









Last Updated on 5월 28, 2023 by Jade(정현호)
안녕하세요
이번 포스팅은 Amazon Aurora MySQL 에 관한 연재글로 해당 글은 아래 이전 글에서 이어지는 글 입니다.

1. Aurora 파리미터 그룹
이전 포스팅에서 생성한 Amazon Aurora 클러스터의 파라미터를 변경을 진행하도록 하겠습니다. 기본 파라미터 그룹에서는 수정이 불가 함으로 사용하면서 파라미터 수정할 경우는 언제든지 있을수 있기 때문에 먼저 파라미터 그룹 생성 및 적용하는 것이 좋습니다.
[참고] 기본 파라미터 그룹에서 파라미터 수정을 하게 되면 아래와 같이 에러가 발생되게 됨으로 별도로 파라미터 그룹의 생성이 필요 합니다.
저장 중 오류: Cannot modify a default parameter group. (Service: AmazonRDS; Status Code: 400; Error Code: InvalidParameterValue; Request ID: 7568ef90-8edd-468f-b348-3fc8797d64ae; Proxy: null)
1-1 파라미터 그룹 생성
파라미터 그룹 -> 파리미터 그룹 생성 을 선택 합니다.
1-2 정보 입력 및 그룹 생성
파라미터 그룹 이름과 설명을 입력 후 하단의 생성을 선택 합니다.
"유형" 항목에서는 "DB Parameter Group" 과 "DB Cluster Parameter Group" 을 선택 할 수 있으며 설명은 아래에 기술하도록 하겠으며 포스팅에서는 "DB Cluster Parameter Group" 으로 생성하도록 하겠습니다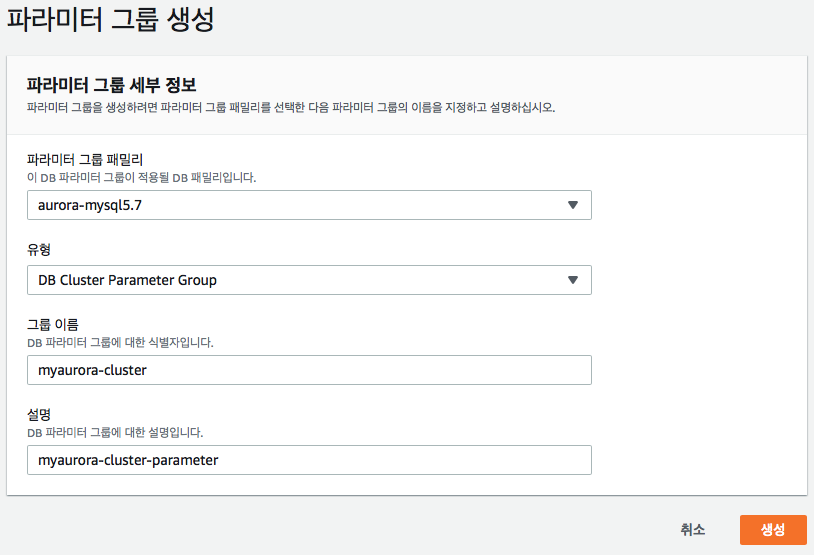
DB 클러스터 파라미터 그룹 과 DB 파라미터 그룹의 차이는 적용 범위에서 차이가 발생하게 됩니다.
DB Cluster Parameter Group 은 클러스터내 모든 Aurora DB 인스턴스에 공통적으로 적용되는 파라미터 그룹의 역할을 하게 되며 파라미터의 기본값도 포함되어 있습니다.
DB Parameter Group 은 클러스터내 각 개별의 Aurora 단일 DB 인스턴스의 파라미터 그룹을 의미 합니다. 특정 인스턴스에만 별도로 파라미터 값을 다르게 설정해야할 필요가 있을 때 DB Parameter Group 을 별도로 생성하여 해당 인스턴스에서 사용하는 형태로 이용할 수 있습니다.
1-3 클러스터 수정
데이터베이스 -> 클러스터 선택 -> 수정 을 선택 합니다.
