









Last Updated on 10월 23, 2021 by Jade(정현호)
Oracle(오라클) 11gR2 New Feature 인 RAC ONE NODE 기술문서입니다.
RAC ONE NODE 는 Active-Standby 형태의 HA 기능을 제공 합니다.
Contents
What is RAC ONE NODE
RAC ONE NODE 는 Oracle 11gR2 의 New Feature 입니다.
Oracle RAC One Node는 클러스터 노드 중 하나에서 작동되는 단일 인스턴스의 Oracle RAC 입니다.
오버헤드를 최소화하면서도 다수의 데이터베이스를 단일 클러스터에 통합할 수 있기 때문에 Failover, 롤링 방식의 온라인 패치 적용을 비롯해 Oracle Clusterware를 위한 롤링 방식의 업그레이드를 통해 뛰어난 HA 이점을 제공하게 됩니다.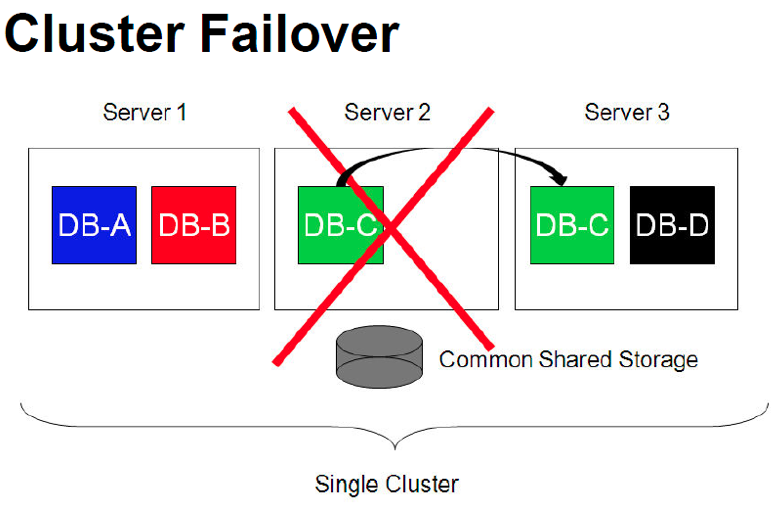
RAC ONE NODE 를 가장 쉽게 위해 할수 있는 것이 위의 이미지 입니다.
가장 큰 기능인 failover 에 대한 그림이며, 물리적인 서버에 1개이상의 인스턴스는 구동되어있을 것이고 해당 머신이나 인스턴스에 장애가 발생시 클러스터 그룹내 다른 서버로 Failover 가 되는 것입니다.
OS Vender Cluster 나 3rd Party Cluster 를 이용한 HA 방식과 유사 하며 다른 클러스터 솔루션을 이용한 HA기능을 Oracle Grid infrastructure(이하 grid) 가 제공하게 된다고 이해하면 됩니다.
애플리케이션에서 다운타임을 발생하지 않도록 Oracle RAC One Node인스턴스를 클러스터의 또 다른 노드로 마이그레이션할 수 있도록 Node Relocate(Omotion유틸리티(11.2.0.1에서만)) 기능을 제공 합니다
인스턴스가 마이그레이션되면 노드에 패치를 적용하거나 업그레이드등을 할수 있으며, 유지보수 작업이 완료되면 다시 원래 Node 로 Relocate 가 가능합니다.
RAC가 대중화가 되었지만 HA 방식으로 사용할 만한 요건등이 발생 되어 HA를 사용하는 일은 자주 있는 일입니다.
그렇다면 HA 에서 보통 사용 되는 OS Vender Cluster 나 3rd Party Cluster 와
Oracle Grid 를 이용한 RAC ONE NODE의 차이는 무엇일까요
아래 표에서 확인 가능 합니다.
해당 표에는 기술되어 있지 않지만 High Availability 부분에서 3rd Part Clustering 에서도 인스턴스의 프로세스를 감지하여 인스턴스가 문제시 Failover를 할수 있습니다.
하지만 오라클 프로세스 모니터링 체크가 보통은 단순히 프로세스의 유무를 확인하는 Shell Script 이기 때문에 Oracle Grid 가 직접적으로 인스턴스를 관리하는 것과는 많은 차이를 보이게 됩니다.
위의 표에서 없는 부분중 아래 부분도 추가 해서 보는 것이 맞다 라고 생각하고 있습니다.
Grid를 사용한 HA의 경우 Instance 외 listener 와 같은 부가 적인 리소스들도 관리가 가능하기 때문에 이 부분도 3rd 제품보다 좋다고 할 수 있습니다.
Grid를 바탕으로 한 데이터베이스는 Oracle Restart 의 정책을 기반으로 동작하게 됨으로 instance 가 Crash 되거나 Listener 프로세스 Fault시 단순하게 Failover를 시키는 Vender Cluster와 달리 Grid가 instance 및 Listener를 재구동하게 됩니다.
이러한 면을 봤을 때 Vendor Cluster보다 oracle database 를 HA 환경에 사용함에 있어서 Grid가 더 탁월 하다고 할 수 있습니다.
RAC ONE NODE의 가장 큰 제약 사항이라면 Enterprise Option 이라는 것입니다.
라이선스 상 EE Option 으로 분류 되어 있습니다
RAC: Frequently Asked Questions [ID 220970.1] 에서 확인 하면
Can I use Oracle RAC One Node for Standard Edition Oracle RAC?
