하는 경우 해당 Write Set은 시간이 지남에 따라 최대 기록 크기까지 보존된 다음 이를 기반으로 종속성 정보가 생성됩니다.
간단히 말씀드리면, 트랜잭션이 Hash Set으로 표현되고, 두 개의 다른 트랜잭션 집합이 겹치는 경우 해당 트랜잭션들은 겹치는 행을 변경한 것을 의미합니다.
따라서 WRITESET을 사용하면 다음과 같이 Replica 인스턴스에서 워크로드를 실행할 수 있습니다.
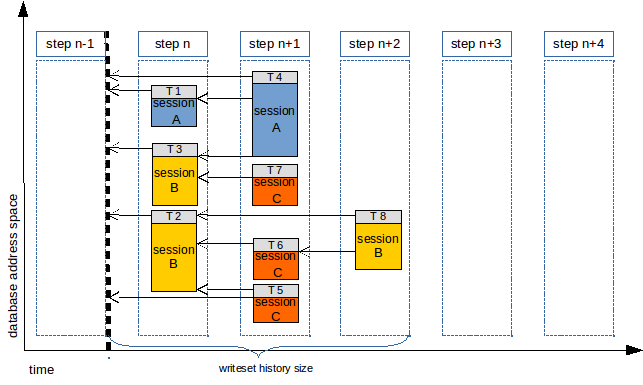
[그림4]
그림4를 참조하면 WRITESET을 사용하여 5단계에서 3단계로 줄일 수 있습니다.
그렇다면 T3가 Replica 인스턴스에서 T2보다 먼저 커밋 되거나, T5가 T7보다 먼저 커밋되면 Replica 인스턴스는 Source 인스턴스에서 볼수 있는 데이터와 다른 데이터 결과를 볼 수 있는 확율이 물론 있게 됩니다.
이 부분은 위에서 slave_preserve_commit_order 설명하는 과정에서의 내용과 동일 하며, slave_preserve_commit_order=ON 으로 설정하여 Source 인스턴스의 트랜잭션 커밋 순서대로 Replica 인스턴스에서도 반영 순서를 동일하게 맞출 수 있습니다.
추가적으로 WRITESET_SESSION 에 대한 내용은 다음 챕터에서 설명합니다.
WriteSet 기반에서는 WRITESET 과 WRITESET_SESSION 나뉘게 되며 binlog_transaction_dependency_tracking 파라미터에서 설정할 수 있습니다.
binlog_transaction_dependency_tracking 파라미터는 COMMIT_ORDER, WRITESET , WRITESET_SESSION 세개의 값을 설정할 수 있습니다.
- COMMIT_ORDER : binlog_transaction_dependency_tracking 파라미터의 기본값으로 COMMIT 시점이 오버랩 되는(같은 윈도우내) 트랜잭션을 병렬처리 할 수 있습니다.
- WRITESET : 서로 다른 데이터를 변경한 트랜잭션들은 병렬로 처리할 수 있으며 Logical timestamp는 COMMIT_ORDER를 기반으로 계산되며 last_committed 에 대해서는 Hash history 테이블을 사용해서 값을 설정해서 사용합니다.
- WRITESET_SESSION : 기본 동작은 WRITESET과 동일하며, 동일한 세션에서 실행한 트랜잭션은 병렬 복제 처리를 할 수 없다는 것이 차이점입니다.
WriteSet 기반의 방식에서는 커밋 시점이 달라도(오버랩 되지 않아도) 각 트랜잭션에서 변경한 데이터를 기준으로 트랜잭션간의 종속 관계를 정의하고 추적하는 기능을 사용하고 있습니다.
이를 위해서 내부적으로 변경된 데이터들의 목록을 관리하며, 트랜잭션에 의해 변경된 데이터들의 Hash를 적용한 것이 WriteSet 이라고 합니다.
