Last Updated on 11월 28, 2023 by Jade(정현호)
안녕하세요
이번 포스팅에서는 Amazon Aurora MySQL 에 대해서 확인하는 내용으로 연재글의 첫 번째 글 입니다.
Contents
1. Amazon RDS
Amazon Relational Database Service(RDS) 를 사용하면 클라우드에서 관계형 데이터베이스를 간편하게 설정, 운영 및 확장할 수 있습니다. 하드웨어 프로비저닝, 데이터베이스 설정, 패치 및 백업과 같은 시간 소모적인 관리 작업을 자동화하면서 비용 효율적이고 크기 조정 가능한 용량을 제공합니다. 사용자가 애플리케이션에 집중하여 애플리케이션에 필요한 빠른 성능, 고가용성, 보안 및 호환성을 제공할 수 있도록 지원합니다.

[Understanding Amazon Relational Database Service (RDS)]
Relational Database 의 PaaS형 클라우드 서비스를 의미하며 PaaS 형 Database 서비스를 표현하는 단어 중 많이 사용 되는 용어로 완전 관리형 이라는 표현이 여러 클라우드사에서 공통적으로 사용되며 그 단어의 의미대로 클라우드 서비스사가 데이터베이스에 대한 모든 관리를 해주는 서비스 형 데이터베이스를 의미 합니다.
AWS RDS 에서는 여러 데이터베이스 인스턴스 유형을 제공하며 Amazon Aurora, PostgreSQL, MySQL, MariaDB, Oracle Database 및 SQL Server 6개 의 데이터베이스에 대해서 서비스를 제공되고 있습니다.
AWS 에서 서비스 되는 RDS 중에서 이번 포스팅에서는 Amazon Aurora 에 대해서 확인 해보고자 합니다.
[참고] 포스팅에서는 Aurora MySQL/PostgreSQL 중에서 Aurora MySQL 중점으로 내용이 기술되어 있습니다.
2. Amazon Aurora
Amazon Aurora 는 MySQL 과 PostgreSQL 과 호환되는 완전 관리형 데이터 베이스 엔진 입니다. 기존의 MySQL 및 PostgreSQL 데이터베이스에서 사용되는 코드 ,SQL 및 애플리케이션 모두 Aurora 에서도 사용 할 수 있습니다. 그리고 일부 워크로드의 경우 Aurora 는 MySQL 의 처리량을 최대 5대 , PostgreSQL 의 처리량 3배를 제공할 수 있는 성능을 지원하고 있습니다.

기존의 MySQL 및 PostgreSQL 과 달리 Aurora 에서는 고성능 스토리지 시스템이 포함되어 있으며 Aurora 는 이런 빠른 분산 스토리지 시스템을 사용할 수 있도록 설계가 되어 있다고 합니다. 포스팅 기준 Aurora 클러스터는 최대 128 TiB 까지 늘릴수 있으며 데이터베이스 클러스터링 과 복제를 자동화 , 표준화 기능을 제공 하고 있습니다.
[참고] AWS Aurora 에서 표현되는 용량은 GiB , TiB 로 보통 사용되는 GB 나 TB 와는 다른 기비바이트(GiB) , 테비바이트(TiB) 로 표기 하고 있습니다.
k 단위는 1000 을 의미 하는데, 컴퓨터에서 용량 1024 byte 를 kB 로 표현하므로 혼란을 야기하게 되었습니다.
적은 단위의 용량에서는 많이 차이가 나지는 않지만, 기가 테라 등으로 용량이 커지면서 그 차이는 엄청나게 벌어지게 되었습니다.
1TB 디스크를 구매하면 실제 사용할 수 있는 용량은 약 931GB 의 차이가 발생함을 의미 합니다.
이에 따라, 1024 에 해당하는 단위를 새로 만들어서 표현하도록 개발 되었으며 1 킬로 이진 바이트 = 2^10 바이트 = 1024 바이트 = 1 KiB 가 되게 됩니다.