No, Oracle RAC One Node is only part of Oracle Database 11g Release 2 Enterprise Edition. It is not licensed or supported for use with any other editions.
라고 나와있습니다
http://www.oracle.com/us/corporate/pricing/price-lists/index.html
www.oracle.com/us/corporate/price-list.pdf
를 참조하면
Processor License 기준으로 아래와 같이 RAC에 비해 반 이상 저렴 합니다.
RAC => 23000$
RAC ONE => 10000$
또한 RAC ONE NODE는 특이한 라이선스 정책이 존재 합니다.
RAC: Frequently Asked Questions [ID 220970.1] 의 내용 중 아래 와 같은 내용이 존재 합니다.
Oracle RAC One Node licensing also includes the 10-day rule, allowing a database to relocate to another node for up to 10 days per year, without incurring additional licensing fees. This is most often used in the case of failover, or for planned maintenance and upgrading. Only one node in the cluster can be used for the 10-day rule
년간 10일 Rule 이라는 것이 존재 하는데, Omotion 이나 failover, 계획된 MA에 의한 인스턴스를 다른 노드로 옴 기는 것에 대해서 1년중 10일 동안은 무료 라는 부분 입니다.
위의 FAQ에서 나온 10일 동안 무료 라는 부분으로 유추 하기론 Standby Node에 대한 부분은 10일간 Free 이고 그 이상 사용시 부가 된다 라고 생각 할 수 있습니다.
테스트 환경
Test Date : 2011/09/18 ~ 24
CPU : vCPU=4
Memory : 3000M
OS : Solaris 10 (X86-64)
Hostname : jupiter1 , jupiter2
GLOBAL DATABASE NAME : JUPITER
ORACLE_SID : JUPITER_1 , JUPITER_2
SERVICE_NAME : JUPITER.RON.COM
Oracle Version : 11.2.0.2
구성 시 RAC ONE NODE를 사용하려는 모든 Node에 Grid가 설치 되어 있어야 합니다.
그렇기 때문에 RAC와 동일하게 Shared Storage(Disk), SCAN IP,VIP 와 Interconnect IP 등이 준비 되어있어야 합니다.
본 문서는 2 Node 환경에서 Grid가 설치 완료된 환경에서의 Oracle Database S/W 설치시작 부분 부터 기술되어있으며, Storage Type은 ASM 을 사용 합니다.
설치 와 관리에 사용하는 명령어 등이 11.2.01 과 11.2.0.2 는 차이가 있으며 11.2.0.2 기준으로 문서는 작성 되어있으며, 차이가 나는 부분은 별도로 기술되어 있습니다
Oracle Database S/W 및 DBCA
* 스크린샷은 중요한 부분만 첨부 및 설명되어 있습니다
* 그외 진행은 Single/RAC 와 동일 합니다
Database Software 설치
11.2.0.1 의 S/W설치 화면 - 11.2.0.1 버전에서는 RAC를 선택 하고 진행합니다
[참고] 포스팅은 2 Node 환경에서 Grid 구성이 모두 완료된 상태에서 Database S/W 설치 부분 부터 내용이 시작 합니다.
11.2.0.2 에서는 S/W설치 단계에서 RAC ONE NODE 선택 메뉴가 있습니다.
이외에는 다른 부분은 기존의 설치 메뉴는 동일 합니다.
DBCA - DB 생성
11.2.0.1 에서는 아래와 같이 하나의 Node만 선택하고 진행합니다.
11.2.0.2 에서는 DBCA 메뉴에서 ONE NODE 항목이 추가 되었습니다.
아래와 같이 Global Database Name , SID, Service Name 을 입력 합니다.
Service Name 은 RAC의 Service Name과 유사함으로써 SID와 동일 할 수 없습니다.
데이터베이스는 사용할(Active) Node와 예비 Node 를 2개를 선택합니다.
만약 3개 Node 에서 2개만 RAC ONE NODE에 사용하려면 2개를 선택하면 됩니다.
DBCA를 실행 한 Local Node는 반드시 활성화(선택됨) 되어 있으며 그 외 RAC ONE NODE 에 사용할 나머지 노드를 선택 하면 됩니다.
DBCA 진행 중 SCAN IP가 없다면 SCAN LISTENER가 존재 하지 않는 다는 경고가 발생 됩니다
DNS없이 /etc/hosts에 등록된 1개의 SCAN IP도 사용 가능하며 Single Client Access Name(SCAN) 을 사용해도 기능상 괜찮을것 같습니다.
RAC 와 유사 하게 UNDOTBS 는 2개가 default 입니다.
REDO 또한 4개의 Group 에 2개의 Thread 가 기본으로 설정되어 있습니다.
Thread 1 : 2개 , Thred 2: 2개
여기 까지 진행되면 DB 생성이 완료 된 상태가 되게 됩니다.
DB 생성 이후 상태 확인
# 현재 database 상태 조회
oracle$ srvctl status database -d JUPITER
Instance JUPITER_1 is running on node jupiter1
Online relocation: INACTIVE
JUPITER1_1 의 Instance 가 jupiter1 노드에서 구동 중이며,Relocation 상태는 INACTIVE 라는 걸 확인 할 수 있습니다.
# 설정 및 정책 확인
oracle$ srvctl config database -d JUPITER
-> database 의 config 현재 설정 및 정책 등을 살펴 볼 수 있습니다.
