









Last Updated on 11월 26, 2022 by Jade(정현호)
안녕하세요 제이드(정현호) 입니다.
이번 포스팅은 오라클 클라우드에서 제공 되는 서비스 중 MDS(MySQL Database Service) 기능 중에 MySQL 을 한층 더 활용할 수 있는 기능인 HeatWave(히트웨이브) 에 대해서 살펴보고 OLAP 성능 테스트인 TPH-C 성능 테스트를 진행 해보려고 합니다.
Contents
MDS Overview
오라클 클라우드 에서 MDS 는 MySQL Database Service 의 약자로 MySQL 데이터베이스의 PaaS형 클라우드 서비스를 의미 합니다.
PaaS 형 Database 서비스를 표현하는 단어 중 많이 사용 되는 용어로 완전 관리형 이라는 표현이 여러 클라우드사에서 공통적으로 사용되며 그 단어의 의미대로 클라우드 서비스사가 데이터베이스에 대한 모든 관리를 해주는 서비스 형 데이터베이스를 의미 합니다.

오라클 클라우드의 MySQL Database Service는 MySQL 팀에서 100% 개발, 관리 및 지원하며 패치, 업그레이드, 백업과 같이 시간이 많이 걸리는 작업을 자동화 하거나 손쉽게 이루어질 수 있는 서비스를 제공 하며, Enterprise Edition 로 제공되고 있습니다.
Oracle Gen 2 Cloud 기반으로 새로 개편된 MDS 서비스가 2020년 12월 3일 런칭 되었으며 런칭 되면서 애널리틱스 엔진인 HeatWave 기능을 포함하여 출시 하였습니다. HeatWave 는 OLAP 등의 분석 쿼리에 적합한 엔진으로 별도의 ETL 등의 작업과 변경없이 사용하는 MDS 에서 HeatWave 를 통하여 OLAP 성 처리를 빠르게 수행 할 수 있다는 장점을 가지고 있습니다.
HeatWave Overview
HeatWave는 분석 워크로드, 혼합 워크로드 및 머신 러닝을 위해 MySQL 성능을 몇 배나 가속화하는 대규모 병렬 고성능 인메모리 쿼리 가속기입니다.
HeatWave 클러스터는 MySQL DB 시스템과 HeatWave 노드로 구성됩니다.
MySQL DB 시스템에는 클러스터 관리, 쿼리 스케줄링 및 쿼리 결과를 MySQL DB 시스템으로 반환하는 역할을 하는 HeatWave 플러그인이 포함되어 있습니다. HeatWave 노드는 메모리에 데이터를 저장하고 분석 및 기계 학습 쿼리를 처리합니다. 각 HeatWave 클러스터 노드는 HeatWave 쿼리 처리 엔진(스토리지 엔진 : RAPID)의 인스턴스를 호스팅 합니다.
HeatWave 클러스터를 활성화 하게 되면, 가속화 처리를 위해 특정 전제 조건을 충족하는 분석 쿼리가(analytics queries)가 MySQL DB 시스템에서 HeatWave 클러스터로 자동 오프로드되어 OLTP(온라인 트랜잭션 처리), OLAP(온라인 분석 처리) 및 혼합 워크로드(mixed workloads)를 같이 실행할 수 있습니다.
이 과정은 쿼리에서 참조하는 모든 연산자와 기능이 HeatWave 에서 지원 되는지 여부와 HeatWave 엔진으로 쿼리를 처리하는 데 예상되는 시간이 MySQL 엔진보다 짧은 경우일 경우에 HeatWave 에서 수행을 기반으로 합니다. 두 조건이 모두 충족되면 쿼리가 처리를 위해 HeatWave 클러스터 노드로 Query Pushdown 을 하게 됩니다.

[Integration for Query Processing- HeatWave White Paper]
처리가 완료되면 결과가 MySQL 데이터베이스 노드로 다시 전송되어 사용자에게 반환됩니다.
HeatWave 에서 이와 같은 가속화 처리를 수행하기 위해서는 별도의 ETL(추출, 전송 및 로드)을 요구하지 않고 애플리케이션을 수정하지 않고도 동일한 MySQL 데이터베이스에서 HeatWave의 분석 기능을 사용할 수 있다는 것이 특장점 입니다.
또한 HeatWave 클러스터를 활성화하면 MySQL에 저장된 데이터를 위한 완전 관리형와 높은 확장성(highly scalable) , 효율적인 비용의 머신 러닝 솔루션인 HeatWave Machine Learning (ML)에 대한 액세스도 제공됩니다.
HeatWave ML은 초보자와 숙련된 ML 실무자가 모두 사용할 수 있는 예측 기계 학습 모델을 훈련하고 사용하기 위한 간단한 SQL 인터페이스를 제공합니다. 머신 런닝을 위한 전문 지식 과 전문적인 도구 및 알고리즘은 필요하지 않습니다. HeatWave ML을 사용하면 SQL 루틴에 대한 단일 호출로 모델을 훈련할 수 있습니다. 마찬가지로 애플리케이션과 쉽게 통합할 수 있는 단일 CALL 또는 SELECT 문으로 예측을 생성할 수 있습니다.

