








Last Updated on 10월 29, 2023 by Jade(정현호)
안녕하세요
이번 포스팅에서는 InnoDB Cluster(클러스터) 에 대해서 InnoDB 의 아키텍처 및 구성 및 설정에 관해서 확인해보도록 하겠습니다.
Contents
InnoDB Cluster 아키텍처
MySQL 은 아주 예전 버전 부터 복제(Replicaiton) 기능을 사용하여 서비스 영속성 또는 서비스 고 가용성을 구현 또는 실현할 수 있었으며, 이러한 복제 기능은 오래 되었으며 그에 따라 성숙하고, 매우 유연하고 계속 기능이 추가되고 있어서 MySQL 의 복제 기능은 어느 RDBMS 보다 훌륭한 복제 기능을 제공하고 있다고 할 수 있습니다.
다만 Master(Source) - Replica 구조의 복제 구성 그 자체만으로는 실제로 높은 고가용성이나 서비스 영속성을 구현할 수 있는 것은 아니었으며, MySQL 복제 기능 자체적으로는 HA 기능 또는 Failover 기능을 제공하지 않았기 때문에 Master(Source) 인스턴스에 장애가 발생하게 된다면, 그 다음으로는 관리자(DBA) 가 여러 작업을 통해서 복구 또는 Failover 등을 별도로 실행해야 했습니다. 또한 다중의 Replica 노드에 대한 부하 분산의 경우도 별도의 네트워크 장비나 솔루션 또는 기타 방법으로 아키텍처 구현이 필요로 했던 부분이 있습니다.
그래서 실제로 Master(Source)에서 장애가 발생되었고, 장애의 발생 내역에 따라서 다시 정상적으로 서비스가 되기까지 오랜 시간이 걸리는 경우도 있을 수 있었습니다.
그래서 MySQL 인스턴스의 장애를 감지하고 자동화하여 장애처리 및 Failover 등을 할 수 있는 프로그램이나 스크립트 등을 별도로 구현하거나 알려진 HA 솔루션을 통해 고가용성을 구현하였으며, 주로 많이 사용되는 솔루션으로 MHA, MMM, Orchestrator 등이 있습니다.
다만 MySQL 자체 내장된 추가 기능이나 MySQL 에서 제작한 솔루션이 아닌 부분으로 MySQL 이 버전이 변경되거나 사용하는 환경에 맞게끔 소스를 수정해서 사용해야 할 경우도 있을 수 있습니다.
즉 여러모로 관리 비용 또는 리소스가 투자된다고 할 수 있습니다.
InnoDB Cluster 는 MySQL 서버의 빌트인 형태의 HA 솔루션으로 도입되었으며, 조금 더 쉽고 편리하게 구성 및 안정적인 고가용성 구성을 할 수 있게 되었습니다. InnoDB Cluster 는 그 자체적으로 어떤 기능이라고 하기 보다는 고가용성 구성을 하기 위한 여러 구성요소의 집합된 개념이라고 설명할 수 있습니다.
InnoDB 클러스터는 최소 3개의 MySQL Server 인스턴스로 구성되며 고가용성 및 확장 기능을 제공하고 있으며, InnoDB 클러스터는 다음과 같은 MySQL 기술을 사용하고 있습니다.
MySQL 용 고급 클라이언트 및 코드 편집기인 MySQL Shell
- MySQL Shell 은 MySQL 용 고급 클라이언트 및 코드 편집기입니다.
- mysql 클라이언트 와 유사한 SQL 기능 외에도 MySQL Shell은 JavaScript 및 Python에 대한 스크립팅 기능을 제공하고 MySQL 작업을 위한 API를 포함 하고 있습니다.
- MySQL Shell 에 대한 추가적인 자세한 내용은 기존의 포스팅을 참조하시면 됩니다.
MySQL Group Replication
- MySQL 인스턴스의 고가용성을 제공하는 기능을 하며, InnoDB 클러스터는 그룹 복제 작업을 위한 프로그래밍 방식의 사용하기 쉬운 대안을 제공합니다.
- 복제 역할 이외에 복제에 참여하는 멤버에 대한 관리 역할을 담당합니다.
- 애플리케이션과 InnoDB 클러스터 간의 투명한 라우팅을 제공하는 경량 미들웨어 프로그램입니다.
- 클라이언트 나 애플리케이션에서 수행한 쿼리를 MySQL 로 전달하는 중간 프록시(Proxy) 역할을 하고 있습니다.