Aurora 는 위에서 언급한 내용과 같이 Amazon RDS 서비스 중 일부분 으로 RDS 는 관계형 데이터베이스를 보다 쉽게 설정하고 동작 과 조작 , 확장 할 수 있게 해주는 PaaS형 클라우드 서비스 입니다.
Aurora 는 RDS AWS Management 콘솔 인터페이스, AWS CLI 명령 및 API 작업을 사용 할 수 있으며 프로비저닝,패치,백업,복구,장애 감지 및 수리 와 같은 일반적인 데이터베이스 작업을 처리 할 수 있습니다
일반적인 개별 데이터베이스 인스턴스 대신에 서버 클러스터내 복제를 통해 전체 데이터베이스가 동기화가 수행되며, 자동 클러스터링, 복제 및 스토리지 할당 기능 등을 통해 기존의 MySQL 이나 PostgreSQL 에 대한 배포,설정 작동 및 확장 작업등을 간편하게 사용할 수 있습니다.
3. Aurora DB Cluster
Amazon Aurora DB Cluster 는 하나 이상의 DB 인스턴스 와 DB 인스턴스의 데이터가 관리하는 공유 사용되는 클러스터 볼륨 으로 구성되어 있습니다. Aurora 클러스터 볼륨은 다중 가용 영역(AZ) 아우르는 스토리지 볼륨으로, 각 가용 영역(AZ) 에는 DB 클러스터 데이터의 사본이 있습니다.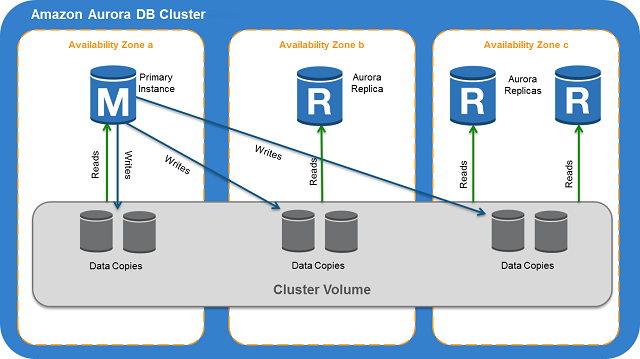
3개의 가용영역에 거쳐 AZ 당 2개씩, 총 6개 스토리지 노드의 복제를 저장하여 고가용성 제공 하게 됩니다. Aurora DB는 기본적으로 클러스터 형태로 구성되고 클러스터내 인스턴스는 아래와 같이 두 가지 유형의 DB 인스턴스로 구성 됩니다.
• 기본 DB 인스턴스 : 읽기 와 쓰기 작업 사용이 가능하고, 클러스터 볼륨의 모든 데이터 수정을 실행 하게 됩니다. Aurora DB 를 생성하게 되면 클러스터로 구성되고 클러스터마다 기본 DB 인스턴스가 하나 씩 존재 합니다.
• Aurora 복제본 : 기본 DB 인스턴스와 동일한 스토리지 볼륨에 연결되어 사용되고 읽기 작업만 지원 합니다. 각 Aurora DB 클러스터는 기본 DB 인스턴스에 더해 최대 15개 까지 읽기 전용인 Aurora 복제본을 구성하여 사용할 수 있으며 복제본 별로 가용 영역에 배포하여 고가용성을 유지 할수 있습니다.
기본 DB 인스턴스(Write 노드) 가 사용할 수 없는 상태가 되면 Aurora 는 읽기 복제본을 통해서 자동 장애 조치가 수행되게 됩니다. 또한 Aurora 읽기 복제본에 대해서 장애 조치에 대한 우선 순위를 지정할 수도 있습니다.
Aurora DB 는 위의 그림과 같이 그리고 아래에서 계속 설명될 내용과 같이 DB 인스턴스와 스토리지 노드가 분리되어 구성이 되어 있으며 컴퓨팅 용량과 스토리지 용량이 구분되어 있습니다.
Aurora DB Cluster 는 Multi AZ 미지원
AWS RDS 에서는 가용성을 높이기 위해서 사용되는 물리적으로 떨어져있는 다른 AZ에 복제본을 구성하여 사용하는 Multi AZ에 대해서 Aurora DB Cluster 를 지원하지 않습니다.