WriteSet 기반 방식에서는 각 트랜잭션에서 변경한 데이터를 기준으로 병렬 처리를 위한 트랜잭션들의 종속 관계를 정의하므로 이를 위해 내부적으로 트랜잭션에 의해 변경된 데이터들의 목록을 관리합니다.
이 변경된 데이터들은 하나 하나가 전부 해시값으로 표현되는데, 이 해싱된 변경 데이터를 WRITESET 이라고 합니다.
WRITESET을 생성할 때 사용되는 해시 알고리즘은 transaction_write_set_extraction 파라미터에서 설정할 수 있으며 OFF,MURMUR32, XXHASH64 세 가지 값을 설정할 수 있으며 기본값은 XXHASH64 입니다.
MySQL 8.0.26 버전부터 transaction_write_set_extraction 파라미터는 Deprecated가 되었으며, 향후에 해당 파라미터는 제거될 예정 이고 8.0.26 버전 부터는 XXHASH64 만 사용한다고 이해하면 될 것 같습니다.
XXHASH64 설정은 그룹 복제(Group Replication)에서도 필요하며, 트랜잭션의 쓰기를 추출 과정이 그룹의 모든 멤버에서의 충돌 감지 및 인증에 사용됩니다.
binlog_transaction_dependency_tracking이 WRITESET 또는 WRITESET_SESSION으로 설정할 경우 transaction_write_set_extraction이 OFF를 할 수 없습니다.
또한 binlog_transaction_dependency_tracking의 현재 값이 WRITESET 또는 WRITESET_SESSION인 동안 transaction_write_set_extraction의 값을 변경할 수 없습니다.
트랜잭션에 의해 변경된 데이터들을 transaction_write_set_extraction 파라미터에서 설정한 알고리즘으로 Hash화 되어 MySQL 내부의 메모리 영역에서 테이블로 히스토리가 관리됩니다.
binlog_transaction_dependency_history_size 파라미터를 통해서 히스토리 테이블에서 저장할 수 있는 해싱 데이터(WRITESET) 개수를 정할 수 있으며, 기본값은 2500 입니다.
해시 수가 파라미터 설정 값에 도달하면 기록은 제거(purge) 됩니다.
WriteSet(WRITESET 또는 WRITESET_SESSION) 방식도 COMMIT_ORDER와 동일하게 바이너리 로그에 트랜잭션 정보와 last_committed 값과 sequence_number 값 정보가 기록됩니다.
WriteSet(WRITESET 또는 WRITESET_SESSION) 방식에서도 트랜잭션의 커밋을 처리할 때 last_committed 값에 대해서 먼저 COMMIT_ORDER를 기반으로 계산되며 last_committed 에 대해서는 Hash history 테이블을 사용해서 값을 설정해서 사용합니다.
WRITESET_SESSION
WRITESET_SESSION의 기본 동작은 WRITESET과 동일하며, 동일한 세션에서 실행한 트랜잭션은 병렬 복제 처리를 할 수 없다는 것이 차이점입니다.
이전에서 slave_preserve_commit_order 과 WRITESET에 대한 내용을 설명하면서 slave_preserve_commit_order=ON이 필요한 내용에 대해서 설명하였습니다.
slave_preserve_commit_order=ON 으로 설정하는 대신 WRITESET_SESSION을 사용하는 것으로 WRITESET_SESSION는 동일한 세션의 트랜잭션이 병렬로 실행되는 것을 허용하지 않는 기능입니다.
WRITESET_SESSION을 사용하였을 경우 Replica 인스턴스에서 트랜잭션 적용 순서는 다음과 같습니다.

[그림5]
위의 그림5에서 확인할 수 있듯이 Session B에 해당하는 T2 와 T3이 WRITESET 일 경우와 다르게 같은 Step이 아닌 다른 Step 으로 존재하는 것을 확인할 수 있으며, 동일하게 Session C의 경우도 T5,T6,T7가 다른 Step 에서 실행되고 있음을 확인할 수 있습니다.