아래 이미지는 InnoDB Cluster 가 구성되는 Overview 이며, InnoDB Cluster 의 구성 요소 간에 어떻게 통신이 되고 연결되어 있는지를 간략하게 확인할 수 있습니다.
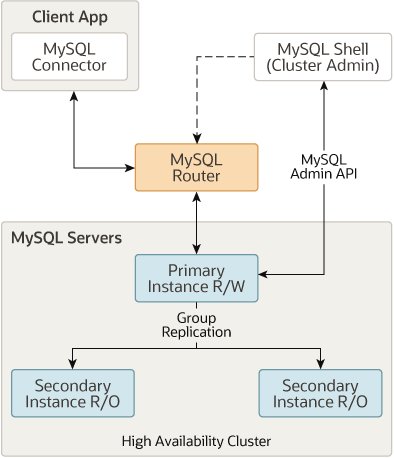
MySQL Group Replication 을 기반으로 구축되어 자동 구성원 관리, 내결함성, 자동 장애 조치 등과 같은 기능을 제공합니다.
InnoDB 클러스터는 일반적으로 하나의 기본 인스턴스(읽기-쓰기)와 여러 개의 보조 인스턴스(읽기 전용)가 있는 단일 기본 모드에서 실행됩니다. 기본 인스턴스는 MySQL 복제 구성에서 Master(Source) 인스턴스를 의미합니다.
고급 사용자는 모든 인스턴스가 기본 인 다중 기본 모드 를 활용할 수도 있습니다.
가능한 최고의 가용성을 보장하기 위해 InnoDB 클러스터가 온라인 상태일 때 클러스터의 토폴로지를 변경할 수도 있습니다.
InnoDB Cluster 는 명칭 그대로 MySQL 에서 사용 가능한 여러 스토리지 엔진 중에서 InnoDB 스토리지 엔진에서만 가능한 기능으로 이러한 그룹 복제를 사용하기 위해서는 최소 3대의 서버가 필요 합니다.
MySQL Shell의 일부로 제공되는 AdminAPI 를 사용하여 InnoDB 클러스터로 작업합니다. AdminAPI는 JavaScript 및 Python에서 사용할 수 있으며 고가용성 및 확장성을 달성하기 위해 MySQL 배포의 스크립팅 및 자동화에 매우 적합합니다.
MySQL Shell 의 AdminAPI를 사용하면 많은 인스턴스를 수동으로 구성할 필요가 없습니다. 대신 AdminAPI는 MySQL 인스턴스 세트에 효과적인 최신 인터페이스를 제공하고 하나의 중앙 도구에서 배포를 프로비저닝, 관리 및 모니터링할 수 있도록 합니다.
이러한 MySQL Shell 을 통해서 사용자나 운영자는 조금 더 손쉽게 InnoDB 클러스터를 생성하고 관리할 수 있으며, InnoDB Cluster 의 상태를 확인하거나 설정의 변경 등의 InnoDB에 대한 여러 가지 기능을 제공하고 있습니다.
InnoDB 클러스터는 인스턴스를 간단하게 프로비저닝할 수 있는 MySQL Clone 을 지원합니다.
과거에는 일련의 MySQL 인스턴스에 조인하기 전에 새 인스턴스를 프로비저닝하려면 어떻게든 트랜잭션을 조인 인스턴스로 수동으로 전송해야 했습니다. 여기에는 파일 복사본 만들기, 수동 복사 등이 포함될 수 있습니다. InnoDB 클러스터를 사용하여 클러스터 에 인스턴스 를 추가하기만 하면 자동으로 프로비저닝됩니다.
InnoDB Cluster 를 환경에서는 클라이언트나 애플리케이션이 직접 접속하여 쿼리를 수행하는 형태가 아니라 MySQL Router 에 접속하여 쿼리를 실행하게 되며 MySQL Router 는 Proxy 역할을 하게 됩니다.
MySQL Router 는 부트스트래핑 이라는 프로세스에서 InnoDB 클러스터를 기반으로 자동으로 구성할 수 있으므로 수동으로 라우팅을 구성할 필요가 없습니다. 그런 다음 MySQL 라우터는 클라이언트 애플리케이션을 InnoDB 클러스터에 투명하게 연결하여 클라이언트 연결을 위한 라우팅 및 로드 밸런싱을 제공합니다.
MySQL 서버의 장애가 발생 시 Group Replication 에서 감지를 하여 자동으로 문제가 감지된 서버를 복제 그룹에서 제외를 하게 되며, MySQL Router 에서는 해당 상황을 인지하여 자신이 보유한 정보를 갱신하여 클라이언트 나 애플리케이션에서 접속 및 실행 요청한 쿼리에 대해서 복제 그룹내 정상 동작하는 인스턴스로만 전달할 수 있도록 합니다.