분석 및 머신 런닝 쿼리는 MySQL DB 시스템에 연결하여 HeatWave 클러스터와 상호 작용하는 MySQL 클라이언트 또는 애플리케이션에서 실행 되며, 결과는 MySQL DB 시스템과 쿼리를 실행한 MySQL 클라이언트 또는 애플리케이션으로 반환됩니다.
정리하면 위의 아키텍처 이미지에서 확인할 수 있듯이 크게 3부분 으로 나누어서 볼 수 있을 것 같습니다.
- MySQL DB System : MDS 에 HeatWave 가 플러그인으로 구성 및 활성화를 하게 되며, Analytics 나 ML Query 가 인입이 되면 HeatWave는 인메모리 처리 엔진이기 때문에 데이터는 MySQL InnoDB 스토리지 엔진에 유지 되며 HeatWave 플러그인을 통해서 처리가 HeatWave 로 클러스터 전달(오프로드 offloaded) 됩니다.
- HeatWave Cluster : OLTP(온라인 트랜잭션 처리), OLAP(온라인 분석 처리) 및 혼합 워크로드를 처리 합니다.

- [HeatWave scale-out storage layer - HeatWave White Paper]
- HeatWave Storage Layer : HeatWave로 데이터를 로드하려면 데이터를 HeatWave 컬럼 형식으로 변환해야 하며, 서비스 가동 시간을 개선하기 위해 HeatWave는 OCI Object Storage에 구축된 새로운 스토리지 계층을 도입 하였고 데이터 크기에 관계없이 일정한 시간에 데이터를 다시 로드 할 수 있습니다.
필요한 HeatWave 노드의 수는 데이터 크기와 HeatWave 클러스터에 데이터를 로드할 때 달성되는 압축량에 따라 달라지게 되며, HeatWave 클러스터는 최대 64개의 노드를 지원합니다.
Massively Parallel Architecture
HeatWave의 대규모 병렬 아키텍처(Massively Parallel Architecture)는 데이터의 노드 간 및 노드 내 분할을 통해 가능합니다.
HeatWave 클러스터 내의 각 노드와 노드 내의 각 CPU 코어는 분할된 데이터를 병렬로 처리합니다.

[HeatWave Massively Parallel Architecture]
HeatWave는 수천 개의 코어로 확장할 수 있습니다. 높은 팬아웃(high-fanout), 워크로드 인식 파티셔닝과 결합된 이 대규모 병렬 아키텍처는 쿼리 처리를 가속화합니다.
Push-Based Vectorized Query Processing
HeatWave 는 한 연산자에서 다른 연산자로 쿼리 실행 계획을 통해 vector blocks(slices of columnar data)을 푸시하여 쿼리를 처리합니다. HeatWave는 우수한 쿼리 성능을 이끌기 위해서 벡터화된(vectorized ) 처리를 용이하게 하는 컬럼형 인메모리 표현을 사용합니다.

[Vectorized in-memory columnar representation for analytic processing]
데이터는 메모리에 로드 되기 전에 인코딩되고 압축됩니다. 이 압축 및 최적화된 메모리 표현은 숫자 및 문자열 데이터 모두에 사용됩니다.
그 결과 메모리 사용량이 크게 줄어들어 비용이 절감됩니다. 메모리 및 쿼리 처리의 데이터 구성은 vector 및 SIMD 처리에 적합하도록 구성되어 쿼리에 대한 해석 오버헤드를 줄이고 쿼리 성능을 향상 시킵니다.
TPC-H
TPC-H 는 OLAP 벤치마크로 분류 되며 TPC-H 는 의사결정 지원(decision support) 벤치마크 입니다. 이 벤치마크는 대량의 데이터를 검사하고 고도로 복잡한 쿼리를 실행하며 중요한 비즈니스 의사 결정 지원 시스템에 대한 벤치마크 테스트를 실시합니다.
의사결정(decision)을 지원하기 위한 벤치마크 성능 평가 기준 이라고 할 수 있습니다.
MySQL HeatWave 는 OLAP 또는 BI 쿼리 이나 ML 처리에 특화되어 있기 때문에 OLAP 형태로 벤치마크를 진행을 하기 위해서 TPC-H tool 설치 및 TPC-H 를 이용해서 데이터를 생성 하도록 하겠습니다.
[참고] TPC-C(Transaction Processing Performance Council Benchmark C)는 OLTP( 온라인 트랜잭션 처리 ) 시스템 의 성능을 비교하는 데 사용되는 벤치마크 입니다.
TPC tool 은 아래 링크에서 다운로드 받을수 있으며 TPC-H 이외 C 를 비롯하여 여러 측정 항목에 대해서 제공하고 있습니다..
다운로드 페이지에서 아래의 이미지와 같이 TPC-H 의 다운로드 링크를 클릭 합니다. 버전은 계속 업데이트 됨으로 다운로드 받는 시점에 따라 달라지게 됩니다.

위에서 다운로드 링크를 클릭하면 아래의 이미지와 같이 몇 가지 정보를 입력하는 폼을 볼 수 있으며 *(별표) 가 된 항목에 정보를 기입 후 하단의 다운로드 버튼을 클릭하면 아래 폼에 입력한 이메일(Email) 로 다운로드 링크가 수신 됩니다.

수신된 이메일의 링크를 통해서 파일을 다운로드 받으시면 됩니다.