Database unique name: JUPITER
Database name: JUPITER
Oracle home: /oracle/product/112/db
Oracle user: oracle
Spfile: +DATA/JUPITER/spfileJUPITER.ora
Domain:
Start options: open
Stop options: immediate
Database role: PRIMARY
Management policy: AUTOMATIC
Server pools: JUPITER
Database instances:
Disk Groups: DATA
Mount point paths:
Services: JUPITER.RON.COM
Type: RACOneNode
Online relocation timeout: 30
Instance name prefix: JUPITER
Candidate servers: jupiter1,jupiter2
Database is administrator managed
Candidate Servers 나 Servcies 명 Type 등의 정보 등을 확인 하면 되며, online relocation timeout : 30 의 경우 relocation 의 임계치 이며, 단위 는 분으로 써 최대 30분안으로 relocate 하겠다 라는 의미 입니다.
oracle$ srvctl config service -d JUPITER
config service 로 현재 JUPITER.RON.COM 이라는 서비스명 과 해당 설정 내역을 확인 가능 하며 Failover Type, method 등 relocate 시 정책이 설정 되어 있습니다.
Service name: JUPITER.RON.COM
Service is enabled
Server pool: JUPITER
Cardinality: 1
Disconnect: false
Service role: PRIMARY
Management policy: AUTOMATIC
DTP transaction: false
AQ HA notifications: false
Failover type: NONE
Failover method: NONE
TAF failover retries: 0
TAF failover delay: 0
Connection Load Balancing Goal: LONG
Runtime Load Balancing Goal: NONE
TAF policy specification: BASIC
Edition:
Preferred instances: JUPITER_1
Available instances:
11.2.0.1 에서 존재 하였던 명령어는 아래와 같습니다.
raconestatus
raconeinit
raconefix
Omotion
11.2.0.2 에서는 srvctl 로 모두 통합 되었으며, 위의 명령어는 존재 하지 않습니다.
RAC ONE NODE SID
RAC ONE NODE 에서의 SID 는 RAC와 조금은 다릅니다
설치 시 Global Database Name 을 JUPITER 로 지정하였고 RAC라면 노드별로 JUPITER1,JUPITER2….n 의 방식으로 SID 가 생성/설정 됩니다.
하지만 RAC ONE NODE는 JUPITER_1 , JUPITER_2 와 같이 _(언더바) 가 포함 되어 RAC와는 다르게 표기 됩니다
Omotion 이나 srvctl 을 통해 Relocate 하여 다른 노드로 이동 시키면 해당 SID는변경 됩니다
예를 들어 1번 노드에서 2번노드로 Relocate 시키게 되면 JUPITER_2 로 2번 노드에서 구동되게 됩니다.
하지만 1번 노드에서는 항상 JUPITER_1 SID 로 , 2번노드에서는 JUPITER_2 로 구동 되는 것은 아닙니다.
이 부분은 뒤에서 TAF 및 Relocate 설명 후 다시 설명하도록 하겠습니다
Instance Relocate
11.2.0.1 까지 Omotion 이라는 커맨드로 Instance Migrate 하였습니다
Omotion 이란 커맨드의 의미를 먼저 설명하면
Oracle 에서는 RAC ONE NODE를 가상화 와 비슷 하다 라고 표현하면서,Oracle VM 에서 Certified 솔루션이라는 소개도 하였습니다.
VMware의 Vmotion 와 Citrix 의 XEN Motion 유사한 기능 이며, 해당기능은 설치된 물리적 서버에서 작동중인 Virtual Machine 을 다른 ESX(물리서버) 서버로 shutdown 하지 않고 Live 상태로 이동시키는 기능을 의미 합니다.
Omotion 이라는 커맨드도 위와 유사한 의미을 지니고 있다
하지만 가상화의motion 기능 보다는 부드럽지는 못한 것은 사실이며, RAC 에서도 select 를 제외 하고 DML은 트랜젝션이 롤백 된다는 사실은 알고 있을 계실것 입니다
그럼 RAC ONE NODE는 어디 부분 까지 가능 한지는 뒤에 있는 TEST 를 통해 확인 해보도록 하겠다.
[참고] Instance 의 Migrate 시 더 이상 Omotion 명령어를 사용 하지 않는다
11.2.0.1 에서만 사용 가능하며, 11.2.0.2 에서는 srvctl를 사용 하게 됩니다.
[명령어]
srvctl relocate database -d 데이터베이스명 -n 옴기려는 노드명 -w 1 -v
-w 옵션을 기술 하지 않는다면 online relocation timeout : 30 이 적용 됩니다.
단위 는 분 이며 이 시간은 세션을 종료 하고 , 인스턴스를 migrate , 트랜잭션을 OPEN 하는 시간을 의미 합니다.
시간 안에 트랜젝션이 종료 되지 않는다면, shutdown abort 과 같은 일환으로 트랜젝션은 취소 가 되며, 세션은 사라지게 됩니다.
이런 시간에 대한 제한에 대해서 default 30분이 아닌 다른 시간으로 제한을 두고자 할 때 -w 옵션을 사용하게 됩니다.
보통의 경우 테스트 문서나 외국 문서들의 대부분이 -w 1 을 주며 시간의 범위는 1~720 분 까지 입니다.
-v 옵션은 진행 중인 자세한 내역을 표시 하는 것이다.
실제로 아래와 같은 명령어로 relocate 하게 됩니다.
oracle$ srvctl relocate database -d JUPITER -n jupiter2 -w 1 -v
Configuration updated to two instances
Instance JUPITER_2 started
Services relocated
Waiting for 1 minutes for instance JUPITER_1 to stop.....
