









Last Updated on 9월 30, 2021 by Jade(정현호)
안녕하세요
11gR2 NF중 하나인 ASM의 IDP에 대한 정리 문서 입니다.
Contents
테스트 서버 정보
|
Items |
Description |
|
|
Test Date |
2011 / 08 / 12 |
|
|
Machine |
DELL R910 |
|
|
CPU |
Intel(R) Xeon(R) CPU X7550 @ 2.00GHzX 8 |
|
|
Main Memory |
32GB |
|
|
O/S version |
OEL 5.4 |
|
|
Host Name |
test |
|
|
ORACLE_SID |
orcl |
|
|
Oracle version |
11.2.0.2 |
|
• Scenario & Environment
1) 11gR2 NF 인 ASM IDP 기능에 대해서 기술된 문서 입니다.
2) Grid와 S/W는 11gR2(11.2.0.2) 버전으로 설치 되어있는 상태에서 진행됩니다.
3) ASM IDP의 사용법과 HOT 영역과 Cold 영역의 속도차이를 확인 합니다.
ASM IDP
Oracle 11gR2 의 NF 중 하나는 IDP 입니다.
ASM IDP(Intelligent Data Placement) 이며 , 우리말로 하면 지능적 데이터 배포의 의미로 보면 맞을 것 같습니다. 이전 버전에서는 ASM은 하나의 ASM 디스크를 단일객체(Disk Group) 으로 처리하여 Stripe 기법을 기반으로 ASM 디스크 상에서 ASM 파일(AU)의 위치를 최적화(균등하게 분할) 하려고 시도하였습니다
그러나 Disk의 Spin(디스크 중심부) 로 부터 떨어져 있는 외곽 Track의 물리적 디스크 영역은 내부 Track 에 비하여 높은 처리량을 보여주었으며, 그래서 ASM IDP 라는 기능으로 여러 DISK 상에서 ASM Stripe 된 파일 뿐만 아니라 일반 ASM 파일들이 아래 그림과 같이 지정된 물리적 디스크 영역(외각 영역 혹은 내부 영역) 에 지정하여 배포되는 것을 확인 할 수 있다.
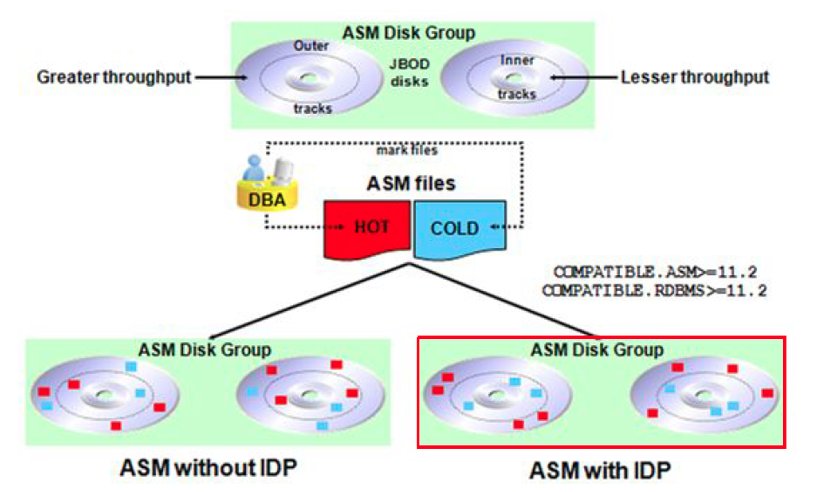
위 그림에서 빨간색 태두리 로 되어있는(ASM with IDP) 를 보게 되면 옆의 ASM witout IDP 와 달리 외곽 영역은 빨간색 블록이, 내부영역에는 파란색 블록이 위치 되어있는 것이 주요한 관점 입니다
11gR2 ASM은 선호영역(HOT 또는 COLD) 을 기반으로 파일에 익스텐트를 할당 합니다.
물리적 디스크의 특성에 대해서 오라클은 알 수 없기 때문에 IDP는 스패닝(spanning) 디스크 아키텍처를 목표로할 뿐, 스토리지 어레이(Storage Array)의 특성은 고려하지 않게 됩니다.