Multi AZ 는 사용하는 AZ의 문제가 발생되었을 경우 복제되고 있는 다른 AZ 로 failover 하여 가용성을 높이는 기능으로 콘솔이나 Endpoint 정보는 1개 이지만 실제로는 다수의 인스턴스의 생성과 Sync 복제가 수행이 되고 있습니다.
관련 된 포스팅 글

Amazon RDS는 다중 AZ 배포를 사용해 DB 인스턴스에 고가용성과 장애 조치 기능을 지원합니다. Amazon RDS는 다양한 기술을 이용해 장애 조치 지원을 제공합니다.
당연할 수도 있는 부분이 Aurora DB Cluster 는 공유 스토리지와 Redo 를 통해 Read Replica(읽기 복제본) 에서 지연이 적은 빠른 복제 동기화가 이루어지게 되고 Cluster 라는 의미대로 기본 DB 인스턴스(쓰기 노드) 의 문제가 발생시 읽기 복제본을 기본 DB 인스턴스로 변경하여(Failover) 하여 가용성을 높이는 기능을 지원 하고 있습니다.
즉 Aurora DB Cluster 는 Read Replica Failover 를 사용하기 때문 입니다. 여러개의 Read Replica(읽기 복제본) 이 클러스터로 묶여 있고 접속 가능한 읽기 전용의 단일 Endpoint 주소가 제공되며 문제가 발생시 Read Replica 중 하나를 기본 DB 인스턴스(쓰기노드,마스터노드) 로 자동 승격 시키는 절차로 진행되게 됩니다.
그래서 Aurora DB는 DB 인스턴스에 대한 Multi AZ는 지원 또는 구성되지 않지만 스토리지는 AZ별 2개 그리고 3개의 AZ 를 통해 총 6개의 복제본이 존재하고 있기 때문에 Storage의 Multi AZ 를 사용하고 있다고 생각 하면 될 것 같습니다.
아래 Amazon RDS 다중 AZ 배포 글에서도 명확하게 Amazon Aurora는 읽기 복제본을 사용한다고 표현되어 있습니다.
각 AZ는 물리적으로 분리된 자체 독립 인프라에서 실행되며 높은 안정성을 제공하도록 설계되었습니다. 인프라 장애가 발생하더라도 Amazon RDS가 예비 인스턴스(또는 Amazon Aurora의 경우 읽기 전용 복제본)로 자동 장애 조치를 수행하여 장애 조치 완료 후 데이터베이스 작업을 바로 재개할 수 있습니다
4. Aurora 스토리지
4-1 스토리지 개요
SSD 를 사용하여 구성되어 있으며 가상 볼륨인 클러스터 볼륨에 데이터 등이 저장됩니다. 
클러스터 볼륨은 동일한 AWS 리전에 속한 3개의 AZ(가용 영역) 에 데이터 사본으로 구성되어 있으며 1개의 AZ 마다 2개의 복제본으로 구성하여 총 6개로 구성하여 Failure 에 대비하고 있습니다. 10GB 단위로 스토리지 노드 그룹이 자동 증가 하며 최대 128TiB 까지 증가 할 수 있습니다.
4-2 볼륨에 포함된 항목
Aurora 클러스터 볼륨에는 모든 사용자 데이터, 스키마 객체, 내부 메타데이터(예: 시스템 테이블 및 binlog 등) 가 포함 되어있습니다.
데이터 클러스터 와 DB 인스터스가 독립적으로 구성되게 만들어져있습니다. 이렇게 DB 인스턴스 와 스토리지 노드 분리되어 있고 공유 스토리지 기술 등을 이용하여 읽기 복제본을 사용을 하게 됩니다
Aurora 공유 스토리지를 통해 읽기 복제본(Read Replica) 과 복제 및 동기화가 이루어짐에 따라 Aurora 읽기 복제본 인스턴스를 추가 시 별도의 복제 복사본이 만들지 않고 빠르게 인스턴스를 추가 할수 있습니다.