이와 같은 WriteSet 기반 방식 사용하기 위해서는(데이터를 Hash 하여 write set 으로 만들기 위해서) 데이터의 행을 올바르게 식별하기 위해 기본키(PK) 또는 고유키(Unique Key)가 반드시 있어야 하며, 없을 경우 WRITESET의 이점을 얻을 수 없습니다.
여러 가지 다른 이유들로 인해, DDL을 포함하는 트랜잭션이나 외래 키 관계에서 부모 테이블에 접근하는 트랜잭션, 그리고 비어 있거나 부분적인 writeset만을 가지는 트랜잭션에서도 WRITESET의 이점을 얻을 수 없습니다.
WriteSet 기반 방식에서는 Replica 인스턴스에서의 트랜잭션 병렬 처리가 소스 서버에서 동시에 커밋되는 트랜잭션 수에 의존적이지 않으므로 그룹 커밋되는 트랜잭션 수를 늘리기 위해 의도적으로 파라미터를 과도하게 설정하여 소스 서버의 트랜잭션 커밋 처리 속도를 저하시킬 필요는 없습니다.
다만, 바이너리 로그 쓰기의 성능과 관련하여 바이너리 로그 그룹 커밋의 사용은 필요 합니다. 위의 내용에 따라서 트랜잭션 커밋 처리 속도를 의도적으로 지연시키지 않기 위해 바이너리 그룹 커밋과 관련된 파라미터를 사용하지 않는다면(아에 지연하지 않는다면) 바이너리 로그 쓰기의 성능과 관련하여 저하가 발생할 수도 있습니다.
그러므로 과도하게 지연 설정은 하지 않더라도 바이너리 로그 쓰기 성능을 고려하여 binlog_group_commit_sync_delay 와 binlog_group_commit_sync_no_delay_count 파라미터의 적절한 설정은 필요 합니다.
Performance
MySQL Team에서는 WRITESET 및 WRITESET_SESSION 종속성 추적 사용의 이점을 평가하기 위해 MySQL 8.0.1의 COMMIT_ORDER와 비교하는 일련의 벤치마크를 수행하였으며 아래는 차트의 내용입니다.
다음 차트는 마스터에서 세 가지 Sysbench 워크로드(OLTP 읽기/쓰기, 쓰기 전용 및 인덱싱된 열 업데이트)를 실행한 후 얻은 적용자 처리량을 나타냅니다.
워크로드는 Replica 인스턴스의 어플라이어가 중지된 상태에서 Source 인스턴스에서 100만 트랜잭션을 적용하는데 걸리는 실행 시간을 측정하여 트랜잭션 또는 초당 업데이트의 어플라이어 처리량을 계산했습니다.
로컬 SSD 디스크에 저장된 16개의 테이블과 800만 행이 있는 데이터베이스를 사용하여 Xeon E5-2699-V3 기반 시스템의 16개 프로세서 코어에 바인딩된 16개의 슬레이브 적용 스레드가 단독으로 실행(로컬 릴레이 로그 사용)되었습니다.
접근 방식의 잠재력을 최대한 보여주고 스토리지 시스템의 지연을 허용하지 않기 위해 바이너리 로그는 내구성 설정 없이 구성되었습니다.



Observations & Conclusions
Main observations
1. 현재 종속성 추적 체계(COMMIT_ORDER)를 사용하면, Source 인스턴스의 클라이언트 수가 적은 경우 (Sysbench RW에서 16 이하, Sysbench 업데이트 인덱스에서 4 이하) Replica 인스턴스에서 별렬 어플라이어를 사용하면 동일한 순간에 잠금이 설정된 트랜잭션을 찾을 기회가 거의 없기 때문에 이점이 적습니다.
2. WRITESET 종속성 추적을 사용하는 경우 Source 인스턴스의 모든 클라이언트 구성에서 Replica 인스턴스의 최대 어플라이어 처리량에 도달합니다. 실제로 Source 인스턴스에 단일 클라이언트가 있더라도 Replica 인스턴스의 처리량은 256 개의 스레드를 COMMIT_ORDER와 함께 사용할 때보 다 약간 높습니다.