Instance JUPITER_1 stopped
Configuration updated to one instance
위의 진행 상황을 보게 되면
JUPITER_2 가 먼저 기동이 된 후 1분안에 JUPITER_1 (1번 NODE에서 구동 중인 Instance)의 종료를 기다리고 있습니다. 종료 된 후 Reconfiguration 이 됩니다.
dbca 진행 시 위에서 RAC와 같은 Thread 개념이 존재하며, undotbs 가 노드별로 존재 하는 이유 입니다.
짧지만 Relocate 되는 순간, Candidate Node 에서 Instance를 구동하게 됩니다.
Datafile Umount => 신규 NODE에서 MOUNT => Instance Startup 의 방식으로 Instance 가 완전히 종료 되는 OS Vendor Cluster 혹은 3rd Party Cluster 와는 다르게 동작 하게 됩니다.
그렇기 때문에 짧지만 2개의 Instance가 구동이 되기 때문에 노드 별로 Thead가 존재 하며, redo, undotbs 를 다르게 사용 하는 것 입니다.
진행 중 다른 세션(창) 에서 srvctl status database -d JUPITER 로 확인 해보면 아래와 같이 진행 내역을 확인 할 수 있습니다.
Instance JUPITER_1 is running on node jupiter1
Online relocation: INACTIVE
=> 아직 까지는 INACTIVE 상태 입니다.
Instance JUPITER_1 is running on node jupiter1
Online relocation: ACTIVE
Source instance: JUPITER_1 on jupiter1
=> Active 상태로 변경 되었으며, Source Instance에 대한 정보가 표시 됩니다.
Instance JUPITER_1 is running on node jupiter1
Instance JUPITER_2 is running on node jupiter2
Online relocation: ACTIVE
Source instance: JUPITER_1 on jupiter1
Destination instance: JUPITER_2 on jupiter2
=> 각 Node 별로 Instance가 개별 적으로 구동 되었다고 알 수 있으며, Source Instance 와 Destination Instance 가 어느 NODE에서 구동 되는지가 표기됩니다.
Instance JUPITER_2 is running on node jupiter2
Online relocation: ACTIVE
Source instance: JUPITER_1 on jupiter1
Destination instance: JUPITER_2 on jupiter2
=> JUPITER_1 인스턴스(1번NODE) 의 대한 정보가 사라지게 됩니다
현재 상태가 JUPITER_1 이 shutdown 이 완료 된 시점입니다.
Instance JUPITER_2 is running on node jupiter2
Online relocation: INACTIVE
마지막 으로 Online relocation 이 INACTIVE 되면서 2번노드에서 JUPITER_2 인스턴스가 정상 구동 됨을 알 수 있습니다.
위와 같은 프로세스로 relocate 는 진행 되며 그래서 각 노드별로 _n 의 SID가 존재 하는 것 입니다.
다시 1번 노드로 migrate 하려면 아래와 같으며 일단 다시 relocate를 한다
oracle$ srvctl relocate database -d JUPITER -n jupiter1 -w 1 -v
Change Setting
위에서 조회해 봤듯이 현재는 정상적인 relocate 에도 TAF,CTF등은 적용 되지 않습니다.
그래서 default 정책에서 수정해야 합니다
srvctl modify service -d 를 이용하여 각종 속성을 변경 할 수 있습니다.
사용 가능한 속성은 아래와 같습니다.
-P {BASIC|PRECONNECT|NONE} : TAF Failover 정책
-> BASIC : On-demand 방식으로 Failover가 필요할 때 살아 있는 인스턴스 쪽으로 Oracle Server Process를 기동합니다.
-> PRECONNECT : Failover가 이루어질 인스턴스에 미리 Oracle Server Process를 기동시켜 Failover가 발생하는 오버헤드를 미리 줄여 놓는 방식, Failover 속도는 향상되지만 자원의 낭비는 초래 할 수 있습니다.
<RAC ONE NODE에서는 사용불가 옵션>
-j {SHORT | LONG} : Connection Load Balancing Goal
-B {NONE | SERVICE_TIME | THROUGHPUT} : Runtime Load Balancing Goal
-m {NONE | BASIC} : Failover method
-e {NONE | SESSION | SELECT} : Failover type
-> NONE : TAF 기능 사용 하지 않습니다.
-> SESSION : select 하다가 접속되어져 있는 노드가 다운이 되면 살아있는 노드로 재 접속은 되지만 fetch가 진행 중이었다면 fetch는 도중에 실패하게 됩니다.
-> SELECT : session과 같고 fetch도 이어서 진행할 수 있습니다. 즉 대량의 레코드를 한번 에select 하는 app에 효율적입니다.
-w failover_delay : Failover 시도에 지연 임계치
-z failover_retries : Failover 시도 횟수
위 의 속성 중 NONE 으로 설정 된 TAF Failover Policy, Failover type , Failover method 를 변경 할 것입니다.
TAF Failover Policy 는 PRECONNECT
Failover type 은 SELECT
Failover Method 는 Basic 으로 변경을 진행 합니다.
oracle$ srvctl modify service -d JUPITER -s JUPITER.RON.COM \
-P PRECONNECT \
-e SELECT -m BASIC
Service name: JUPITER.RON.COM
Service is enabled
Server pool: JUPITER
Cardinality: 1
Disconnect: false
Service role: PRIMARY
Management policy: AUTOMATIC
DTP transaction: false
AQ HA notifications: false
Failover type: SELECT
Failover method: BASIC
TAF failover retries: 0
TAF failover delay: 0
Connection Load Balancing Goal: LONG
Runtime Load Balancing Goal: NONE
TAF policy specification: BASIC
Edition:
Preferred instances: JUPITER_1
Available instances:
TAF TEST
참고로 TAF는 OCI 방식에서만 가능하며, JDBC THIN 드라이버의 경우 CTF 와 10g JDBC부터 나온 Fast Connection Failover(FCF) 만 사용 가능 합니다.
tnsnames.ora 의 구성은 아래와 같이 2가지 방식으로 가능하다.