1-4 파리미터 그룹 선택
추가 구성 -> 데이터베이스 옵션 -> DB 클러스터 파라미터 그룹 항목에서 위에서 생성한 파라미터 그룹을 선택 후 하단의 계속을 선택 합니다.
1-5 변경 적용
수정 사항에 대한 반영 시점을 선택해야 합니다 다음 유지 관리 때 적용 할 것인지, 지금 즉시 적용 할지를 선택 할 수 있으며, 포스팅에서는 즉시 적용 을 선택 하였습니다.
1-6 클러스터 구성 확인
클러스터 -> 구성 항목에서 보면 아래와 같이 DB 클러스터 파라미터 그룹이 위에서 지정한 파라미터 그룹으로 바로 변경 되어 반영 된 것을 확인 할 수 있습니다.
1-7 파라미터 수정
포스팅에서는 예시로 max_connections 파라미터를 변경 하도록 하겠습니다. 파라미터 검색 후 파라미터 편집을 선택 합니다.
파라미터 별로 default 값을 다 다르며 max_connections 의 기본 값은 아래의 계산으로 기본값이 산정 됩니다.
GREATEST(
{log(DBInstanceClassMemory/805306368)*45},
{log(DBInstanceClassMemory/8187281408)*1000}
)
Aurora 인스턴스에 접속하여 조회를 해보면 실제 설정된 값을 아래와 같이 확인 할 수 있습니다.
MySQL [mysql]> show variables like '%max_connections%'; +------------------------------+-------+ | Variable_name | Value | +------------------------------+-------+ | aurora_max_connections_limit | 16000 | | max_connections | 45 | +------------------------------+-------+
변경 할 파라미터 값을 입력 후 "변경 사항 저장" 을 선택 합니다 포스팅에서는 1000 으로 변경을 하였습니다.
그리고 바로 조회하면 적용 유형이 dynamic 이기 때문에 접속 해제 없이 해당 세션에서 바로 적용 받은 것을 확인 할 수 있습니다.
MySQL [mysql]> show variables like '%max_connections%'; +------------------------------+-------+ | Variable_name | Value | +------------------------------+-------+ | aurora_max_connections_limit | 16000 | | max_connections | 45 | +------------------------------+-------+ 2 rows in set (0.008 sec) --파라미터 적용 후 조회 MySQL [mysql]> show variables like '%max_connections%'; +------------------------------+-------+ | Variable_name | Value | +------------------------------+-------+ | aurora_max_connections_limit | 16000 | | max_connections | 1000 | +------------------------------+-------+ 2 rows in set (0.001 sec)
위에서는 파라미터 타입이 dynamic 임으로 바로 적용이 되게 됩니다 하지만 아래와 같이 적용 유형이 static 이라면 인스턴스 재시작이 필요 합니다.
AWS 클러스터 재시작
Aurora MySQL 버전에 따라서 라이터 인스턴스 재기동에 관련된 동작이 차이가 나게 됩니다.
Aurora PostgreSQL 및 버전 2.10 이전 Aurora MySQL
Aurora PostgreSQL 호환 버전 과 Aurora MySQL 호환 버전 버전 1 및 버전 2.10 이전 버전의 경우 클러스터의 라이터 DB 인스턴스를 재부팅 하여 전체 Aurora DB 클러스터를 재부팅 합니다.
즉 라이터 DB 인스턴스를 재부팅하면 클러스터의 각 리더 DB 인스턴스에 대해서도 재부팅이 시작됩니다.
이 방식으로 클러스터 전체 파라미터 변경 사항이 모든 DB 인스턴스에 동시에 적용하게 할 수 있습니다.
그러나 모든 DB 인스턴스를 재부팅하면 클러스터가 잠시 중단 됨에 따라 전제 다운이 발생 됩니다.
Aurora MySQL 버전 2.10 이상
Aurora MySQL 버전 2.10 이상에서는 클러스터의 리더 인스턴스를 재부팅하지 않고 Aurora MySQL 클러스터의 라이터 인스턴스를 재부팅할 수 있습니다.