HOT 영역과 COLD 영역의 두 개의 디스크 영역은 새로운 디스크 그룹을 생성하거나 기존 디스크 그룹에 디스크 추가할 때마다 지능적으로 식별되며, 이 설정을 사용하면 자주 사용되는 데이터는 높은 데이폭을 갖는 바깥쪽 트랙에 위치되도록 설정하여, 데이터에 대한 Access/Seek Time 을 감소 시킬 수 있게 됩니다.
[참고] Disk의 영역은 동일한 성능 특성을 갖는 연속된 Track 의 집합이며, 바깥쪽 Track 은 안쪽 Track 보다 많은 Track 을 포함 하게 되며 그렇기 때문에 바깥쪽에 트랙에 존재 하는 Sector 의 개수가 더 많아 지게 됩니다.
테스트
ASM IDP 에 대한 성능 차이 여부 등에 대해서 확인 해보도록 하겠습니다.
Disk 현황
현재 테스트 환경은 11gR2(11.2.0.2) 이며, 11gR2 부터 ASM 을 사용하기 위해서는 Grid Infrastructure 가 반드시 필요 하기 때문에 구성자체는 Oracle Restart 와 동일 합니다.
다음과 같이 제품이 설치 되어 있으며, 11gR2(11.2.0.2) Grid Infrastructure , 11gR2(11.2.02) Oracle Database 현재 system ,sysaux, redo, control file 등 기본 데이터 파일은 SYSTEM_DG 라는 DISK GROUP 존재 합니다.
포스팅에서는 물리 DISK는 아래와 같이 SAS 4개 DISK 를 사용 합니다.
0번(첫 번째) Disk 는 /dev/sda 와 매칭 됩니다
다음의 이미지와 같이 /dev/sdb 는 2번째 디스크 , /dev/sdc 는 3번째 디스크 , /dev/sdd 는 4번째 디스크가 되게 됩니다.
/dev/sdb1 을 이용하여 SYSTEM_DG 라는 DISK GROUP 을 생성하여 orcl 이란 SID 로 인스턴스를 생성 하였으며, 3번째 디스크와 4번째 디스크를 이용하여 TEST 이름으로 DISK GROUP 을 만들어서 테스트를 진행하도록 하겠습니다.
grid 유저로 Grid Infrastructure 가 설치 되어 있다면 grid 유저로 oracle 유저로 모두 설치 되었다면, oracle 유저로 asmca 를 실행 합니다.
Test Disk Group 생성
Create
ASMCA가 실행되었다면 Create 버튼을 클릭 합니다.
Diskgroup 지정
포스팅에서는 TEST 라는 이름으로 Diskgroup 명을 지정하도록 하겠으며, 디스크로는 /dev/raw/raw2 와 raw3 를 사용하도록 하겠으며, Redundancy 는 반드시 Normal 이상으로 설정 해야 합니다. 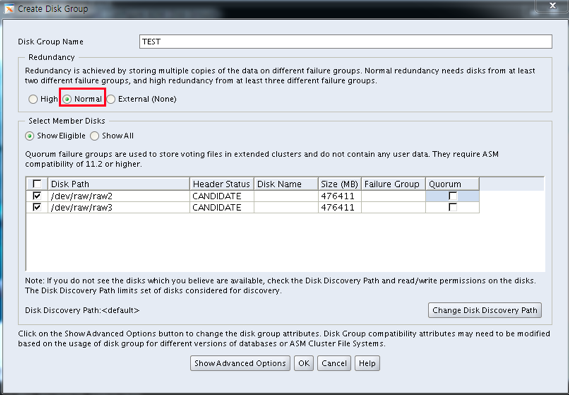
External Redundancy 사용시 아래 에러가 발생 합니다.
ORA-15067: command or option incompatible with diskgroup redundancy
Options
아래 부분에서 Show Advanced Options 를 클릭하면 추가적인 옵션을 설정 할 수 있습니다.
Compatible 파라미터
다음에서 언급할 Compatible.asm , Compatible.rdbms 속성을 해당 메뉴에서 설정 할 수 있으며 생성 후 커맨드를 통해서 속성을 변경 하도록 하겠습니다.
Template 생성 및 Tablespace 생성
속성 확인
IDP 를 사용하려면 DISKGROUP 속성 중에서 COMPATIBLE.ASM 과 COMPATIBLE.RDBMS 의 속성이 반드시 11.2 이상으로 설정이 되어있어야 합니다.
default 값은 아래 쿼리로 조회가 가능합니다.
set lines 300 col name for a20 col ASM_COMPATIBILITY for a20 col DATABASE_COMPATIBILITY for a20 select name, COMPATIBILITY "ASM_COMPATIBILITY",DATABASE_COMPATIBILITY from v$asm_diskgroup;

속성 변경
COMPATIBLE.RDBMS 의 버전이 11.2 이하 이기 때문에 COMPATIBLE 변경이 필요 합니다.