[참고] 포스팅에서 사용한 버전 및 Class 정보
- TPC-H 버전은 3.0.1
- Bastion Host OS : Oracle Linux 8.6(Oracle Cloud)
- MySQL(Oracle Cloud) 8.0.30-u1-cloud
- MySQL.HeatWave.VM.Standard.E3 타입의 사양은 CPU 16코어, 메모리 512GB
- AWS - 8.0.mysql_aurora.3.02.0
- db.r5.4xlarge , db.r5.8xlarge
AWS Aurora 는 db.r5.4xlarge 와 db.r5.8xlarge 로 Benchmark 테스트를 하였으나 2개의 차이가 미묘하여 결과에서는 1개로 표현하였습니다.
설치
TPC-H 설치를 진행하도록 하겠습니다.
• 압축 해제 및 makefile 템플릿 복사
]$ mkdir pkg ]$ mv TPC-H_Tools_v3.0.1.zip pkg ]$ cd pkg ]$ unzip TPC-H_Tools_v3.0.1.zip ]$ cd 'TPC-H V3.0.1'/dbgen ]$ cp makefile.suite makefile
• makefile 설정 변경
위에서 복사하여 생성한 makefile 을 vi 등의 편집기를 통해서 아래와 같이 내용을 수정/추가 합니다.
]$ vi makefile CC = gcc DATABASE= ORACLE MACHINE = LINUX WORKLOAD = TPCH
• make 를 통해서 빌드 수행
]$ make
• 1GB 데이터 파일 세트를 생성
dbgen 명령을 실행하여 tpch 데이터베이스에 대한 1GB 데이터 파일 세트를 생성 합니다.
]$ ./dbgen -s 1
완료 되었다면 tpch 데이터베이스에 입력할 테이블에 대한 각각의 데이터 파일이 생성 되며 아래와 같이 확인 할 수 있습니다.
]$ ls -l *.tbl 24346144 customer.tbl 759863287 lineitem.tbl 2224 nation.tbl 171952161 orders.tbl 24135125 part.tbl 118984616 partsupp.tbl 389 region.tbl 1409184 supplier.tbl
TPC-H 로 생성된 데이터의 경우 insert 구문이 아닌 RAW 또는 | 로 구분된 CSV 형태의 파일 입니다.
]$ more region.tbl 0|AFRICA|lar deposits. .... are according to | 1|AMERICA|hs use ironic, even requests. s| <... 중략 ...> * 가로 길이에 의해서 위의 내용은 편집 되었습니다.
데이터 로드를 위해서 포스팅에서는 MySQL Shell 을 사용하였고, 사용 편의상 MySQL Shell 을 사용하시는것이 좋을 것으로 생각 됩니다. MySQL Shell 에 대한 설치나 추가적인 내용은 아래의 이전 포스팅을 확인 하시면 됩니다.

HeatWave 구성 및 데이터 로드
Oracle Cloud 에 MDS(MySQL Database Service) 인스턴스 생성 과정은 구획(Compartment) 생성, VPC 생성, 정책 추가 등의 사전 작업 이후에 MDS HeatWave 생성을 진행 하시면 되며 해당 과정에 대해서는 아래 내용을 참조하시면 됩니다.

HeatWave 인스턴스 생성
MDS 인스턴스 생성시 필요한 사전 구성 설정은 완료 되어 있는 상태이며, 이제 HeatWave 인스턴스를 생성을 진행하도록 하겠습니다.
먼저 구획 선택과 인스터스 이름을 지정합니다. 포스팅에서는 인스턴스 이름을 "mds-heatwave-test-01" 으로 지정하였습니다
그리고 MDS 인스턴스 생성시 아래와 같이 HeatWave 타입을 선택을 해야 합니다.
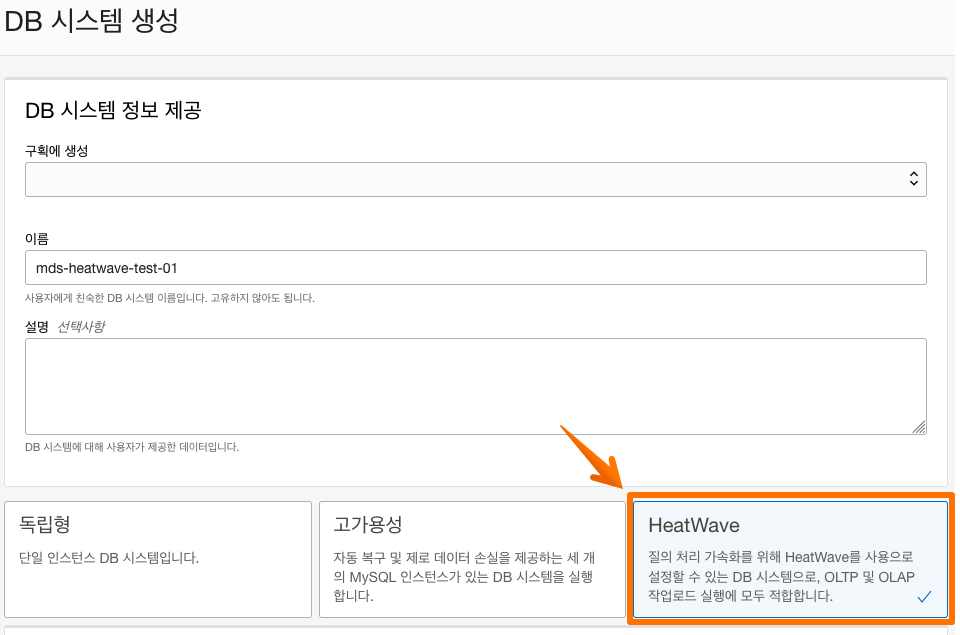
사용한 인스턴스 타입은 VM.Standard.E3 이며 , MySQL 버전은 8.0.30 으로 진행 하였습니다.

MySQL.HeatWave.VM.Standard.E3 타입의 사양은 CPU 16코어, 메모리 512GB 입니다.
[참고] Endpoint 관련
MDS 인스턴스 생성시 고급 옵션 - 네트워킹 - 호스트 이름 에서 호스트명을 지정하지 않으면 EndPoint 정보가 생성되지 않습니다.
그래서 MDS 인스턴스 생성시에는 호스트 이름을 기재하여 Endpoint 도 같이 생성하는 것을 권장 드립니다.