이렇게 하면 라이터 인스턴스를 재부팅하는 동안 읽기 작업에 대한 클러스터의 고가용성을 유지하는 데 도움이 됩니다. 나중에 편리한 일정에 따라 리더 인스턴스를 재부팅할 수 있습니다.
그래서 지금 사용하는 버전이 2.10 이전 버전이라면 라이터 인스턴스의 재기동에 주의 해야 합니다.
2. 읽기 전용 복제본
현재 구성한 Amazon Aurora Cluster DB 는 클러스터 내 1개의 기본 인스턴스(마스터) 만 존재하는 상태 입니다. 기존이 클러스터로 구성되며 인스턴스 레벨의 멀티 AZ가 지원되지 않기 때문에 읽기 복제본 인스턴스를 사용한 문제시 장애복구 및 다운타임을 줄이게 됩니다.
그래서 온프레미스의 MySQL 이나 RDS MySQL 도 Replica 인스턴스가 필요하지만 Amazon Aurora 의 경우도 거의 필수적으로 읽기 복제본 인스턴스를 같이 구성할 필요가 있습니다.
[참고] 운영 방침과 비지니스의 특성에 따라 달라질 수 있으며, Dev(개발계)나 QA 나 TEST 단계의 DB 의 경우 비용 적인 과 다운 타임에 대한 부분이 비교적 자유롭기 때문에 문제시 재기동을 하거나 자동 백업된 snapshot 을 통해 재생성을 할 목적으로 읽기 복제본 인스턴스 없이 클러스터내 단일 인스턴스(기본,마스터) 로만 구성해서 사용할 수 있습니다.
2-1 Aurora 의 복제 방식 차이
Amazon Aurora 는 온프레미스의 MySQL 또는 RDS MySQL 과는 다른 형태로 복제가 수행되게 됩니다.
관련 된 상세 내용은 이전 포스팅을 참조하시면 됩니다
Amazon Aurora DB - AWS RDS Aurora MySQL(1)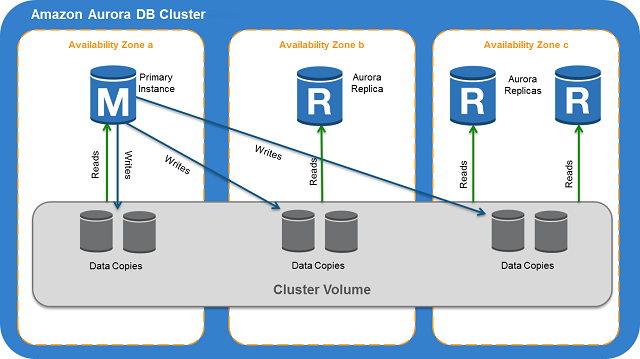
DB 인스턴스의 데이터를 관리하는 클러스터 볼륨 으로 구성되어 있습니다. Aurora 클러스터 볼륨은 다중 가용 영역(AZ) 아우르는 스토리지 볼륨으로, 각 가용 영역(AZ) 에는 DB 클러스터 데이터의 사본이 있습니다. 3개의 가용 영역에 거쳐 AZ 당 2개씩, 총 6개 스토리지 노드의 복제를 저장하여 고가용성 제공 하게 됩니다.
일반 MySQL의 네트워크를 통해서 Binlog 내용을 전송 및 재수행하여 복제 동기화하는 것과 달리 Aurora DB 는 공유 스토리지 기능을 통해서 읽기 복제본(Read Replica) 과 복제 및 동기화가 구현하고 있으며 그에 따라 복제 부하가 적으며 부하의 복제의 Gap이 매우 작으며, Aurora 읽기 복제본 인스턴스를 추가 시 별도의 복제 복사본이 만들지 않고 빠르게 인스턴스를 추가 할수 있습니다.
더 자세한 내용은 이전 포스팅을 참조하시면 됩니다
Amazon Aurora DB - AWS RDS Aurora MySQL(1)
2-1 읽기 추가
읽기 복제본은 아래 순서와 유사하게 진행하시면 됩니다.