클라이언트나 애플리케이션 입장에서는 별도의 조치나 설정의 변경 없이 매우 투명하게 그대로 사용하면 되는 것입니다.
MySQL 에 대해서 HA 구현을 위한 여러 3rd Party 솔루션이나 프로그램은 많이 있었으며, InnoDB Cluster 의 특징은 MySQL 에서 공식적으로 개발되어 제공되는 고가용성 솔루션으로 MySQL 서버와 같이 테스트 와 개발되고 MySQL Shell 과 같은 유틸리티에서도 기능이 연동된다는 점등 즉 MySQL 에서 빌트인으로 테스트 및 개발되어 배포된다는 점이 큰 장점입니다.
또한 MySQL 서버의 업데이트와 같이 계속적으로 기능 개선이나 Bug Fixed 이 되는 즉, 유지 보수(Support)가 되는 것이 큰 장점이라고도 할 수 있습니다.
추가 정보로 InnoDB Cluster 의 라이선스에 관해서는 Community Edition 에서도 사용 가능 합니다.
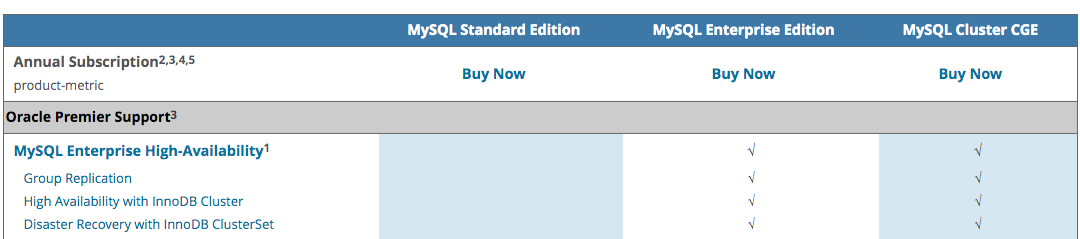
MySQL Enterprise High-Availability 에는 1 이라는 각주가 있는 것을 확인 할 수 있으나 그 외 1 이라는 각주가 표시가 없는 것을 확인할 수 있습니다. 1 에 대한 내용은 아래와 같습니다.
1 Certain Features only available in Commercial Editions.
라이선스나 Edition 정보에서 HA 부분은 기술지원이 가장 큰 부분입니다.
InnoDB Cluster의 경우 Community Edition 에서 사용이 가능합니다. 다만 HA 기술의 특성상 구성의 복잡도가 높고 문제가 발생했을때 자체적으로 대응이 어려운 부분이 많을 수 있기 때문에 기술 지원은 Enterprise Edition 에서 만 제공한다고 되고 있다고 합니다.
그리고 EE 의 경우 설치 바이너리 파일도 commercial 바이너리로 설치를 진행을 해야 합니다.
즉, Community Edition 으로 사용이 가능 합니다. 그리고 기술지원을 받기 위해서는 Standard Edition 이 아닌 Enterprise Edition 을 구매해야 한다는 의미가 됩니다.
Group Replication(그룹 복제)
Group Replication 은 기본적으로 한 번에 하나의 서버만 업데이트를 수락하는 자동 기본 선택(automatic primary election)을 통해 Single-Primary 모드로 작동하게 되며 또는 그룹을 다중 기본 모드(Multi Primary Mode)로 배포할 수 있습니다. 이 모드에서는 업데이트가 동시에 실행되더라도 모든 서버가 업데이트를 수락할 수 있습니다.
Group Replication 은 모든 서버에서 사용할 수 있는 그룹 멤버십 서비스를 제공하고 있으며, 서버는 그룹을 탈퇴하고 가입할 수 있으며 그에 따라서 멤버 구성은 계속 관리 유지됩니다. 때때로 서버가 예기치 않게 그룹을 떠날 수 있으며(장애 등에 의해서), 이 경우 실패 감지 매커니즘이 이를 감지하여 그룹에 알리게 되고 이러한 과정은 모두 자동으로 수행됩니다.