그 대신 DB 인스턴스의 모든 데이터가(메타데이터 포함) 공유 스토리지 볼륨에 연결(포함) 되어 있습니다 그래서 복제 대상의 Filter 없이 모든 데이터 및 변경 사항(유저 생성과 같은 메타데이터 변경 포함) 모두가 모든 스토리지에 같이 복제/반영 되게 됩니다.
4-3 Aurora의 I/O 구조
Amazon Aurora 는 공유 스토리지 와 공유 볼륨 파일시스템을 이용하며 MySQL 의 binlog 기반의 Replication 과 달리 Storage 와 Cache의 복제가 수행되게 됩니다.
[RDS MySQL]

[RDS Aurora DB Cluster]
이 부분 기존의 RDS MySQL 과 큰 차이라고 볼 수 있으며 먼저 위쪽의 RDS MySQL 그림을 통해 확인 되는 복제 및 IO 처리는 다음과 같습니다.
MySQL 의 경우 Primary Instance(Master 인스턴스) 에서 쓰기 가 발생될 경우 자신의 EBS 스토리지 볼륨에 기록을 하게 되고 그다음 3번 단계를 통해 Binlog 가 전송 되며 Replica Instance 에서는 Master 로 부터 전송 받은 변경 데이터에 대해서 반영하여 자신의 EBS 볼륨에 기록 하게 됩니다. 이와 같은 수행 과정에서 별도로 장애 극복을 위해 EBS Mirror 에도 복제를 하게 됩니다.
Aurora DB Cluster 의 경우 Replica 보내는 데이터는 frm 파일과 Redo Log 입니다. 그렇기 때문에 네트워크 bandwidth 사용도 적으며 무엇보다 빠르게 변경분에 대해서 Read Replica 로 전송 및 반영할 수 있게 되는 구조로 되어 있습니다. 그래서 많은 변경량이 요구 되는 MySQL의 경우 Aurora Cluster 를 사용하면 적은 Replication Lag 또는 거의 없는 상태에서 사용 할 수 있게 됩니다.
조금 더 간단한 이미지로 확인 해본다면 아래의 그림을 참조하시면 될것 같습니다.
• MySQL 읽기 확장
복제는 반드시 로그 재생이 필요
복제는 마스터에 추가적인 부하를 발생
복제 지연의 증가 요소 있음
페일오버 시 데이터 정합성 보장 또는 유실의 가능성이 있음
• Aurora 읽기 확장
로그 재생이 없음
마스터에 부하 최소
~100ms 수준의 복제 지연
동일 스토리지를 공유하여 페일오버
5. 내결함성(Fault Tolerance)
아래 다이어그램은 3개의 AZ에 데이터가 저장된 모습을 보여주고 있습니다. 이러한 구성은 AWS 에서 99.999.....% 의 내구성을 제공하기 위한 복제 데이터 구성입니다.
이러한 설계는Amazon Aurora가 클라이언트 애플리케이션에 대한 가용성 영향 없이 계속 사용할 수 있도록 구성되어 있으며 아래 이미 이미지와 같이 전체 AZ 또는 2개의 스토리지 노드에 대한 손실을 견딜수 있습니다.
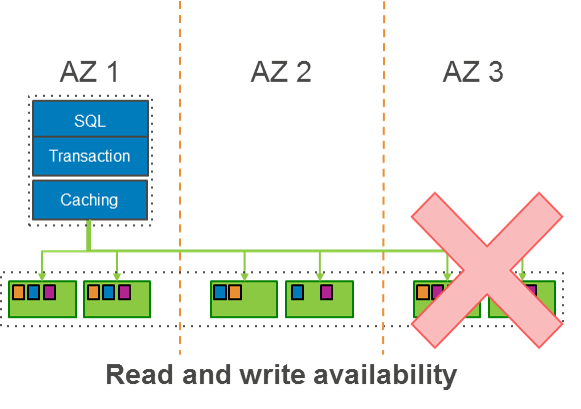
또한 복구 과정에서 Aurora는 데이터 손실없이 보호 그룹에 있는 AZ 와 또 다른 스토리지 노드의 손실을 견딜 수 있도록 설계 되었습니다. 보호 그룹(PG, Protection Group) 에 있는 4개 스토리지 노드가 가용할 경우에만 Aurora 에서 쓰기를 지속할 수 있습니다.