데이터베이스 -> 클러스터 선택 -> 작업 -> 읽기 추가 순으로 선택을 합니다.
[참고] 복제본 생성은 Replica 또는 Slave 의 구성이 아닌 영문 Clone 을 의미하며, 수행하게 되면 기존의 데이터베이스의 모든 데이터 와 Writer DB 인스턴스가 포함된 새로운 클러스터가 복제 생성되는 기능 입니다.
2-2 인스턴스 식별자 및 크기 지정
읽기 복제본을 추가 하기 위해서 몇 가지 항목을 입력 하고 선택 해야 합니다. 먼저 DB 인스턴스 식별자를 입력해야 합니다 포스팅에서는 기본 인스턴스에 맞춰서 식별자를 지정하였습니다.
DB 인스턴스의 크기도 클러스터내 인스턴스 별로 각각 설정이 가능합니다. 
2-3 연결 설정
연결 항목에서는 퍼블릭 엑세스 가능 여부 와 가용 영역(AZ) 를 선택 할수 있으며 포트는 변경이 불가능 합니다.
추가 구성에서 "장애 조치 우선 순위" 를 지정해야 하며 이전에 기본 인스턴스(마스터) 에서는 티어-0 을 선택하였기 때문에 이번에 생성하는 읽기 복제본은 더 후 순위인 티어-1 를 지정하도록 하겠습니다 (아래에서 설명 추가)
[참고] 장애 조치 우선 순위는 기본 인스턴스(마스터)의 장애시 다수의 읽기 복제본 중에서 기본 인스턴스로 승격 시킬 인스턴스에 대한 우선 순위를 지정하는 옵션 입니다. 우선 순위가 가장 높은 복제본(티어 0으로 시작)을 새로운 기본 인스턴스로 승격시킵니다. 포스팅에서는 기본인스턴스를 가장 높은 우선 순위(티어 0)로 설정하고 진행하였습니다.
2-4 모니터링 및 유지관리
포스팅에서는 Enhanced 모니터링 을 활성화 하였으며, 별도로 업그레이드 등을 테스트 하기 위해서 유지 관리에서 "마이너 버전 자동 업그레이드 사용" 기능을 비활성화(uncheck) 하였습니다.
설정이 마무리가 되었다면 하단의 "Add reader" 를 클릭 합니다.
2-5 생성 완료
생성이 시작 하고 나면 아래와 같이 역할이 읽기 인 두번째 인스턴스를 확인할 수 있으며, 상태는 처음에는 생성 중 으로 확인되게 됩니다.
생성이 완료 되면 아래와 같이 상태에 사용 가능 으로 확인이 되게 됩니다.
2-6 접속
읽기 인스턴스에 접속 하는 방법은 크게 2가지 입니다.
Cluster Reader endpoint url 를 통해서 접속하거나 인스턴스의 개별 endpoint 로 접속 입니다.
• 클러스터 엔드포인트
아래 이미지와 같이 클러스터 선택 -> 연결 및 보안 항목에서 엔드포인트 정보를 확인 할 수 있습니다. 유형 항목에 써있는 것처럼 1개는 쓰기 가능한 기본 인스턴스로 접속하는 엔드포인트이며, 하나는 읽기 전용 복제본 인스턴스에만 접속이 가능한 엔드포인트이고 읽기 인스턴스의 엔드포인트에는 주소 중간에 "ro" 가 명시적으로 기재되어 있습니다.
• 인스턴스 엔드포인트
인스턴스 별로도 각각 개별 엔드포인트 접속 주소는 할당되어 있습니다. 인스턴스 선택 후 연결 & 보안 탭에서 엔드포인트 정보를 확인 할 수 있습니다.
위와 같이 생성한 읽기 인스턴스에 접속 할 수 있으며 서비스 용도의 애플리케이션에서는 ro 가 붙은 클러스터 읽기 엔드포인트 를 통해 접속해야 합니다. 물론 쓰기 인스턴스로 접속을 위해서도 클러스터 쓰기 엔드포인트 로 접속을 해야 합니다.