1) 이전과 동일하게 2개의 VIP 와 FAILOVER=ON 을 기술해서 사용 하는 방법
JUPITER_VIP=
(DESCRIPTION =
(ADDRESS_LIST=
(LOAD_BALANCE=ON)
(FAILOVER=ON)
(ADDRESS = (PROTOCOL = TCP)(HOST = 10.10.1.169)(PORT = 1521))
(ADDRESS = (PROTOCOL = TCP)(HOST = 10.10.1.168)(PORT = 1521)))
(CONNECT_DATA =
(SERVICE_NAME = JUPITER)
(FAILOVER_MODE=(TYPE=SELECT)(METHOD=BASIC))
)
)
2) 아래와 같이 SCAN IP 를 이용 하는 방법
JUPITER_SRV =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = jupiter_scan)(PORT = 1521)
(CONNECT_DATA = (SERVER = DEDICATED)
(SERVICE_NAME = JUPITER.RON.COM)
)
)
SCAN IP를 이용할 경우 SERVICE_NAME 에는 DBCA로 생성시 지정한 SERVICE_NAME 으로 해야 합니다.
테스트에 사용 할 쿼리는 아래와 같습니다.
Filename : ron.sql
col sid format 99999
col serial# format 99999999
col failover_type format a13
col failover_method format a15
col failed_over format a11
select sid, serial#, failover_type, failover_method, failed_over
from v$session where username ='SYSTEM';
select instance_name from v$instance;
select count(*) from
( select * from dba_source union
select * from dba_source union
select * from dba_source union
select * from dba_source union
select * from dba_source union
select * from dba_source union
select * from dba_source union
select * from dba_source union
select * from dba_source union
select * from dba_source union
select * from dba_source union
select * from dba_source union
select * from dba_source union
select * from dba_source union
select * from dba_source union
select * from dba_source union
select * from dba_source union
select * from dba_source union
select * from dba_source
);
col sid format 99999
col serial# format 99999999
col failover_type format a13
col failover_method format a15
col failed_over format a11
select sid, serial#, failover_type, failover_method, failed_over
from v$session where username ='SYSTEM';
select instance_name from v$instance;
select count(*) from
(select * from dba_source union
select * from dba_source union
select * from dba_source union
select * from dba_source union
select * from dba_source union
select * from dba_source union
select * from dba_source union
select * from dba_source union
select * from dba_source union
select * from dba_source union
select * from dba_source union
select * from dba_source union
select * from dba_source union
select * from dba_source union
select * from dba_source union
select * from dba_source union
select * from dba_source union
select * from dba_source union
select * from dba_source
);
Test 1: Active Session
Test 는 쿼리 수행 중 relocate 가 발생 되었을 때 세션 및 Select 작업에 대한 TAF가 가능한지를 확인 합니다.
다른 oracle client 가 설치된 host에서 아래 커맨드로 ron.sql 을 실행한다.
oracle$ sqlplus system/oracle@JUPITER_VIP<ron.sql
위의 쿼리 실행 중 relocate 를 실시 수행 합니다. 결과는 아래와 같습니다.
oracle$ sqlplus system/oracle@JUPITER_VIP<ron.sql
SQL*Plus: Release 11.1.0.7.0 - Production on Tue Sep 20 03:11:44 2011
Copyright (c) 1982, 2008, Oracle. All rights reserved.
Connected to:
Oracle Database 11g Release 11.2.0.2.0 - 64bit Production
With the Real Application Clusters and Automatic Storage Management options
SID SERIAL# FAILOVER_TYPE FAILOVER_METHOD FAILED_OVER
------------------------------------------------------------------------
766 55 SELECT BASIC NO
=>> SID 는 766 이며 현재 Failover 가 된 상태는 아닙니다.
INSTANCE_NAME
----------------
JUPITER_1
=>> Instance 이름은 JUPITER_1 입니다.
COUNT(*)
--------------
158519
==>> 여러 개의 union 으로 된 쿼리가 수행이 되어 count 가 return 되었다.
SID SERIAL# FAILOVER_TYPE FAILOVER_METHOD FAILED_OVER
-------------------------------------------------------------------------
2278 23 SELECT BASIC YES
==>> 위와 동일 하게 SID등을 조회 한다. SID 및 SERIAL# 값이 변경 되었다.
FAILED_OVER 가 YES 로 되어있는 것으로 정상적으로 Failover 가 됨을 확인 가능하다
INSTANCE_NAME
------------------------
JUPITER_2
==>> 인스턴스명도 JUPITER_2 로 변경 되었다.
COUNT(*)
-------------
158519
인스턴스2 에서 조회 한(쿼리가 수행된) count 값도 return 받았다.
srvctl status database -d JUPITER 로 조회 하면
Instance JUPITER_2 is running on node jupiter2
Online relocation: INACTIVE
=> 2번 노드에서 JUPITER_2 인스턴스가 구동중임을 확인 할 수 있다.