그룹 복제는 MySQL 서버 데이터베이스가 서비스를 지속적으로 할 수 있도록 하며, 그룹 구성원 중 하나를 사용할 수 없게 되면 해당 그룹 구성원에 연결된 클라이언트나 애플리케이션의 커넥션에 대해서 다른 그룹으로 리다이렉트(redirected) 나 다른 서버로의 장애 조치(failed over) 되어야 함을 이해하는 것이 중요하며, 그룹 복제에는 이와 같은 역할을 하는 미들웨어나 라우터 기능을 내장하고 있지는 않습니다. 이런 기능 또는 메서드(method) 는 MySQ Router 를 통해서 구현/사용할 수 있으며, 포스팅에서 계속 설명하고 있는 InnoDB Cluster 가 고가용성 구성을 위한 궁극적인 목표가 되게 됩니다.
그룹 복제는 MySQL 서버에서 플러그인 형태로 제공되며, 각 서버 인스턴스에서 플러그인을 구성(설치) 하고, 그룹을 시작하고 그룹을 모니터링을 합니다. MySQL 서버 인스턴스에서 그룹을 배포하고 관리하는 다른 방법으로 InnoDB 클러스터를 사용하는 것입니다.
그룹 복제의 배경
내결함성(fault-tolerant) 시스템을 만드는 가장 일반적인 방법은 구성 요소를 중복으로 만드는 것입니다. 즉, 구성 요소를 제거할 수 있고 시스템이 예상대로 계속 작동해야 합니다. 이것은 그러한 시스템의 복잡성을 완전히 다른 수준으로 높이는 일련의 문제를 만듭니다.
특히 복제된 데이터베이스는 하나가 아닌 여러 서버의 유지 관리 및 관리가 필요하다는 사실을 인지를 해야 합니다. 또한 서버가 함께 협력하여 그룹을 생성함에 따라 네트워크 파티셔닝 또는 스플릿 브레인 시나리오와 같은 몇 가지 다른 고전적인 분산 시스템 문제를 처리해야 합니다.
궁극적인 과제(목표)는 데이터베이스 및 데이터 복제가 논리적으로 일관되고 간단한 방식으로 여러 서버를 조정하는 논리와 융합하는 것입니다.
MySQL의 Group Replication(그룹 복제) 는 서버 간의 강력한 조정을 통해 분산 상태 머신 복제를 제공합니다. 서버는 동일한 그룹에 속해 있을 때 자동으로 조정됩니다.
Group Replication 은 MySQL 5.7.17 버전에 추가된 새로운 기능으로 데이터 일관성, 충돌 감지 및 해결, 그룹 멤버십 서비스가 모두 내장된 MySQL 서버 인스턴스 그룹 전체에 고가용성 분산 MySQL 서비스를 생성할 수 있는 새로운 MySQL 복제 기술입니다.
기본적으로 그룹 복제는 Primary 또는 Master 또는 Source 라고 하는 단일 서버 인스턴스(Single Server Instance) 가 쓰기 요청을 수락하는 단일 기본 모드(Single-Primary Mode) 에서 작동합니다. 또는 그룹을 다중 기본 모드(Multi Primary Mode)로 배포할 수 있습니다. 이 모드에서는 업데이트가 동시에 실행되더라도 모든 서버가 업데이트를 수락할 수 있습니다.
보조(Secondary) 또는 Replica 라고 하는 그룹의 나머지 서버 인스턴스는 Primary(Source) 인스턴스의 복제본 형태로 작동합니다. Primary(Source) 인스턴스에 예상치 못한 실패가 발생하는 경우 자동적으로 새로운 Primary(Source) 인스턴스 선출을 위한 선거가 진행되고 Secondary(Replica) 서버 중 하나가 새로운 Primary(Source) 로 선택되게 됩니다.
그룹 복제의 또 다른 장점이자 기능으로 기존 복제와 다르게 단방향으로 복제이외 복제 그룹내에서 서버들 간에 통신하면서 양방향으로 복제가 가능하기 때문에 모든 곳에서 업데이트 기능을 지원합니다. 즉 이 모드에서는 모든 구성원이 동일하며 그룹의 모든 MySQL Server 인스턴스에 읽기 및 쓰기를 분산할 수 있습니다.
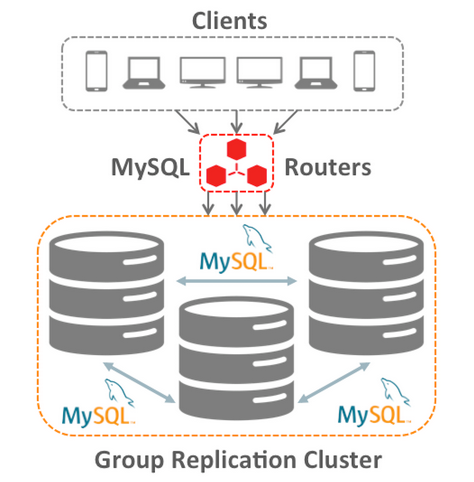
[mysql-group-replication-feature]
트랜잭션이 커밋되려면 그룹의 대다수가 글로벌 트랜잭션 시퀀스에서 주어진 트랜잭션의 순서에 동의해야 합니다.