인스턴스 생성이 완료 되었다면 웹 콘솔에서 인스턴스의 정보를 확인해 보면 아래 이미지와 같이 HeatWave 클러스터 항목이 아직 "사용 안함" 으로 되어 있는 것을 확인 할 수 있습니다.
생성이 완료 되었다고 해서 바로 HeatWave 기능이 활성화 되는 것은 아닙니다. 아래 이미지와 같이 클러스터가 "사용 안함" 으로 클러스터가 추가 된 상태는 아닙니다.

또한 사용 가능한 엔진의 목록에서도 아직 RAPID 엔진이 목록에서 확인 되지 않습니다.
mysql> show engines; +--------------------+---------+--------------+------+------------+ | Engine | Support | Transactions | XA | Savepoints | +--------------------+---------+--------------+------+------------+ | FEDERATED | NO | NULL | NULL | NULL | | MEMORY | YES | NO | NO | NO | | InnoDB | DEFAULT | YES | YES | YES | | PERFORMANCE_SCHEMA | YES | NO | NO | NO | | MyISAM | YES | NO | NO | NO | | MRG_MYISAM | YES | NO | NO | NO | | BLACKHOLE | YES | NO | NO | NO | | CSV | YES | NO | NO | NO | | ARCHIVE | YES | NO | NO | NO | +--------------------+---------+--------------+------+------------+ * 가로 길이에 따라서 Comment 컬럼은 편집하였습니다.
테이블 생성 및 데이터 로드
HeatWave 클러스터 활성화 이전에 먼저 데이터를 로드 하도록 하겠습니다. 진행 순서상 인스턴스 와 HeatWave 사용(구성) 후에 데이터를 로드 하는 순서로 진행 하여도 됩니다.
테이블을 위한 데이터베이스 생성 과 테이블 생성 그리고 데이터를 로드 하도록 하겠습니다.
• 데이터베이스 생성 및 테이블 생성
CREATE DATABASE tpch character set utf8mb4;
USE tpch;
CREATE TABLE nation ( N_NATIONKEY INTEGER primary key,
N_NAME CHAR(25) NOT NULL,
N_REGIONKEY INTEGER NOT NULL,
N_COMMENT VARCHAR(152));
CREATE TABLE region ( R_REGIONKEY INTEGER primary key,
R_NAME CHAR(25) NOT NULL,
R_COMMENT VARCHAR(152));
CREATE TABLE part ( P_PARTKEY INTEGER primary key,
P_NAME VARCHAR(55) NOT NULL,
P_MFGR CHAR(25) NOT NULL,
P_BRAND CHAR(10) NOT NULL,
P_TYPE VARCHAR(25) NOT NULL,
P_SIZE INTEGER NOT NULL,
P_CONTAINER CHAR(10) NOT NULL,
P_RETAILPRICE DECIMAL(15,2) NOT NULL,
P_COMMENT VARCHAR(23) NOT NULL );
CREATE TABLE supplier ( S_SUPPKEY INTEGER primary key,
S_NAME CHAR(25) NOT NULL,
S_ADDRESS VARCHAR(40) NOT NULL,
S_NATIONKEY INTEGER NOT NULL,
S_PHONE CHAR(15) NOT NULL,
S_ACCTBAL DECIMAL(15,2) NOT NULL,
S_COMMENT VARCHAR(101) NOT NULL);
CREATE TABLE partsupp ( PS_PARTKEY INTEGER NOT NULL,
PS_SUPPKEY INTEGER NOT NULL,
PS_AVAILQTY INTEGER NOT NULL,
PS_SUPPLYCOST DECIMAL(15,2) NOT NULL,
PS_COMMENT VARCHAR(199) NOT NULL, primary key (ps_partkey, ps_suppkey) );
CREATE TABLE customer ( C_CUSTKEY INTEGER primary key,
C_NAME VARCHAR(25) NOT NULL,
C_ADDRESS VARCHAR(40) NOT NULL,
C_NATIONKEY INTEGER NOT NULL,
C_PHONE CHAR(15) NOT NULL,
C_ACCTBAL DECIMAL(15,2) NOT NULL,
C_MKTSEGMENT CHAR(10) NOT NULL,
C_COMMENT VARCHAR(117) NOT NULL);
CREATE TABLE orders ( O_ORDERKEY INTEGER primary key,
O_CUSTKEY INTEGER NOT NULL,
O_ORDERSTATUS CHAR(1) NOT NULL,
O_TOTALPRICE DECIMAL(15,2) NOT NULL,
O_ORDERDATE DATE NOT NULL,
O_ORDERPRIORITY CHAR(15) NOT NULL,
O_CLERK CHAR(15) NOT NULL,
O_SHIPPRIORITY INTEGER NOT NULL,
O_COMMENT VARCHAR(79) NOT NULL);
CREATE TABLE lineitem ( L_ORDERKEY INTEGER NOT NULL,
L_PARTKEY INTEGER NOT NULL,
L_SUPPKEY INTEGER NOT NULL,
L_LINENUMBER INTEGER NOT NULL,
L_QUANTITY DECIMAL(15,2) NOT NULL,
L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL,
L_DISCOUNT DECIMAL(15,2) NOT NULL,
L_TAX DECIMAL(15,2) NOT NULL,
L_RETURNFLAG CHAR(1) NOT NULL,
L_LINESTATUS CHAR(1) NOT NULL,
L_SHIPDATE DATE NOT NULL,
L_COMMITDATE DATE NOT NULL,
L_RECEIPTDATE DATE NOT NULL,
L_SHIPINSTRUCT CHAR(25) NOT NULL,
L_SHIPMODE CHAR(10) NOT NULL,
L_COMMENT VARCHAR(44) NOT NULL,
primary key(L_ORDERKEY,L_LINENUMBER));
• 테이블 생성 확인
mysql> SHOW TABLES; +----------------+ | Tables_in_tpch | +----------------+ | customer | | lineitem | | nation | | orders | | part | | partsupp | | region | | supplier | +----------------+
이전 단계에서 TPC-H Tool 을 통해 생성한 데이터를 로드 하도록 하겠습니다.
• MySQL Shell 통한 접속
]$ mysqlsh ID@DB주소 --database tpch --mysql MySQL Shell Copyright (c) 2016, 2022, Oracle and/or its affiliates. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type '\help' or '\?' for help; '\quit' to exit. Creating a Classic session to '' Fetching schema names for autocompletion... Press ^C to stop. Your MySQL connection id is 210 (X protocol) Server version: 8.0.30-u1-cloud MySQL Enterprise - Cloud Default schema `tpch` accessible through db. MySQL JS >
util.importTable 를 수행하기 위해서는 Classic Potocol(3306) 으로 접속해야 합니다.(옵션 : --mysql)
• 데이터 로딩
MySQL Shell 의 JavaScript Mode(\js) 에서 util.importTable() 를 이용해서 병렬 처리로 진행하였고 병렬 쓰레드 수는 사용하는 서버의 CPU 나 쓰레드에 따라서 설정 하시면 됩니다.
그리고 입력하는 데이터 필드는 "|" 파이프 캐릭터로 종료 됨에 따라서 아래와 같이 진행 하였습니다.
MySQL JS > util.importTable("customer.tbl",{table: "customer", fieldsTerminatedBy:"|", bytesPerChunk:"100M", threads:16})
MySQL JS > util.importTable("lineitem.tbl",{table: "lineitem", fieldsTerminatedBy:"|", bytesPerChunk:"100M", threads:16})
MySQL JS > util.importTable("nation.tbl",{table: "nation", fieldsTerminatedBy:"|", bytesPerChunk:"100M", threads:16})
MySQL JS > util.importTable("orders.tbl",{table: "orders", fieldsTerminatedBy:"|", bytesPerChunk:"100M", threads:16})
MySQL JS > util.importTable("part.tbl",{table: "part", fieldsTerminatedBy:"|", bytesPerChunk:"100M", threads:16})
MySQL JS > util.importTable("partsupp.tbl",{table: "partsupp", fieldsTerminatedBy:"|", bytesPerChunk:"100M", threads:16})
MySQL JS > util.importTable("region.tbl",{table: "region", fieldsTerminatedBy:"|", bytesPerChunk:"100M", threads:16})
MySQL JS > util.importTable("supplier.tbl",{table: "supplier", fieldsTerminatedBy:"|" , bytesPerChunk:"100M", threads:16})
클러스터 추가
데이터 로드가 완료 되었다면 그다음으로 HeatWave 를 사용하기 위해서 아래 이미지와 같이 HeatWave 클러스터 항목에서 "사용" 링크를 클릭 합니다.