Amazon Aurora 에서 데이터를 쓰게 되면 6개의 스토리지 노드로 병렬로 전송되게 됩니다. 레코드는 먼저 인-메모리(in-memory) 큐에 들어가게 됩니다. 이 큐에서 로그 레코든는 중복이 제거 되게 됩니다. 그 다음 보관될 레코드는 핫 로그(hot log)에서 디스크에 저장되게 되며 핫 로그에 기록되어 쓰기가 지속되면 스토리지 노드는 데이터 수신을 확인하게 됩니다. 6개 스토리지 노드 중에서 4개 이상이 수신 확인을 하면 쓰기 작업은 성공으로 간주되고 클라이언트에게 완료 답신을 반환하게 됩니다.
Aurora 는 쿼럼 모델을 사용하고 있습니다. 쿼럼 모델 아키텍처에서는 데이터 복사본의 일부를 읽고 쓰게 됩니다. 쿼럼 시스템은 몇가지 장점을 가지고 있으며 장시간 노드에 오류가 있더라도(재부팅 같은 경우) 또는 일시적인 오류의 경우에도 장애 극복과 가용성 측면에서 장점을 가지고 있습니다.
Aurora 에서는 3개의 가용 영역(AZ)에 걸쳐서 스토리지 노드중 4개 쓰기 세트와 3개의 읽기 세트가 있는 6개 복제본 쿼럼을 사용하게 됩니다.
- 6개 중 4개 쓰기 쿼럼
- 6개 중 3개 읽기 쿼럼(recovery)
읽기의 경우 6개 복사본 중 3개가 가용 하다면 읽기가 가능하며 노드 중 하나가 느리게 실행되는 경우라도 다른 노드들이 신속하게 응답하여 처리가 가능하고 느린 노드도 바로 따라잡게 되게 됩니다.

쓰기 작업시 6개 중 3개가 문제가 발생 되었을 경우 해당 3개만 존재하는 해당 블럭만 쓰기가 불가능(실패) 하게 됩니다.
6. Aurora Version
Amazon Aurora DB 는 MySQL 과 PostgreSQL 과 호환되는 완전 관리형 데이터베이스 엔진 입니다 다만 호환되는 별도의 데이터베이스 엔진임으로 MySQL 과 PostgreSQL 과 버전이 완전하게 동일 하지는 않으며 별도의 Aurora Version 이 관리되고 있습니다.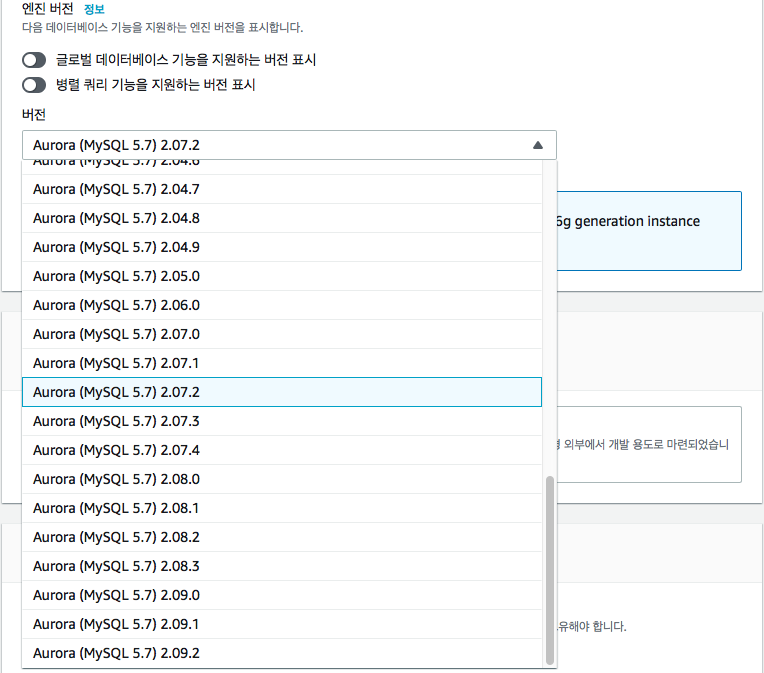
포스팅 시점에서는 MySQL 기준으로 MySQL5.6 과 5.7 버전과 호환되는 Aurora 데이터베이스 엔진을 제공되고 있습니다.