환경 변수 변경 후 asm 인스턴스 로 접속 합니다.
export $ORACLE_SID=+ASM $ sqlplus / as sysasm
아래 커맨드를 통해 TEST Diskgroup 속성을 변경 합니다.
SQL> alter diskgroup TEST set attribute 'compatible.asm'='11.2'; SQL> alter diskgroup TEST set attribute 'compatible.rdbms'='11.2';
Template 생성
test_hot 라는 HOT/HOTMIRROR 영역용 template 을 생성 하도록 하겠습니다.
SQL> alter diskgroup TEST add template test_hot attributes (hot mirrorhot);
지정 가능한 속성은 아래와 같습니다.
• 첫번째 인자 : HOT / COLD
• 두번째 인자 : MIRRORHOT / MIRRORCOLD
첫번째 HOT 과 COLD 는 주 extent를 위치 시킬 DISK의 영역을 지정하는데 사용하며, 두번째 MIRRORHOT 과 MIRRORCOLD 는 Redundancy 가 Normal 이기 때문에 mirror(두 번째) extent 의 위치를 지정 하는 것입니다.
test_cold 라는 COLD/MIIRORCOLD 영역용 template 을 생성 하도록 하겠습니다.
SQL> alter diskgroup TEST add template test_cold attributes (cold mirrorcold);
테이블스페이스 생성
테이블 스페이스를 생성하면 되며 위에서 생성한 Diskgroup 별로 테이블 스페이스를 생성 하도록 하겠습니다.
• hot 이름의 테이블 스페이스를 생성하고 HOT영역에 위치 시킵니다.
SQL> create tablespace hot datafile '+TEST(test_hot)' size 30G;
• cold 이름의 테이블 스페이스를 생성하고 COLD영역에 위치 시킵니다.
SQL> create tablespace cold datafile '+TEST(test_cold)' size 30G;
Test Table & Index Creation
테이블 생성은 많은 블록을 갖도록 생성 할 것이고, clustering factor 가 좋지 않은 인덱스를 2개 생성 하도록 하겠습니다.
테이블 생성
• HOT 영역에 IDP_HOT_TEST1, IDP_HOT_TEST2 2개 테이블 생성
-- IDP_HOT_TEST1
SQL> create table idp_hot_test1
pctfree 95 pctused 5
tablespace hot
as select object_id, object_name, status from dba_objects
order by dbms_random.value;
-- 동일 한 데이터를 1번더 insert 한다.
SQL> insert into idp_hot_test1
select * from idp_hot_test1
order by dbms_random.value;
-- IDP_HOT_TEST2
SQL> create table idp_hot_test2
pctfree 95 pctused 5
tablespace hot
as select object_id, object_type,timestamp from dba_objects
order by dbms_random.value;
• HOT 영역에 CTAS 로 IDP_HOT_TEST1, IDP_HOT_TEST2 2개 테이블 생성
-- IDP_COLD_TEST1 SQL> create table idp_cold_test1 pctfree 95 pctused 5 tablespace cold as select object_id, object_name, status from dba_objects order by dbms_random.value; -- IDP_COLD_TEST1 SQL> create table idp_cold_test2 pctfree 95 pctused 5 tablespace cold as select object_id, object_type,timestamp from dba_objects order by dbms_random.value;
• dba_tables 조회
SQL> select table_name,pct_free,pct_used from dba_tables where table_name like 'IDP%';

위와 같이 ASSM 을 사용하기 때문에 PCT_USED는 사용할 수 없지만 PCT_FREE가 95 임을 확인 할 수 있으며, 한 블록에 들어가 있는 row 수는 상당히 적을 것이고 많은 블록이 사용 되게 됩니다.
인덱스 생성
인덱스는 IDP_HOT_TEST1 과 IDP_COLD_TEST1 에 만 생성하도록 하겠습니다.