그래야 장애나 기타 문제가 발생하여 페일오버 되어 읽기 인스턴스가 기본 인스턴스로 승격이 되었을 경우 접속 주소의 변경 없이 그대로 사용할 수 있습니다.
Reader Endpoint 로 접속해보면 정상적으로 접속되는 것을 확인 할 수 있습니다.
user$ mysql -u admin -p -h myaurora.cluster-ro-xx.rds.amazonaws.com Enter password: Server version: 5.7.12 MySQL Community Server (GPL) Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. MySQL [(none)]> use mysql; Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A
3. 장애 조치(페일오버)
Amazon Aurora DB는 기본적으로 생성 시 쓰기 가능한 기본 인스턴스를 포함한 클러스터가 생성되게 됩니다. 의미대로 장애의 발생이나 계획된 작업(PM) 에 따른 인스턴스의 가용성 보장의 기능이 있음을 의미 합니다.
장애 조치 라는 기능으로 읽기 인스턴스를 쓰기 가능한 기본 인스턴스로 승격을 할 수 있습니다. 특정한 문제로 쓰기 인스턴스가 재기동을 계속적으로 시도하고 페일오버가 진행되지 않을 경우(실제로 격은 사례) 운영자가 개입하여 페일오버를 진행할 수 있습니다. 그외 계획된 또는 의도하는 바가 있어서 읽기 인스턴스를 쓰기 인스턴스로 승격할 수 있습니다.
이럴 경우 장애 조치 기능을 통해서 fail-over 를 할 수 있습니다.