3. COMMIT_ORDER와 마찬가지로 WRITESET_SESSION은 Source 인스턴스의 클라이언트 수에 따라 다릅니다. 그러나 훨씬 적은 수의 클라이언트에서 더 높은 처리량에 도달하여 두 개의 클라이언트가 사용된 후에도 상당한 이득을 제공하고 단 4개의 클라이언트에서 두 배 이상의 처리량을 확인할 수 있습니다.
Conclusions
위의 차트에서 볼 수 있듯이 트랜잭션 쓰기 집합을 기반으로 하는 마스터에서 종속성 추적을 사용하면 슬레이브 적용자 병렬 처리를 크게 개선할 수 있습니다.
Replica 인스턴스에서 어플라이어의 처리량은 더 이상 병렬로 실행될 수 있는 트랜잭션을 추적하기 위해 실행 순서에만 의존하지 않습니다.
Source 인스턴스의 클라이언트 수와 관계없이 거의 최대 처리량을 제공하고, 더 큰 그룹 커밋의 이점을 얻기 위해 Source 인스턴스에서 스로틀링이 필요하지 않으며, 중간에 Source 인스턴스가 있는 체이닝 복제 환경에서 이전과 다르게 하위 계층의 Replica 인스턴스로 내려가도 병렬 처리량을 유지할 수 있습니다.
또한 이 기능을 사용하면 Source 인스턴스의 단일 스레드 워크로드 인 경우에도 Replica 인스턴스 어플라이어(applier)는 최대 용량으로 실행할 수 있으므로 그룹 복제 환경에서는 중지되거나 복구하는 과정에서 Replica 인스턴스가 더 빠르게 따라잡을 수 있습니다.
Source 인스턴스의 클라이언트 수가 적을 때 Replica 인스턴스에서 처리량을 크게 향상시킬 수 있습니다.
WRITESET 방식에서는 Replica 인스턴스에서의 트랜잭션 병렬 처리의 범위(량)가 Source 인스턴스에서의 동시에 커밋되는 트랜잭션 수(오버랩)에 의존적이지 않으므로, 오버랩 구간을 늘리기 위해서 바이너리 그룹 커밋되는 트랜잭션 수를 증가시키기 위해서 관련 파라미터를 과도하게 증가 설정하여 Source 인스턴스의 트랜잭션 커밋 속도를 임의적으로 늦게 할 필요는 없습니다.
다만, 바이너리 로그 쓰기의 성능과 관련하여 바이너리 로그 그룹 커밋의 사용은 필요 합니다. 위의 내용에 따라서 트랜잭션 커밋 처리 속도를 의도적으로 지연시키지 않기 위해 바이너리 그룹 커밋과 관련된 파라미터를 사용하지 않는다면(아에 지연하지 않는다면) 바이너리 로그 쓰기의 성능과 관련하여 저하가 발생할 수도 있습니다.
그러므로 과도하게 지연 설정은 하지 않더라도 바이너리 로그 쓰기 성능을 고려하여 binlog_group_commit_sync_delay 와 binlog_group_commit_sync_no_delay_count 파라미터의 적절한 설정은 필요 합니다.
Reference
Reference URL
• mysql.com/preserve-masters-commit-order-on-slave
• mysql.com/improving-parallel-applier-writeset-based-dependency-tracking
• mysql.com/replication-options-binary-log
• mysql.com/worklog/id=9556
관련된 다른 글




Principal DBA(MySQL, AWS Aurora, Oracle)
핀테크 서비스인 핀다에서 데이터베이스를 운영하고 있어요(at finda.co.kr)
Previous - 당근마켓, 위메프, Oracle Korea ACS / Fedora Kor UserGroup 운영중
Database 외에도 NoSQL , Linux , Python, Cloud, Http/PHP CGI 등에도 관심이 있습니다
purityboy83@gmail.com / admin@hoing.io