Test2 : Idle Session
SQL> select sid, serial#, failover_type, failover_method, failed_over from v$session where username ='SYSTEM';
SID SERIAL# FAILOVER_TYPE FAILOVER_M FAI
------------------------------------------------------------------------
11 81 SELECT BASIC NO
==>> 현재는 1번노드의 인스턴스에서 Idle session 상태 입니다.
SQL> select instance_name from v$instance;
INSTANCE_NAME
-------------------------
JUPITER_1
==>> SID는 JUPITER_1 입니다.
srvctl 로 relocate 를 실시 후 다시 확인 해보면
SQL> select sid, serial#, failover_type, failover_method, failed_over
from v$session where username ='SYSTEM';
SID SERIAL# FAILOVER_TYPE FAILOVER_M FAI
------------------------------------------------------------------
1527 5 SELECT BASIC YES
SQL> select instance_name from v$instance;
INSTANCE_NAME
-----------------------
JUPITER_2
==>> Active Session 일 때 테스트한 결과와 동일하게 Session 에 대한 Fail-over가 정상적으로 동작 하였습니다
Failover Test
이제 Failover Test 를 진행해보도록 하겠습니다.
Test1 : pmon process kill
다시 노드를 1번으로 relocate 후 위와 동일하게 쿼리를 수행 중 pmon 프로세스를 kill 로 종료를 하겠습니다.
crs_stat -p ora.jupiter.db 로 조회 하면 아래와 같아 CHECK_INTERVAL은 default value 가 1초 입니다.
NAME=ora.jupiter.db
TYPE=ora.database.type
ACTION_SCRIPT=
ACTIVE_PLACEMENT=1
AUTO_START=restore
CHECK_INTERVAL=1
DESCRIPTION=Oracle Database resource
FAILOVER_DELAY=0
< ... 중략 ...>
PLACEMENT=restricted
RESTART_ATTEMPTS=2
SCRIPT_TIMEOUT=60
START_TIMEOUT=600
STOP_TIMEOUT=600
UPTIME_THRESHOLD=1h
PMON 을 kill 로 종료 시키게 되면 JUPITER_1 의 Alert 에 아래와 같은 메시지와 함께 바로 인스턴스가 재 구동 됩니다.
Tue Sep 20 03:37:05 2011
Shutting down instance (abort)
License high water mark = 5
USER (ospid: 20092): terminating the instance
Instance terminated by USER, pid = 20092
Tue Sep 20 03:37:07 2011
Instance shutdown complete
Tue Sep 20 03:38:35 2011
Starting ORACLE instance (normal)
도입부에 설명한 내용과 같이 Grid 를 기반으로 하여 Oracle Restart 정책이 반영 되어있기 때문에 process의 비정상 종료시 먼저는 다른 노드로 Take-Over하지 않고 현재 노드에서 1초 내외로 인스턴스 구동을 하게 됩니다
이 부분 또한 프로세스 기반으로 모니터링 하여 Take Over하거나 인스턴스를 구동하는 Vendor Cluster 보다 빠르게 동작하게 됩니다.
Test2 : shutdown abort
Active session 혹은 Idle session 모두 shutdown 에 대한 부분은 fail-over 되지 않습니다.
abort 또한 shutdown 옵션 중 하나이기 때문에 instance를 재기동 한다던가 다른 Node에서 재시작 하는 등의 Action은 존재 하지 않습니다.
relocate 시 세션이 유지 되는 것은 위에서도 설명 되었던 것처럼 짧은 시간 다른 Candidate node 에서 Instance가 구동되어 해당 서버프로세스 등의 정보를 받아 오기 때문에 가능 한 부분 임으로 shutdown abort 과 같이 다른 유휴 노드에서 인스턴스 구동에 걸리는 시간보다 빠르게 종료 되는 상황이라면 Active session/ idle session 모두 Failover는 불가능 합니다.
Test 3: OS reboot
OS reboot 의 경우 OS의 Crash와 유사한 경우로써 session 이나 쿼리에 대한 Failover는 불가능 합니다.
하지만 시스템 사향에 따라 다르지만 20초~수분 사이에 Grid 에 의해서 Candidate Node 에서 구동 됨을 확인 할 수 있습니다.
reboot 명령을 내렸을 당시 마지막으로 Alert.log 에 기록된 내용은 아래와 같습니다.
Wed Sep 21 14:41:05 2011
NOTE: ASMB terminating
Errors in file /oracle/sbase/diag/rdbms/jupiter/JUPITER_1
/trace/JUPITER_1_asmb_21142.trc:
ORA-15064: communication failure with ASM instance
ORA-03113: end-of-file on communication channel
시간상 14시 41분 5초 에 마지막으로 로그가 기록 되었고 다른 노드의 Alert.log 에서는 아래와 같이 14시 41분 46초에 2번재 노드에서 instance 가 기동 됨을 알 수 있습니다.
Wed Sep 21 14:41:46 2011
Starting ORACLE instance (normal)
LICENSE_MAX_SESSION = 0
LICENSE_SESSIONS_WARNING = 0
이 부분의 경우에도 시스템 사양에 따라 달라지는 부분이며, Vendor Cluster 와 복구에 대한 시간은 얼추 비슷할 수 있습니다.