트랜잭션 커밋 또는 중단(abort) 결정은 각 서버에서 개별적으로 수행되지만 모든 서버가 동일한 결정을 내립니다. 네트워크 분할이 있어 구성원이 합의에 도달할 수 없는 분할이 발생하면 이 문제가 해결될 때까지 시스템이 진행되지 않습니다. 따라서 내장된 자동 split-brain 보호 메커니즘도 있습니다.
그룹 복제 처리 방식
MySQL 그룹 복제에 대해 자세히 알아보기 전에 이번 섹션에서는 몇 가지 배경 개념과 작동 방식에 대한 개요를 확인해보도록 하겠습니다. 이것은 그룹 복제에 필요한 것과 기존 비동기식 MySQL 복제와 그룹 복제 간의 차이점을 이해하는 데 도움이 되는 몇 가지 컨텍스트를 확인할 수 있습니다.
기본 복제에서는 동기화 방식으로 분류를 한다면 비동기(Asynchronous Replication) 와 반동기(Semisynchronous Replication) 으로 분류할 수 있습니다.
아래 그림에는 이전의 비동기 MySQL 복제 프로토콜(및 반동기 변형도 포함)의 다이어그램이 있습니다. 서로 다른 인스턴스 사이의 화살표는 서버 간에 교환되는 메시지 또는 서버와 클라이언트 응용 프로그램 간에 교환되는 메시지를 나타냅니다.
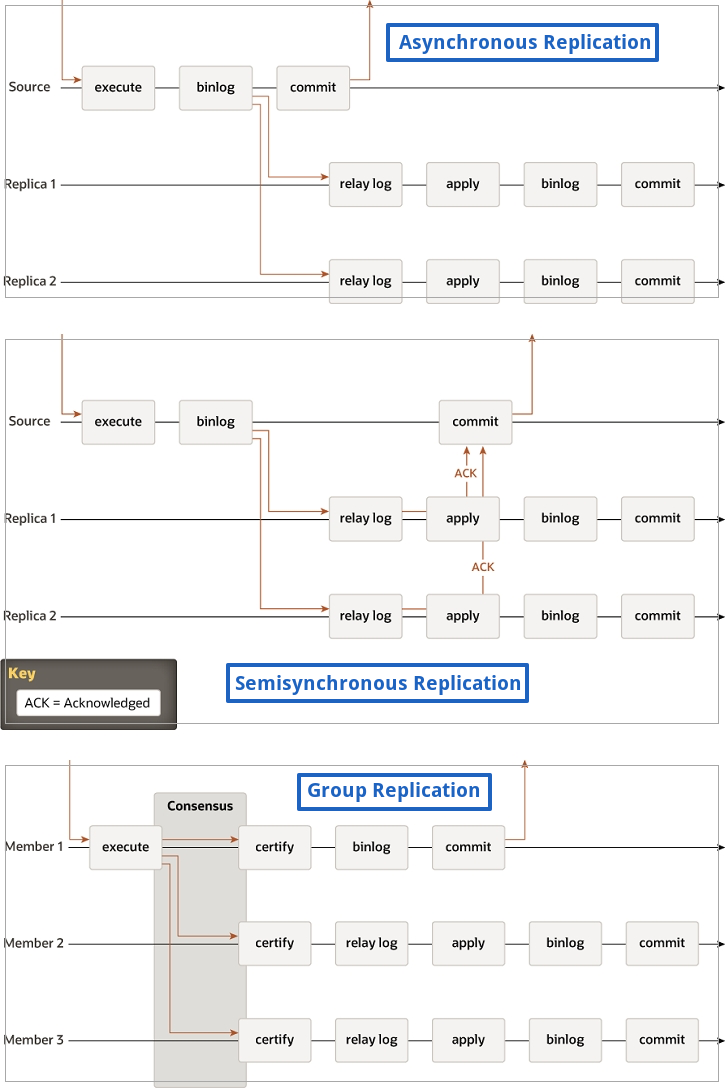
[MySQL Replication Technologies]
기본 MySQL 복제 프로토콜의 특성은 복제에 대한 간단한 기본 백업 접근 방식의 영역이었습니다. Primary(마스터, Source) 가 있고 하나 이상의 백업(Slave, Replica)이 있게 됩니다. Primary에서 트랜잭션을 실행하고 커밋을 한 다음 statement-based replication 또는 row-based replication 으로 다시 수행하게 되며 모든 서버에서는 기본적으로 데이터의 전체 복사본이 있는 시스템 유형으로 설계되어 있습니다.