3-1 장애 조치 우선 순위
장애 조치 수행시 특정 인스턴스를 기본 인스턴스(마스터) 로 지정하는 기능은 제공하지 않습니다.
(웹 콘솔 메뉴 상에서는 존재 하지 않음)
AWS Aurora MySQL은 장애 조치 우선 순위(Failover Priority) 설정에 따라서 다수의 읽기 인스턴스 중에서 가장 우선 순위가 높은 인스턴스가 기본 인스턴스로 승격되게 됩니다.
아래 이미지 와 같이 현재 포스팅에서는 쓰기 가능 기본 인스턴스는 순위가 0 으로 설정 되어 있습니다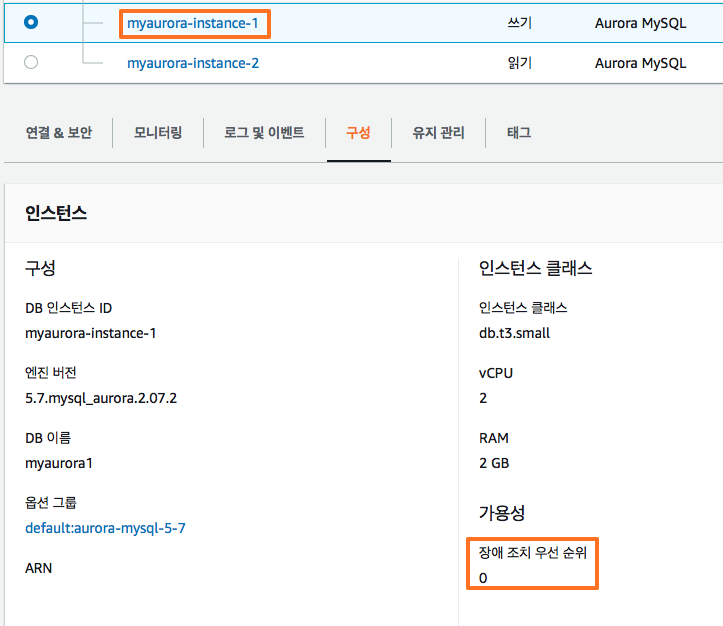
위에서 생성한 읽기 인스턴스는 우선 순위 1(티어-1) 로 되어 있습니다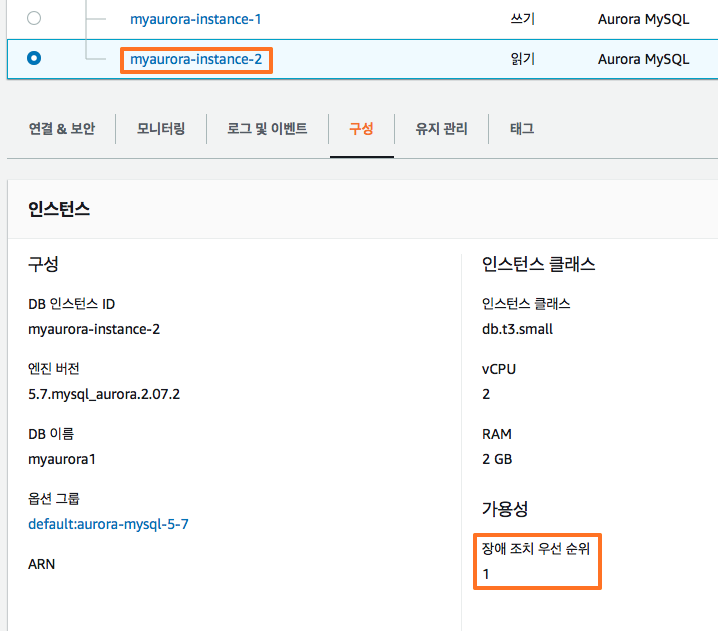
이렇게 인스턴스 별로 설정된 우선 순위를 확인 할 수 있습니다.
3-2 작업 실행
개별 인스턴스 선택 -> 작업 -> 장애 조치 순으로 선택을 합니다.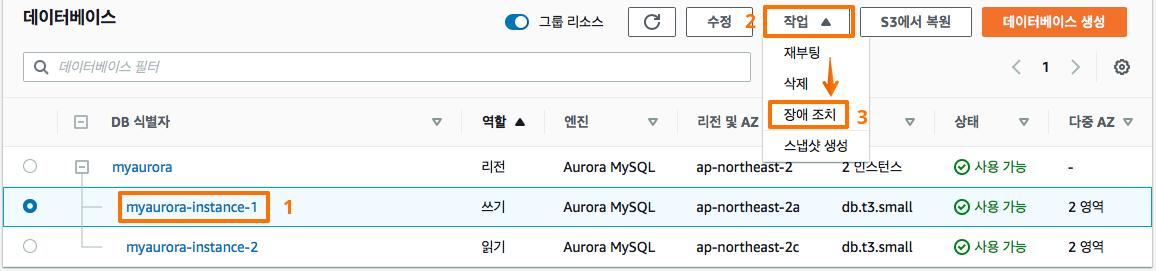
3-3 장애 조치 실행
이전 단계에서 작업 -> 장애 조치 메뉴를 선택하면 아래와 같이 장애 조치 수행 여부를 확인 하게 되며, 하단의 "장애 조치" 를 선택하면 fail-over 가 진행되게 됩니다.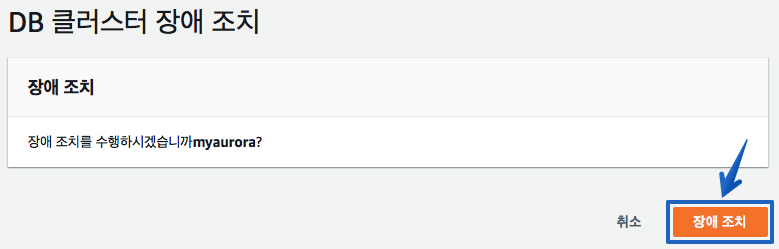
장애 조치가 실행 되면 기존의 Writer 인스턴스와 프로모션 대상(승격 대상)의 리더 인스턴스 모두 재기동 되며 아래의 이벤트 로그와 같이 리더 재시작 -> writer 재시작 순으로 진행되면서 장애 조치가 수행 되게 됩니다.