최소 1개, 최대 64개 노드까지 지원 하고, 원하는 노드수를 지정할 수 있으며, 분석에 사용될 용량을 측정하여 노드 수를 예측하는 기능도 사용할 수 있습니다.

화면에서 "예측 노드수" 를 선택하면 아래와 같이 팝업 윈도우를 확인할 수 있으며, "예측 생성" 버튼을 클릭해서 계속 진행을 합니다.

예측 노드 수 계산이 되면 아래와 같이 현재 데이터베이스의 사이즈 대비 하여 필요한 클러스터 노드의 수 정보를 확인 할 수 있습니다.

노드 수를 입력 후 하단에 "HeatWave 클러스터 추가" 버튼을 클릭 하여 HeatWave 생성을 시작 합니다.

생성이 완료 되면 아래 이미지와 같이 클러스터 상태가 "활성" 으로 확인 되며, 지정한 노드 수와 용량을 확인 할 수 있습니다.

MySQL 에 접속하여 플러그인 된 ENGINE 정보를 조회 하였을 때도 새로운 RAPID 엔진이 추가 된 것을 확인 할 수 있습니다.
mysql> SHOW ENGINES; +--------------------+---------+--------------+------+------------+ | Engine | Support | Transactions | XA | Savepoints | +--------------------+---------+--------------+------+------------+ | FEDERATED | NO | NULL | NULL | NULL | | MEMORY | YES | NO | NO | NO | | InnoDB | DEFAULT | YES | YES | YES | | PERFORMANCE_SCHEMA | YES | NO | NO | NO | | RAPID | YES | NO | NO | NO | <-- 추가됨 | MyISAM | YES | NO | NO | NO | | MRG_MYISAM | YES | NO | NO | NO | | BLACKHOLE | YES | NO | NO | NO | | CSV | YES | NO | NO | NO | | ARCHIVE | YES | NO | NO | NO | +--------------------+---------+--------------+------+------------+ * 가로 길이에 따른 Comment 컬럼은 편집하였습니다.
HeatWave에 TPC-H 데이터 로드
MySQL Shell 로 로드한 TPC-H 테이블 데이터에 대해서 HeatWave 로 로드를 진행 합니다.
다음 작업을 실행하여 tpch 데이터베이스 테이블 HeatWave 클러스터에 로드합니다. 수행되는 작업에는 문자열 열 encoding defining , secondary engine 에 대한 정의 , SECONDARY_LOAD 작업 실행이 포함되어 있습니다.
USE tpch; ALTER TABLE nation modify `N_NAME` CHAR(25) NOT NULL COMMENT 'RAPID_COLUMN=ENCODING=SORTED'; ALTER TABLE nation modify `N_COMMENT` VARCHAR(152) COMMENT 'RAPID_COLUMN=ENCODING=SORTED'; ALTER TABLE nation SECONDARY_ENGINE=RAPID; ALTER TABLE nation SECONDARY_LOAD; ALTER TABLE region modify `R_NAME` CHAR(25) NOT NULL COMMENT 'RAPID_COLUMN=ENCODING=SORTED'; ALTER TABLE region modify `R_COMMENT` VARCHAR(152) COMMENT 'RAPID_COLUMN=ENCODING=SORTED'; ALTER TABLE region SECONDARY_ENGINE=RAPID; ALTER TABLE region SECONDARY_LOAD; ALTER TABLE part modify `P_MFGR` CHAR(25) NOT NULL COMMENT 'RAPID_COLUMN=ENCODING=SORTED'; ALTER TABLE part modify `P_BRAND` CHAR(10) NOT NULL COMMENT 'RAPID_COLUMN=ENCODING=SORTED'; ALTER TABLE part modify `P_CONTAINER` CHAR(10) NOT NULL COMMENT 'RAPID_COLUMN=ENCODING=SORTED'; ALTER TABLE part modify `P_COMMENT` VARCHAR(23) NOT NULL COMMENT 'RAPID_COLUMN=ENCODING=SORTED'; ALTER TABLE part SECONDARY_ENGINE=RAPID; ALTER TABLE part SECONDARY_LOAD; ALTER TABLE supplier modify `S_NAME` CHAR(25) NOT NULL COMMENT 'RAPID_COLUMN=ENCODING=SORTED'; ALTER TABLE supplier modify `S_ADDRESS` VARCHAR(40) NOT NULL COMMENT 'RAPID_COLUMN=ENCODING=SORTED'; ALTER TABLE supplier modify `S_PHONE` CHAR(15) NOT NULL COMMENT 'RAPID_COLUMN=ENCODING=SORTED'; ALTER TABLE supplier SECONDARY_ENGINE=RAPID; ALTER TABLE supplier SECONDARY_LOAD; ALTER TABLE partsupp modify `PS_COMMENT` VARCHAR(199) NOT NULL COMMENT 'RAPID_COLUMN=ENCODING=SORTED'; ALTER TABLE partsupp SECONDARY_ENGINE=RAPID; ALTER TABLE partsupp SECONDARY_LOAD; ALTER TABLE customer modify `C_NAME` VARCHAR(25) NOT NULL COMMENT 'RAPID_COLUMN=ENCODING=SORTED'; ALTER TABLE customer modify `C_ADDRESS` VARCHAR(40) NOT NULL