SQL> create index idp_hot_test1_id_idx on idp_hot_test1(object_id) tablespace hot; SQL> create index idp_cold_test1_id_idx on idp_cold_test1(object_id) tablespace cold;
생성된 index의 clustering factor 를 보면 아래와 같이 아주 좋지 않게 생성 되어 있는 것을 확인 할 수 있으며 object_id 가 여러 블록 , 넓은 범위로 흩어져 있다는 것을 알 수 있습니다.
SQL> select index_name, table_owner, table_name, clustering_factor from dba_indexes where index_name like 'IDP%';

마지막으로 통계정보를 갱신 합니다.
SQL> EXEC DBMS_STATS.GATHER_TABLE_STATS(ownname=>'SYS',tabname=>'idp_hot_test1'); SQL> EXEC DBMS_STATS.GATHER_TABLE_STATS(ownname=>'SYS',tabname=>'idp_hot_test2'); SQL> EXEC DBMS_STATS.GATHER_TABLE_STATS(ownname=>'SYS',tabname=>'idp_cold_test1'); SQL> EXEC DBMS_STATS.GATHER_TABLE_STATS(ownname=>'SYS',tabname=>'idp_cold_test2');
Query Test
쿼리 수행
동일한 쿼리를 10회 수행하였으며 set timing on 설정을 하여 나온 시간으로 측정 하였고 쿼리수행 전 shared_pool 과 bffer_cafhe 를 flush 수행하고 진행하였습니다.
쿼리는 아래와 같습니다.
• HOT 영역 TEST 쿼리
SQL> select /*+ use_nl(a b) reading(a b) */ * from idp_hot_test1 a, idp_hot_test2 b where a.object_id = b.object_id ;
• COLD 영역 TEST 쿼리
SQL> select /*+ use_nl(a b) reading(a b) */ * from idp_cold_test1 a, idp_cold_test2 b where a.object_id = b.object_id ;
[참고] HINT 없이 사용하게 되면 HASH 로 수행됨으로 nested loop 로 실행되게 하고자 use_nl 를 사용하였습니다.
실행 계획
• HOT 테이블
• COLD 테이블
수행 결과
2개의 쿼리의 실행계획 및 Operation 단계마다 읽게 되는 Rows 등이 동일 하며 set timing on 을 설정 후 결과는 아래와 같습니다.
[참고] HOT영역의 쿼리를 선 수행 후, COLD 영역의 쿼리를 수행하였습니다.
|
시간기준 : 초 |
회 차 |
HOT |
|
COLD |
|
|
1 |
26.37 |
|
26.43 |
|
|
2 |
18.14 |
|
21.17 |
|
|
3 |
29.54 |
|
28.11 |
|
|
4 |
21.45 |
|
26.68 |
|
|
5 |
26.33 |
|
28.64 |
|
|
6 |
24.01 |
|
27.82 |
|
|
7 |
27.99 |
|
34.66 |
|
|
8 |
21.42 |
|
24.91 |
|
|
9 |
26.08 |
|
24.21 |
|
|
10 |
24.25 |
|
25.47 |
|
|
합 |
245.58 |
|
268.1 |
|
|
1회평균 |
24.558 |
|
26.81 |
|
|
|
|
|
|
|
|
1회 평균 시간차 |
2.252 |
|
|
|
|
|
|
|
|
테스트의 목적은 IDP 라는 기능이 구현이 되는 것을 확인 해보고자 하는 것 이며, 쿼리 및 테이블 형태, 조인 형태에 따라 HOT영역의 테이블을 Access 하는 쿼리의 수행 속도와, COLD 영역 테이블을 Access 하는 쿼리의 수행 속도차이는 있을 것이라고 생각 됩니다.
ASM IDP 배포 정보 확인
배포가 완료된 후 HOT영역과 COLD 영역에 대해서 정보조회가 가능하며, IDP에 대한 정보는 아래의 딕셔너리 뷰를 통해서 확인 가능합니다.
V$ASM_DISKGROUP
HOT_USED_MB : HOT 영역에서 사용된MB
COLD_USED_MB : COLD 영역에서 사용된 MB
V$ASM_FILE
PRIMARY_REGION : 주 EXTENT 할당을 위해 사용된 영역
MIRROR_REGION : 미러(MIRROR) EXTENT 할당을 위해 사용 된 영역
V$ASM_TEMPLATE
PRIMARY_REGION : 주 EXTENT 할당을 위해 사용된 영역
MIRROR_REGION : 미러 EXTENT 할당을 위해 사용된 영역
V$ASM_DISK_IOSTAT
HOT 과 COLD 영역의 대한 I/O 통계를 나타냅니다.