Primary 와 Secondary 사이에 동기화 단계 프로토콜이 추가된 semisync 복제라고 하는 플러그인(반동기화 기능)으로 구현된 기능으로 Primary(Source) 인스턴스에서 트랜잭션 커밋 시 처리 중인 트랜잭션이 Secondary(Replica) 인스턴스로 전달이 잘 되었는지 확인 및 응답을 기다린 후 커밋을 처리하는 형태입니다.
그룹 복제는 내결함성 시스템을 구현하는 데 사용할 수 있는 기술입니다. 복제 그룹은 각각 고유한 전체 데이터 복사본(비공유 복제 체계)을 갖고 메시지 전달을 통해 서로 상호 작용하는 서버 집합입니다.
고급 데이터베이스 복제 솔루션을 구축하는 데 사용할 수 있는 매우 유용한 추상화로 변환되는 매우 강력한 속성입니다.
MySQL 그룹 복제는 이러한 속성과 추상화를 기반으로 하며 복제 프로토콜에 상관없이 다중 소스(multi-source) 업데이트를 구현합니다. 복제 그룹은 여러 서버로 구성되며 그룹의 각 서버는 언제든지 독립적으로 트랜잭션을 실행할 수 있습니다.
(Multi Primary Mode를 의미함)
그러나 모든 읽기-쓰기 트랜잭션은 그룹에서 승인한 후에만 커밋됩니다. 즉, 모든 읽기-쓰기 트랜잭션에 대해 그룹은 커밋 여부를 결정해야 하므로 커밋 작업은 원래 서버(트랜잭션을 수행한 원래(original) 서버)의 일방적인 결정이 아닙니다. 읽기 전용 트랜잭션은 그룹 내 조정이 필요하지 않으며 즉시 커밋합니다.
반동기(Semisynchronous Replication) 유사하게 커밋에 대해서 다른 멤버들이 트랜잭션을 수신하였는지 확인하는 단계가 존재를 하게 됩니다.
읽기-쓰기 트랜잭션이 원래 서버에서 커밋할 준비가 되면 서버는 쓰기 값(변경된 행)과 해당 쓰기 세트(업데이트된 행의 고유 식별자)를 원자적으로 브로드캐스트합니다. 트랜잭션은 원자적 브로드캐스트를 통해 전송되기 때문에 그룹의 모든 서버가 트랜잭션을 수신하거나 수신하지 않습니다. 수신하면 이전에 전송된 다른 트랜잭션과 동일한 순서로 수신됩니다. 따라서 모든 서버는 동일한 순서로 동일한 트랜잭션 세트를 수신하고 트랜잭션에 대해 글로벌 총 주문이 설정됩니다.
트랜잭션을 수신한 멤버가 그룹내에서 과반수 이상이라면(과반수 이상이 응답을 하였다면), 해당 트랜잭션에 대해서 인증(Certify) 처리를 하고 최종적으로 커밋을 처리하는 프로세스로 진행됩니다.
인증(Certify) 는 트랜잭션 커밋에 대해서 충돌 검사 과정을 의미하며 이러한 인증(Certify) 과정은 다른 Primary 와 계속 확인 과정을 진행함으로 트랜잭션 Commit 에 대한 overhead가 발생할 수 있습니다.
그룹 복제에서 트랜잭션 커밋을 처리 할때에는 과반수 이상의 멤버로 부터 응답을 받지 못한다면 트랜잭션은 그룹에 적용되지 않습니다. 기존의 반동기(Semisynchronous Replication) 와의 차이는 반동기(Semisynchronous Replication) 에서는 Secondary(Replica) 인스턴스로 부터 응답을 받지 못하였다고 해당 트랜잭션이 Primary(Source) 에서 적용되지 않은것은 아니었지만, Group Replication 에서는 그룹내 멤버들로 부터 응답에 결과에 따라서 결과가 달라진 다는 점이 차이가 있게 됩니다.
이전에 설명한 내용과 같이 트랜잭션이 커밋되려면 그룹의 대다수가 승인한 후에만 커밋 될 수 있습니다.