[추가] MySQL 8.0 버전과 호환을 가지는 Aurora MySQL 3.0 버전이 릴리즈 되었습니다. 관련 정보는 아래 포스팅에서 확인 하시면 됩니다.

Aurora 버전 체계는 <Major Version>.<Minor version>.<Patch version> 형식을 사용 하며 mysql client 나 workbench 등으로 접속하여 aurora_version 시스템 변수를 통해서 Aurora 버전을 확인 할 수 있습니다.
mysql> select aurora_version(); -- 또는 mysql> select @@aurora_version; mysql> select aurora_version(), @@aurora_version; +------------------+------------------+ | aurora_version() | @@aurora_version | +------------------+------------------+ | 2.08.1 | 2.08.1 | +------------------+------------------+
MySQL 5.6, 5.7 커뮤니티 버전과 Aurora MySQL 1.x 및 2.x 에 대해서 버전 간의 일대일 대응(매핑)은 없습니다. (5.7.xx 버전이 Aurora 2.0.x.xx 버전과 매칭과 같은 것이 없음)
[업데이트] Aurora MySQL 2.0 에서 새로운 MySQL Community 버전 5.7.40 버전과 호환되는 Aurora MySQL 2.12 버전이 2023년 7월 25일에 릴리즈 되었습니다.
Amazon Aurora MySQL 릴리즈 버전에 포함된 버그 수정사항이나 새로운 기능은 별도의 Amazon Aurora 데이터베이스 업데이트 문서를 참조해보시면 됩니다.
- Amazon Aurora MySQL 3.0 업데이트[Link]
- Amazon Aurora MySQL 2.0 업데이트[Link]
- Amazon Aurora MySQL 1.0 업데이트[Link]
Aurora MySQL 2.x 엔진 버전과 MySQL Community 5.7.12 및 5.7.40 버전과 호환되며, 5.7.40 버전과 호환되는 Aurora MySQL 2.12 버전은 2023년 7월 25일에 릴리즈 되었습니다.
Aurora MySQL 1.x 엔진 버전과 MySQL Community 5.6.10a 와 호환 되어 있습니다.
Amazon Aurora DB 생성 및 구성 관련하여서 다음 포스팅에서 기술하도록 하겠습니다.
7. Reference
Reference link
aws.amazon.com/CHAP_AuroraOverview[Link]
aws.amazon.com/databaseintroducing-the-aurora-storage[Link]
aws.amazon.com/introducing-the-aurora-storage-engine[Link]
aws.amazon.com/new-parallel-query-for-amazon-aurora[Link]
aws.amazon.com/quorum-reads-and-mutating-state[Link]
aws.amazon.com/quorum-reads-and-mutating-state[Link]
aws.amazon.com/aurora-faq[Link]
aws.amazon.com/mysql-features[Link]
slideshare.net/awskorea/amazon-aurora-deep-dive[Link]
slideshare.net/awskorea/aws-cloud-2017-amazon-aurora[Link]
slideshare.net/awskorea/aws-db-day-auroradeepdive[Link]
slideshare.net/awskorea/amazon-aurora-deep-dive-61569862[Link]
slideshare.net/awskorea/2-amazonaurora-migration-usecase[Link]
이어지는 글
연관된 다른 글




Principal DBA(MySQL, AWS Aurora, Oracle)
핀테크 서비스인 핀다에서 데이터베이스를 운영하고 있어요(at finda.co.kr)
Previous - 당근마켓, 위메프, Oracle Korea ACS / Fedora Kor UserGroup 운영중
Database 외에도 NoSQL , Linux , Python, Cloud, Http/PHP CGI 등에도 관심이 있습니다
purityboy83@gmail.com / admin@hoing.io