조금 이라도 빠르다라고 하면 RAC ONE NODE에 해당 하는 모든 노드에서 ASM 스토리지나 ,Cluster file system 스토리지 영역이 Active 하게 mount 되어 있기 때문에 스토리지 절재 후 다시 Candidate Node 에서 mount 하는 Storage Failover 에 대한 시간은 절약 할 수는 있습니다
Dynamic SID
위에서 1번 노드에서는 JUPITER_1 , 2번노드에서는 JUPITER_2 로 나타남을 확인 할 수 있었습니다. 하지만 이것이 항상 동일 하진 않다 라고 말하였습니다.
1번 노드에서 JUPITER_1 의 SID 로 기동 되어 있는 상태에서 OS의 장애(reboot) 가 발생 되면 SID 에 대한 부분이 조금 달라 지게 됩니다. 아래와 같이 1번 노드에서 JUPITER_1 SID 로 기동 중 입니다.
os 에서 reboot 명령으로 crash 형태를 재현 합니다.
2번 서버에서 instance가 기동 된 후 확인 해보면 아래와 같은 SID 로 기동 됩니다.
[root@jupiter2:/root]$ hostname
jupiter2
[root@jupiter2:/root]$ ps -ef | grep ora_ | grep -v grep
oracle 28283 1 0 10:05:47 ? 0:00 ora_lms0_JUPITER_1
oracle 28363 1 0 10:05:51 ? 0:00 ora_o000_JUPITER_1
2번 노드에서 JUPITER_2 가 아닌 JUPITER_1 로 기동 됨을 확인 할 수 있습니다.
위와 같이 Crash 나 reboot 상황에서 srvctl relocate 로 migrate 시 아래와 같이 1번 노드에서 JUPITER_2 로 구동 됨을 확인 할 수 있습니다.
[root@jupiter1:/root]$ hostname
jupiter1
[root@jupiter1:/root]$ ps -ef | grep ora_pmon | grep -v grep
oracle 1960 1 0 10:21:38 ? 0:00 ora_pmon_JUPITER_2
장애에 의해서 Candidate 노드로 구동 될 때에는 이전 Node 에서 사용중인 SID 를 그대로 사용하며, 정상적인 srvctl relocate 명령을 이용하여 migrate를 하게 되면 SID는 순차적으로 변경이 됩니다.
위와 같이 1번 노드에서 JUPITER_2 를 2번 노드에서는 JUPITER_1 라는 SID 에서 노드별로 SID 를 맞추려면 Crash(reboot) 이 되거나, srvctl stop database 로 정상 종료 후 start 하게 되면 해당 노드에 맞는 SID로 기동되게 됩니다.
Converting Database : RAC One Node to RAC
srvctl convert 커맨드를 이용하여 기존의 RAC ONE NODE를 Online 상태에서 RAC 로 Convert 하는 기능도 제공 되며 반대로 RAC => RAC ONE NODE 로도 가능합니다.
현재 인스턴스는 JUPITER_1 1개만 존재 하는 상태 이며, node 1에 구동 중 입니다. 먼저 사용중인 JUPITER.RON.COM 서비스를 삭제를 해야 합니다.
JUPITER.RON.COM 은 ora.JUPITER 라는 기본 Server pool 에 종속 되어 있습니다.
ora.JUPITER 라는 Server pool 은 RAC 변환 후에도 사용 하기 때문에 -f 옵션을 사용 하여 JUPITER.RON.COM 서비스를 삭제 해야 합니다.
oracle$ srvctl remove service -d JUPITER -s JUPITER.RON.COM -f
srvctl convert 를 이용하여 기존 RAC ONE NODE를 RAC 로 변환합니다
oracle$ srvctl convert database -d JUPITER -c RAC
srvctl config 로 조회 해보면 아래와 같이 RAC로 변경 된 것을 확인 할 수 있습니다.
oracle$ srvctl config database -d JUPITER
Database unique name: JUPITER
Database name: JUPITER
Oracle home: /oracle/product/112/db
Oracle user: oracle
Spfile: +DATA/JUPITER/spfileJUPITER.ora
Domain:
Start options: open
Stop options: immediate
Database role: PRIMARY
Management policy: AUTOMATIC
Server pools: JUPITER
Database instances: JUPITER_1
Disk Groups: DATA
Mount point paths:
Services:
Type: RAC
Database is administrator managed
이제 2번째 노드를 추가 하여 Active-Active 상태로 변경 합니다.
현재RAC 이지만 인스턴스는 1개 인 상태 입니다.
아래와 같이 srvctl add instance 를 이용 합니다.
$ srvctl add instance -d JUPITER -i JUPITER_2 -n jupiter2
추가 후 srvctl config database 로 조회 하면 아래와 같이 Instance 가 추가 된 것을 확인 할 수 있다.
oracle$ srvctl config database -d JUPITER
Database unique name: JUPITER
Database name: JUPITER
Oracle home: /oracle/product/112/db
Oracle user: oracle
Spfile: +DATA/JUPITER/spfileJUPITER.ora
Domain:
Start options: open
Stop options: immediate
Database role: PRIMARY
Management policy: AUTOMATIC
Server pools: JUPITER
Database instances: JUPITER_1,JUPITER_2
Disk Groups: DATA
Mount point paths:
Services:
Type: RAC
Database is administrator managed
ONE NODE RAC 에서 RAC 로 변경 시 Online 으로 모든 작업이 진행 됩니다. 그러므로 _n 형식의 SID는 변경 되지 않습니다.