즉, 모든 읽기-쓰기 트랜잭션에 대해 그룹은 커밋 여부를 결정해야 하므로 커밋 작업은 트랜잭션이 시작한 원래 서버(Originating Server) 의 일방적인 결정이 아닙니다.
다만 조회만 하는 읽기 전용 트랜잭션(Read Only Transaction) 은 그룹 내 승인이나 합의 과정이 필요하지 않으며 즉시 커밋합니다.
이처럼 MySQL Group Replication 에서는 HA(고가용성)을 구성하고 유지관리하기 위한 여러 수동적인 작업이나 관리 포인트에 대해서 빌트인으로 기능 지원이 됨에 따라 사용 편리성이나 관리 비용(Cost) 을 낮출 수 있는 장점이 있습니다.
다음은 그룹 복제의 일반 사용 사례입니다.
-
탄력적 복제 - 매우 유동적인 복제 인프라가 필요한 환경으로 서버 수가 동적으로 증가하거나 축소되어야 하며 가능한 한 부작용이 적습니다. 예를 들어, 클라우드용 데이터베이스 서비스.
-
고가용성 샤드 - 샤딩은 쓰기 확장을 달성하기 위해 널리 사용되는 접근 방식입니다. MySQL 그룹 복제를 사용하여 각 샤드가 복제 그룹에 매핑되는 고가용성 샤드를 구현합니다.
-
비동기 소스-복제본 복제의 대안 - 특정 상황에서 단일 소스 서버를 사용하면 단일 경합 지점이 됩니다. 특정 상황에서는 전체 그룹에 쓰기가 더 확장될 수 있습니다.
-
자율 시스템 - 또한 복제 프로토콜에 내장된 자동화를 위해서만 MySQL 그룹 복제를 배포할 수 있습니다.
Group Replication Plugin Architecture
MySQL 의 그룹 복제는 MySQL 플러그인을 통해서 기능을 사용할 수 있으며, 각 서버 인스턴스 별로 설치를 해야 합니다.
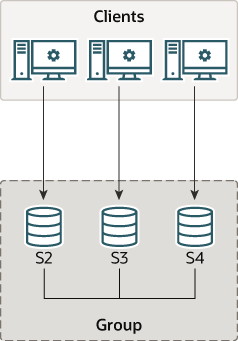
위의 그림과 같은 형태로 Group Replication 은 그룹에 참가한 인스턴스간에 Group Replication Plugin 기능을 사용하여 인스턴스간에 계속적인 통신과 복제를 수행하게 됩니다.
MySQL 그룹 복제는 바이너리 로그, 행 기반 로깅(row-based logging) 및 글로벌 트랜잭션 식별자(GTID)와 같은 기능을 활용하며 기존 MySQL 복제 인프라를 기반으로 동작으로 합니다.
성능 스키마(performance schema) 또는 플러그인 및 서비스 인프라 등은 현재 MySQL 프레임워크와 통합됩니다.
다음 그림은 MySQL 그룹 복제의 전체 아키텍처를 나타내는 블록 다이어그램을 나타냅니다.
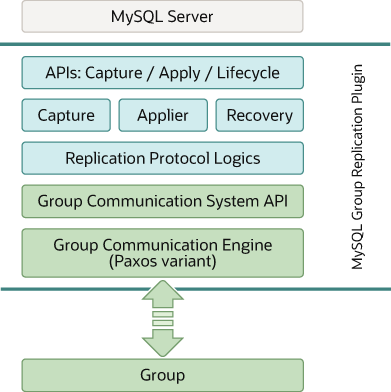
[Group Replication Plugin Block Diagram]
MySQL 그룹 복제 플러그인에는 플러그인이 MySQL 서버와 상호 작용하는 방식을 제어하는 캡처(Capture), 적용(Apply) 및 수명 주기용(Lifecyle) 이 API 세트에 포함되어 있습니다. 위의 이미지와 같은 최상단 Layer 에는 MySQL 서버와 통신하고 상호 작용을 위한 API 인터페이스가 준비되어 있습니다.
이러한 API 인터페이스는 그룹 복제 플러그인에서 MySQL Server 코어를 분리하고, 대부분 트랜잭션 실행 파이프 라인에 배치되는 후크 입니다. API 를 통해서 MySQL 서버에서 복제 플러그인으로 또는 반대 방향으로 요청이 상호 전달되게 됩니다.
MySQL 서버로 부터 서버 시작, 서버 복구, 서버 연결 수락 준비, 서버가 트랜잭션 커밋과 같은 이벤트에 대한 알림에 대해서 플러그인 방향으로 전달하게 됩니다.