COMMENT 'RAPID_COLUMN=ENCODING=SORTED'; ALTER TABLE customer modify `C_MKTSEGMENT` CHAR(10) NOT NULL COMMENT 'RAPID_COLUMN=ENCODING=SORTED'; ALTER TABLE customer modify `C_COMMENT` VARCHAR(117) NOT NULL COMMENT 'RAPID_COLUMN=ENCODING=SORTED'; ALTER TABLE customer SECONDARY_ENGINE=RAPID; ALTER TABLE customer SECONDARY_LOAD; ALTER TABLE orders modify `O_ORDERSTATUS` CHAR(1) NOT NULL COMMENT 'RAPID_COLUMN=ENCODING=SORTED'; ALTER TABLE orders modify `O_ORDERPRIORITY` CHAR(15) NOT NULL COMMENT 'RAPID_COLUMN=ENCODING=SORTED'; ALTER TABLE orders modify `O_CLERK` CHAR(15) NOT NULL COMMENT 'RAPID_COLUMN=ENCODING=SORTED'; ALTER TABLE orders SECONDARY_ENGINE=RAPID; ALTER TABLE orders SECONDARY_LOAD; ALTER TABLE lineitem modify `L_RETURNFLAG` CHAR(1) NOT NULL COMMENT 'RAPID_COLUMN=ENCODING=SORTED'; ALTER TABLE lineitem modify `L_LINESTATUS` CHAR(1) NOT NULL COMMENT 'RAPID_COLUMN=ENCODING=SORTED'; ALTER TABLE lineitem modify `L_SHIPINSTRUCT` CHAR(25) NOT NULL COMMENT 'RAPID_COLUMN=ENCODING=SORTED'; ALTER TABLE lineitem modify `L_SHIPMODE` CHAR(10) NOT NULL COMMENT 'RAPID_COLUMN=ENCODING=SORTED'; ALTER TABLE lineitem modify `L_COMMENT` VARCHAR(44) NOT NULL COMMENT 'RAPID_COLUMN=ENCODING=SORTED'; ALTER TABLE lineitem SECONDARY_ENGINE=RAPID; ALTER TABLE lineitem SECONDARY_LOAD;
* MySQL Shell 에서 실행시 sql mode 에서 실행 합니다.( \sql)
• ALTER TABLE 테이블명 SECONDARY_ENGINE = RAPID : 테이블에서 HeatWave 사용을 설정(정의)
• ALTER TABLE 테이블명 SECONDARY_LOAD : InnoDB 에 저장 테이블 데이터를 HeatWave Storage Layer 로 적재
참고로 약 900MB 가까이 되는 테이블이 InnoDB 에서 HeatWave Storage Layer 로 적재(SECONDARY_LOAD)되는데 약 25초 가량 소요 되었습니다.
HeatWave 클러스터에 로드가 정상적으로 되었는지 모니터링 하기 위해서는 performance_schema 의 rpd_tables , rpd_table_id 테이블을 통해서 확인 할 수 있습니다.
SQL> SELECT NAME, LOAD_STATUS FROM performance_schema.rpd_tables JOIN performance_schema.rpd_table_id ON rpd_tables.ID = rpd_table_id.ID; +---------------+---------------------+ | NAME | LOAD_STATUS | +---------------+---------------------+ | tpch.supplier | AVAIL_RPDGSTABSTATE | | tpch.partsupp | AVAIL_RPDGSTABSTATE | | tpch.orders | AVAIL_RPDGSTABSTATE | | tpch.lineitem | AVAIL_RPDGSTABSTATE | | tpch.customer | AVAIL_RPDGSTABSTATE | | tpch.nation | AVAIL_RPDGSTABSTATE | | tpch.region | AVAIL_RPDGSTABSTATE | | tpch.part | AVAIL_RPDGSTABSTATE | +---------------+---------------------+
Benchmark Test
TPC-H Benchmark 로 사용한 쿼리는 TPCH-Q1 , TPCH-Q3 , TPCH-Q9, TPCH-Q18 4개 입니다.
수행 대상 정보로는 HeatWave 활성화, HeatWave 변수 비활성화(기능 미사용) , AWS Aurora 3개 환경에서 수행하여 시간을 비교 하였습니다.
HeatWave 활성화 MDS 에서 쿼리를 수행하기 전에 EXPLAIN 을 통해서 쿼리가 HeatWave 클러스터로 오프로드 할 수 있는지를 확인할 필요가 있습니다.
*********** 1. row **********
id: 1
select_type: SIMPLE
table: lineitem
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 5955825
filtered: 33.33
Extra: Using where; Using secondary engine RAPID
쿼리가 정상적으로 HeatWave 클러스터 오프로드 가능할 경우 Extra 컬럼에서 "Using secondary engine RAPID" 라고 내용을 확인 할 수 있습니다.
HeatWave 사용/미사용 제어
MDS 인스턴스에서 HeatWave 클러스터를 구성 한 다음에는 HeatWave 에 대한 사용 컨트롤(변경)은 세션 레벨에서의 시스템 변수 변경 과 쿼리 레벨에서의 힌트 사용이 있습니다.
• 세션 레벨에서의 시스템 변수 변경
# 활성화 mysql> SET SESSION use_secondary_engine=ON # 비활성화 mysql> SET SESSION use_secondary_engine=OFF;
• SQL 레벨에서 힌트로 제어