#### 순서는 위에서 아래 입니다.
# 인스턴스 02 - Reader
May 15, 2022, 3:47:04 PM UTC
DB instance shutdown
May 15, 2022, 3:47:12 PM UTC
DB instance restarted
# 인스턴스01 - Writer
May 15, 2022, 3:47:12 PM UTC
A new writer was promoted. Restarting database as a reader.
May 15, 2022, 3:47:17 PM UTC
DB instance restarted
3-4 장애 조치 완료
장애 조치가 수행되게 되면 아래와 같이 클러스터의 상태가 "Failing-over" 로 바뀌게 됩니다.
완료가 되면 읽기 역할 이었던 instance-2 가 쓰기 역할로 변경된 것을 확인 할 수 있습니다.
3-5 장애 조치 우선 순위 변경
3-5-1 수정 메뉴 선택
장애 조치 우선 순위의 변경은 수정 메뉴를 통해서 변경 할 수 있습니다.
인스턴스 선택 -> 수정 메뉴를 선택 합니다.
3-5-2 우선 순위 변경
추가 구성 항목에서 "장애 조치 우선 순위" 를 원하는 순위로 선택 후 하단의 "계속" 버튼을 클릭 합니다.
3-5-2 DB 인스턴스 수정
수정 사항에 대해서 적용 시점을 선택 하면 되며 포스팅에서는 즉시 적용 을 선택 하였습니다. 선택이 완료 되었다면 하단의 "DB 인스턴스 수정" 을 클릭 하여 수정을 마무리 합니다.
3-5-2 인스턴스 수정 완료
수정이 적용되면 상태가 아래와 같이 "수정 중" 으로 변경 되게 됩니다.
적용이 완료 되면 인스턴스 -> 구성 항목에서 변경된 우선 순위를 확인 할 수 있습니다.
4. Class 변경
이번에는 AWS Aurora 인스턴스의 Class 를 변경 해보도록 하겠습니다.
Reader 인스턴스 Class 변경 보다는 Writer 인스턴스의 Class 변경에 대해서 확인 해보도록 하겠습니다.
Writer 인스턴스의 Class 변경시에는 어쩔 수 없이 Failover가 진행 해야 하거나 진행되게 됩니다. Writer 인스턴스의 Class 변경 방법 또는 순서에 대해서는 크게 3가지로 분류 할 수 있습니다.
- Writer 로 사용할 Reader 인스턴스를 Class 변경, 장애 조치 우선 순위(Failover Priority)를 다른 Reader 인스턴스 보다 우선 순위가 높게 설정, 그 다음 Failover 실행
(숫자가 낮을 수록 우선순위가 높음) - 사용자가 Failover 를 먼저 진행 하여 Reader 로 변경 후에 Class를 변경, 그 다음 다시 Failover
- Writer 인스턴스인 상태에서 수정(Modify)를 하여 Class를 변경 하는 방법
이와 같이 Writer 인스턴스에 대해서 Class 변경을 실행시에는 결국은 모두 Failover를 해야하는 상황이 되게 됩니다.
세번째 Writer 인스턴스를 대상으로 수정(Modify)를 하여 Class를 변경할 때에도 Failover가 자동적으로 실행되게 됩니다.
아래의 이미지와 같이 테스트 Aurora Cluster RDS는 db.t3.large 클래스로 되어있고 Writer,Reader 2개의 인스턴스를 포함하고 있는 상태 입니다.

Writer 인스턴스인 test-aurora-01에 대해서 수정(Modify) 메뉴를 통해 Class 를 변경 하도록 하겠습니다. 포스팅에서는 db.t4g.medium 으로 변경 하였고, x86-86 인텔 CPU 에서 Arm-64 Graviton CPU 시리즈로도 Class 변경이 가능합니다.(반대로도 가능)

변경을 하게 되면 아래 이미지와 같이 초반에는 Writer 인스턴스의 상태가 Modify 로 확인 되게 됩니다.

시간이 조금 지난 뒤에 본격적으로 인스턴스의 Class 변경을 위해서 먼저 자동 Failover가 수행되게 됩니다.