아래 쿼리를 이용하면 현재 TEST DISKGROUP 에 있는 TEMPLATE 이름과 어느 선호 영역으로(HOT or COLD) 지정되어 있는지 확인 할 수 있습니다.
set lines 300 col DISKGROUP for a30 col "TEMPLAE NAME" for a30 select dg.name as diskgroup, t.name as "TEMPLATE NAME", t.stripe, t.redundancy,t.primary_region, t.mirror_region from v$asm_diskgroup dg, v$asm_template t where dg.group_number = t.group_number and dg.name='TEST' order by t.name;

업무적 사용의 예와 영역 이동
ASM은 DISK의 선호영역(HOT,COLD) 속성에 대해서 자동으로 결정 하지는 않습니다 즉 이 말은 DBA나 엔지니어가 해당 테이블스페이스, 혹은 파일의 사용용도나 활동성에 따라 이러한 속성들을 결정하고, 변경 해줘야 한다는 것을 의미합니다.
RMAN 백업셋 파일을 ASM영역 내에 위치 시킨다고 할 때 백업은 피크 시간이 아닌 시간에 백업이 진행되기 때문에 해당 시간에 HOT 영역에 위치 시키면 수행을 줄이는데도 도움이 될수 있습니다.
또는 특정 시간에 사용량이 많은 테이블스페이스에 대해서도 HOT 영역으로 변경 하여 작업 후 다시 COLD영역으로 변경 하여 사용하는 형태도 고려해 볼 수 있습니다.
모든 테이블스페이스나 파일을 HOT영역에는 위치 시킬 수가 없는 것이 사실이며, 업무에 따라서 적절히 배치를 하여 사용하면 좀더 좋은 효과를 볼 수 있을 것이라고 생각 됩니다.
영역 이동
TEST.258.758975835 파일을 cold에서 HOT 영역으로 속성을 변경할 때는 아래 명령어를 사용하면 됩니다.
SQL> alter diskgroup TEST modify file '+test/orcl/datafile/TEST.258.758975835' attributes (hot mirrorhot);
위의 명령을 수행한다고 해서 기존의 EXTENT가 COLD영역에서 HOT 영역으로 이동하는 것은 아니며, 새로운 EXTENT 부터 지정된 HOT 영역에 할당되게 됩니다.
그래서 수동으로 REBALANCE 를 하게 되면 기존의 EXTENT 도 HOT영역으로 이동하게 됩니다.
ASM 인스턴스에 SYSASM 권한으로 접속 후 아래와 같이 rebalance 를 진행 할 수 있습니다.
SQL> alter diskgroup test rebalance power 9;
power 의 인자 값은 rebalance 시 숫자가 높을수록 많은 CPU의 자원을 많이 활용하여 빠른 rebalance 를 하겠다를 의미하며, 1의 경우 9와 반대로 Rebalance시간은 오래 걸리더라도 자원 소모를 적게 하겠다라는 의미 입니다.
Conclusion
ASM 영역의 선호 속성을 지정 할 수 있다 라는 것과 지정함에 따라 성능이 개선되는 부분을 확인 해보았습니다. 쿼리나 데이터 분포도, join 의 형태에 따라 HOT과 COLD 영역의 수행속도 차이는 있을 것 입니다.
다만 아쉬운 부분은 Redundancy 를 Normal(Mirror) 로 설정해야 하기 때문에 사용할 수 있는 가용 공간 가용성이 1/2 로 줄어든다는 것입니다.
Storage 에서 이미 Raid 1 이나 5 또는 1+0 등으로 구성되어 보내온 LUN 볼륨을 ASM에서 다시 Redundancy 를 Normal 로 설정함에 따라 용량이 줄어 드는 부분이 있기 때문에 이 부분이 가장 아쉬운 부분이라고 할 수 있을 것 같습니다.
연관된 다른글



Principal DBA(MySQL, AWS Aurora, Oracle)
핀테크 서비스인 핀다에서 데이터베이스를 운영하고 있어요(at finda.co.kr)
Previous - 당근마켓, 위메프, Oracle Korea ACS / Fedora Kor UserGroup 운영중
Database 외에도 NoSQL , Linux , Python, Cloud, Http/PHP CGI 등에도 관심이 있습니다
purityboy83@gmail.com / admin@hoing.io