JUPITER_2 인스턴스를 구동시킵니다.
oracle$ srvctl start instance -d JUPITER -n jupiter2
jupiter2(node2) 에서 pmon 이 구동이 되는 것이 확인 가능하며
oracle$ hostname
jupiter2
oracle$ ps -ef | grep ora_pmon | grep -v grep
oracle 8915 1 0 03:59:37 ? 0:00 ora_pmon_JUPITER_2
crsctl stat res -t 로 확인 해보면 2개의 instance 가 OPEN 상태 임을 확인 가능하다
[root@jupiter2:/root]$ crsctl stat res -t
ora.jupiter.db
1 ONLINE ONLINE jupiter1 Open
2 ONLINE ONLINE jupiter2 Open
srvctl status database 로 조회 하면 이전 과 다르게 Online relocation: INACTIVE 라는 문구는 존재 하지 않습니다.
[oracle@jupiter1:/oracle]$ srvctl status database -d JUPITER
Instance JUPITER_1 is running on node jupiter1
Instance JUPITER_2 is running on node jupiter2
Converting Database : RAC to RAC One Node
위에서 변경 한 RAC 를 다시 RAC ONE NODE 로 변경 하겠습니다.
먼저 할 작업은 instance 를 단일 instance 로 변경 하는 것입니다. 3 NODE 라면 2 NODE를 삭제 하고 1개의 NODE를 남겨 놔야 됩니다.
instance 의 구동을 정지 하고 삭제를 진행합니다.
instance 정지
$ srvctl stop instance -d JUPITER -i JUPITER_2
instance 삭제
$ srvctl remove instance -d JUPITER -i JUPITER_2
Remove instance from the database JUPITER? (y/[n]) y
RAC ONE NODE 생성시 dbca 작업 중 service 를 JUPITER.RON.COM 로 등록해서 생성 한 내역이 존재 합니다.
동일하게 RAC ONE NODE를 위한 service 부터 생성 해줘야 한다.
srvctl add service -d JUPITER -s JUPITER.RON.COM -r "JUPITER_1"
=> 서비스 네임 : JUPITER.RON.COm
=> 종속 instance : JUPITER_1
서비스를 추가 하게 되면 자동으로 server pool 이 생성 됩니다.
crsctl status serverpool 로 확인 하면 아래와 같이 새로운 Server pool 이 생성 됩니다.
해당 SERVER(node) 가 등록 되었음을 확인 가능하다.
oracle$ crsctl status serverpool
NAME=Free
ACTIVE_SERVERS=jupiter2
NAME=Generic
ACTIVE_SERVERS=jupiter1
NAME=ora.JUPITER
ACTIVE_SERVERS=jupiter1
NAME=ora.JUPITER_JUPITER.RON.COM
ACTIVE_SERVERS=jupiter1
다시 srvctl convert 를 이용해서 RAC ONE NODE 로 변경 합니다.
-i 옵션은 Instance name prefix 으로 써 JUPITER 로 기술 하면 RAC ONE NODE 로 전환 되면서 SID는 자동으로 _1 , _2 …._n 형 태로 등록 됩니다.
$ srvctl convert database -d JUPITER -c RACONENODE -w 1 -i JUPITER
srvctl config database 로 조회하면 다시 RAC ONE NODE 로 변경 되는 걸 확인 할 수 있습니다.
oracle$ srvctl config database -d JUPITER
Database unique name: JUPITER
Database name: JUPITER
Oracle home: /oracle/product/112/db
Oracle user: oracle
Spfile: +DATA/JUPITER/spfileJUPITER.ora
Domain:
Start options: open
Stop options: immediate
Database role: PRIMARY
Management policy: AUTOMATIC
Server pools: JUPITER
Database instances:
Disk Groups: DATA
Mount point paths:
Services: JUPITER.RON.COM
Type: RACOneNode
Online relocation timeout: 1
Instance name prefix: JUPITER
Candidate servers: jupiter1
Database is administrator managed
다시 srvctl status database 로 조회 하면 Online relocation: INACTIVE 상태를 확인 할 수 있습니다.
oracle$ srvctl status database -d JUPITER
Instance JUPITER_1 is running on node jupiter1
Online relocation: INACTIVE
Conclusion
RAC ONE NODE 는 분명히 Vendor Cluster 와는 조금은 다른 형태의 HA 동작 방식을 제공 하며, Grid 에 의해 Oracle 을 HA 방식으로 이용하려 할 때 좀더 빠르게 Failover 를 지원 하게 됨을 확인 할 수 있었습니다.
relocate 시 RAC와 동일하게 select 작업 까지 TAF가 지원 됨으로 계획된 Server 작업 및 Oracle S/W Patch시 Rolling Patch 시 Online 성이 Vendor Cluster 보다는 좀더 좋다 라고 평가 할 수 있겠습니다.
해당 포스팅 TEST시 실제로는 Enterprise/Standard Edition 둘다 가능함을 확인 하였습니다.
하지만 실제로는 사용은 License 상 Standard Edition 에서는 불가 하기 때문에, 아쉬움이 남는 부분이 있습니다.
[추가] 19.7 버전에서도 SE 에서 사용가능한 HA 기능이 도입 되었습니다.
관련된 다른 글





Principal DBA(MySQL, AWS Aurora, Oracle)
핀테크 서비스인 핀다에서 데이터베이스를 운영하고 있어요(at finda.co.kr)
Previous - 당근마켓, 위메프, Oracle Korea ACS / Fedora Kor UserGroup 운영중
Database 외에도 NoSQL , Linux , Python, Cloud, Http/PHP CGI 등에도 관심이 있습니다
purityboy83@gmail.com / admin@hoing.io