다른 방향(반대 방향)인 플러그인에서 서버로는 진행 중인 트랜잭션 커밋 또는 중단과 같은 작업을 수행하도록 MySQL 서버로 지시 또는 전달하게 됩니다.
그룹 복제 플러그인 아키텍처 중 다음 계층은 실질적으로 그룹 복제를 수행하는 기능이 구현되어 있는 구성 요소 집합입니다.
해당 Layer 에는 몇 가지의 구성 요소가 있으며 API를 통해 들어온 요청에 대해서 적절히 목적에 맞는 구성요소로 전달하게 됩니다.
- 캡처(Capture) 구성 요소는 실행 중인 트랜잭션과 관련된 컨텍스트를 추적하는 역할을 합니다.
- Applier 구성 요소는 데이터베이스에서 원격 트랜잭션을 실행하는 역할을 합니다.
- 복구(Recovery) 구성 요소는 분산 복구를 관리하고 donor 를 선택하고 캐치업 절차를 관리하고 donor 실패에 대응하여 그룹에 합류하는 서버를 최신 상태로 유지하는 역할을 합니다.
스택을 계속해서 내려가면, 복제 프로토콜(replication protocol) 모듈에는 복제 프로토콜의 specific logic 이 포함되어 있으며, 충돌 감지를 처리하고 트랜잭션을 수신하여 그룹으로 전파합니다.
스택 더 아래에 그룹 복제 플러그인 아키텍처의 마지막 두 계층은 GCS(Group Communication System API) 와 Paxos 기반의 Group Communication Engine (XCom - eXtended COMmunications) 이 있습니다.
GCS API 는 복제된 상태의 머신을 구축하는 데 필요한 속성을 추상화하는 고급 API 입니다. 따라서 플러그인의 나머지 상위 계층(Layer) 에서 메세지 Layer 구현을 분리합니다
플러그인 상위 Layer 에서는 이 GCS API 를 통해서 Group Communication Engine 과 통신(상호작용)을 하게 되며, Group Communication Engine 은 Xcom 이라고도 하며, 복제 그룹(Replication Group) 의 구성원(members) 의 통신을 처리하는 매우 중요한 구성 요소입니다.
Group Communication Engine 은 Group Replication 을 설정할 때 지정된 별도의 포트를 통해서 통신을 수행하게 되며, 트랜잭션이 그룹내 멤버들에게 동일한 순서로 전달될 수 있도록 하는 기능을 수행하게 됩니다. 또한 복제 구성 환경(토폴로지)의 변경과 멤버의 예기치 않은 장애를 감지하게 됩니다.
트랜잭션 적용을 위한 합의 부분도 처리를 담당하고 있으며, 그룹 복제 구성에서 멤버 간의 합의 처리를 위해서 Paxos 알고리즘을 통해서 구현 및 처리하고 있습니다.
컨센서스(Consensus) - 합의에서 주로 사용되는 것은 Paxos 와 Raft 알고리즘이 있습니다.
Paxos 는 분산 시스템에서 데이터 변경이 여러 곳에서 발생하는 환경에서 주로 사용 사용되고, Raft 는 데이터 변경이 한 곳 또는 특정 멤버 등에서 이루지는 형태 또는 구성에서 사용됩니다.
참고로 MongoDB 에서는 Raft 알고리즘을 사용하고 있습니다.

InnoDB Cluster 에 대한 포스팅 글은 연재 형식으로 작성되었으며, 아래 다음 포스팅에서 이어집니다.

Reference
Reference URL
• mysql.com//innodb-cluster-introduction
• mysql.com/mysql-innodb-cluster
• mysql.com/group-replication-background
• mysql.com/group-replication-plugin-architecture
• mysql.com/news-5-7-17
• mysql.com/mysql-group-replication-hello-world
연관된 다른 글





Principal DBA(MySQL, AWS Aurora, Oracle)
핀테크 서비스인 핀다에서 데이터베이스를 운영하고 있어요(at finda.co.kr)
Previous - 당근마켓, 위메프, Oracle Korea ACS / Fedora Kor UserGroup 운영중
Database 외에도 NoSQL , Linux , Python, Cloud, Http/PHP CGI 등에도 관심이 있습니다
purityboy83@gmail.com / admin@hoing.io


그룹 복제 사용 안할거면 커뮤니티 버젼으로 구성해도 되나요?
안녕하세요
커뮤니티 버전을 사용할지 상용버전을 사용할지는 기술지원 여부의 차이입니다
감사합니다