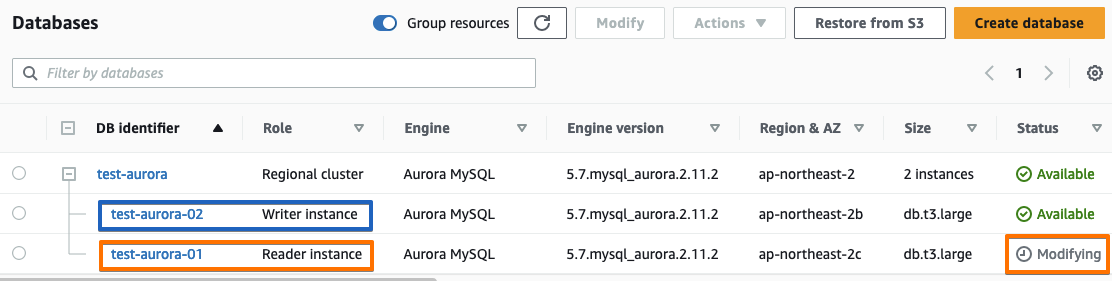
Failover 가 되는 과정에서 Writer 인스턴스와 Reader 중에서 Writer 인스턴스로 승격되는 대상의 인스턴스 2개 모두는 Rebooting 이 수행되게 되며, Reboot이 되면서 Writer <-> Reader 의 Failover 가 수행됩니다.
AWS Aurora 의 Failover시 Reboot 되어 접속이 불가능한 시간은 보통 5~10초 정도입니다. 이 시간(수초)동안 잠시 쓰기 작업은 불가능해지기 때문에, 사용하는 서비스에 따라서 점검 등의 준비가 필요할 수 도 있습니다.
또는 사용하는 애플리케이션 환경에 따라서 세션 재접속을 위한 별도의 Action이 필요할 수도 있습니다.
Failover 가 되어 Reader 로 된 이후 본격적으로 Class 변경 작업이 수행이 되며, 이 시간동안은 해당 인스턴스는 사용이 불가능한 상태로 변경 작업이 수행 되며, 테스트 시스템에서는 290초 가량이 소요 되었습니다. Class 변경에 소요된 시간은 상황과 Class 등에 따라 다르므로 참고만 하시면 됩니다.
위와 같이 인스턴스가 2대인 경우 Class 변경 작업시에 1대만 사용 가능한 상태가 되기 때문에 Cluster Reader Endpoint 로 접속하는 경우는 Writer 인스턴스로 접속이 되게 됩니다.
그리고 Reader 로 변경된 인스턴스가 Class 변경이 완료되어 인스턴스가 정상적으로 사용이 가능한 시점 부터는 Cluster Reader Endpoint 접속은 다시 Reader 인스턴스로 접속 되게 됩니다.
사용하는 환경이나 정책에 따라서 Writer 로 사용하였던 인스턴스(현재는 Reader로 변경된 인스턴스)에 대해서 다시 Writer 인스턴스로 변경하고자 할 수 있습니다. 그럴 때는 아래 이미지와 같이 한번 더 명시적으로 Failover 를 수행하시면 됩니다.
다만 다수의 Reader가 존재시에는 Writer 로 승격하고자 하는 Reader 인스턴스의 장애 조치 우선 순위(Failover Priority)를 다른 Reader 인스턴스 보다 우선 순위가 높은지를 확인 해야 합니다.

이번 포스팅은 여기서 마무리 하도록 하겠습니다. 추가 적인 내용은 다음 포스팅에서 이어서 다루도록 하겠습니다.
다음 이어지는 글
연관된 다른 글






Principal DBA(MySQL, AWS Aurora, Oracle)
핀테크 서비스인 핀다에서 데이터베이스를 운영하고 있어요(at finda.co.kr)
Previous - 당근마켓, 위메프, Oracle Korea ACS / Fedora Kor UserGroup 운영중
Database 외에도 NoSQL , Linux , Python, Cloud, Http/PHP CGI 등에도 관심이 있습니다
purityboy83@gmail.com / admin@hoing.io