# 사용 /*+ set_var(use_secondary_engine=forced) */ # 미사용 /*+ set_var(use_secondary_engine=off) */
다음은 테스트에서 사용한 4개 쿼리에 대한 정보 입니다.
TPCH-Q1: 가격 책정 요약 보고서 쿼리
가격 책정 요약 보고서 쿼리는 지정된 날짜에 배송된 모든 라인 항목에 대한 요약 가격 책정 보고서를 제공합니다. 날짜는 포함된 가장 큰 배송 날짜로부터 60 - 120일 이내입니다. 쿼리는 확장 가격, 할인 확장 가격, 할인 확장 가격 + 세금, 평균 수량, 평균 확장 가격 및 평균 할인에 대한 합계를 나열합니다.
• Query
SELECT
l_returnflag,
l_linestatus,
SUM(l_quantity) AS sum_qty,
SUM(l_extendedprice) AS sum_base_price,
SUM(l_extendedprice * (1 - l_discount)) AS sum_disc_price,
SUM(l_extendedprice * (1 - l_discount) * (1 + l_tax)) AS sum_charge,
AVG(l_quantity) AS avg_qty,
AVG(l_extendedprice) AS avg_price,
AVG(l_discount) AS avg_disc,
COUNT(*) AS count_order
FROM
lineitem
WHERE
l_shipdate <= DATE '1998-12-01' - INTERVAL '90' DAY
GROUP BY l_returnflag , l_linestatus
ORDER BY l_returnflag , l_linestatus;
TPCH-Q3 : 배송 우선 순위 쿼리
배송 우선 순위 쿼리는 주어진 날짜에 배송되지 않은 주문 중 가장 큰 수익을 올린 주문의 배송 우선 순위와 잠재적 수익을 l_extendedprice * (1-l_discount)의 합계로 정의합니다. 주문은 수익의 내림차순으로 나열됩니다.
• Query
SELECT
l_orderkey,
SUM(l_extendedprice * (1 - l_discount)) AS revenue,
o_orderdate,
o_shippriority
FROM
customer,
orders,
lineitem
WHERE
c_mktsegment = 'BUILDING'
AND c_custkey = o_custkey
AND l_orderkey = o_orderkey
AND o_orderdate < DATE '1995-03-15'
AND l_shipdate > DATE '1995-03-15'
GROUP BY l_orderkey , o_orderdate , o_shippriority
ORDER BY revenue DESC , o_orderdate
LIMIT 10;
TPCH-Q9 : 제품 유형 이익 측정 쿼리
제품 유형 이익 측정 쿼리는 이름에 지정된 하위 문자열이 포함되고 해당 국가의 공급업체가 채운 해당 연도에 주문한 모든 부품의 이익을 각 국가 및 연도에 대해 찾습니다. 이익은 지정된 라인의 부품을 설명하는 모든 라인 항목에 대해 [(l_extendedprice*(1-l_discount)) - (ps_supplycost * l_quantity)]의 합계로 정의됩니다.
• Query
SELECT
nation, o_year, SUM(amount) AS sum_profit
FROM
(SELECT
n_name AS nation,
YEAR(o_ORDERdate) AS o_year,
l_extendedprice * (1 - l_discount) - ps_supplycost * l_quantity AS amount
FROM
part
STRAIGHT_JOIN partsupp
STRAIGHT_JOIN lineitem
STRAIGHT_JOIN supplier
STRAIGHT_JOIN orders
STRAIGHT_JOIN nation
WHERE
s_suppkey = l_suppkey
AND ps_suppkey = l_suppkey
AND ps_partkey = l_partkey
AND p_partkey = l_partkey
AND o_ORDERkey = l_ORDERkey
AND s_nationkey = n_nationkey
AND p_name LIKE '%green%') AS profit
GROUP BY nation , o_year
ORDER BY nation , o_year DESC;
TPCH-Q18 : Large Volume Customer
대용량 고객 쿼리는 대량 주문을 한 고객을 기준으로 고객의 순위를 지정합니다. 대량 주문은 총 수량이 일정 수준 이상인 주문으로 정의됩니다.
• Query
SELECT /*+ JOIN_SUFFIX(l, o, c) */
C_NAME,
C_CUSTKEY,
O_ORDERKEY,
O_ORDERDATE,
O_TOTALPRICE,
SUM(L_QUANTITY)
FROM
customer c,
orders o,
lineitem l
WHERE
O_ORDERKEY IN (SELECT
L_ORDERKEY
FROM
lineitem
GROUP BY L_ORDERKEY
HAVING SUM(L_QUANTITY) > 300)
AND C_CUSTKEY = O_CUSTKEY
AND O_ORDERKEY = L_ORDERKEY
GROUP BY C_NAME , C_CUSTKEY , O_ORDERKEY , O_ORDERDATE , O_TOTALPRICE
ORDER BY O_TOTALPRICE DESC , O_ORDERDATE
LIMIT 100;
수행 결과
4개 쿼리에 대한 Benchmark 수행 결과 입니다.(단위 초(sec) 입니다.)
| MDS HeatWave 사용 | MDS HeatWave 미사용(비활성) | AWS Aurora MySQL | |
| TPCH-Q1 | 0.0425 | 10.3615 | 13.18864 |
| TPCH-Q3 | 0.084 | 2.2528 | 2.9919 |
| TPCH-Q9 | 0.1692 | 4.9846 | 6.4436 |
| TPCH-Q18 | 0.0935 | 2.9903 | 4.1203 |

* AWS Aurora 는 db.r5.4xlarge 와 db.r5.8xlarge 2개로 테스트를 하였으나 차이가 미묘하여 결과에서는 1개로 표현하였습니다.
OLAP 성 쿼리를 통한 테스트 결과로써 HeatWave 가 소개된 내용 처럼 보통의 MySQL 인스턴스에 비해 매우 빠른 수행 속도를 확인 할 수 있었습니다. 테스트를 결과없는 다른 쿼리 중에서는 일반 MySQL 에서는 수행시간이 5분이 지나도 결과가 출력되지 않아 비교군에서 제외 하였으나 해당 쿼리의 경우도 HeatWave 에서는 1초 미만의 수행 속도를 보였습니다.
OLAP 성 쿼리에서는 매우 빠른 부분 성능을 직접 확인 한 시간이었으며, 앞으로 AWS 나 Microsoft Azure에서도 MySQL HeatWave 가 사용이 가능하다고 하니 더 많은 관심과 활용이 될 것으로 보입니다.
수행 해볼 수 있는 TPC-H 쿼리는 MySQL 팀으로 부터 제작된 22개 쿼리가 있으며 포스팅에서는 그 중 4개를 수행 하였으며, 다른 TPC-H 쿼리에 대한 정보는 아래 github 에서 확인 하실 수 있습니다.
HeatWave on AWS
2022년 9월 12일날 오라클 News 페이지를 통해서 해당 내용이 공식 Announces 되었습니다.
Oracle은 오늘 Amazon Web Services(AWS)에서 MySQL HeatWave 를 사용할 수 있다고 발표했습니다. MySQL HeatWave는 단일 MySQL 데이터베이스 내에서 OLTP, 분석, 기계 학습 및 기계 학습 기반 자동화를 결합한 유일한 서비스입니다. AWS 사용자는 이제 트랜잭션 처리를 위한 Amazon Aurora, 분석을 위한 Amazon Redshift 또는 Snowflake on AWS, 기계 학습을 위한 SageMaker와 같은 별도의 데이터베이스 간에 시간 소모적인 ETL 복제 없이 하나의 서비스에서 트랜잭션 처리, 분석 및 기계 학습 워크로드를 실행할 수 있습니다.

지금까지는 Oracle Cloud HeatWave 가 OLAP 이나 분석 쿼리에서 좋은 성능을 낸다고 알려져있었음에도 불구하고 AWS 에서 RDS, Aurora MySQL 또는 Azure Database for MySQL 등에서 DB를 Production 용으로 사용하는 환경에서는 같이 사용하기가 어려운 점이 있었다고 생각을 합니다.
이번 공식 Announces 된 내용과 같이 AWS 에서 사용할 수 있다는 점은 앞으로 MySQL 을 Production 용 으로 사용하는 환경에서 그 다음 목적인 데이터 분석이나 OLAP 용 쿼리를 수행하기 위해서 사용하였던 기존의 여러 솔루션이나 다른 DB 중에서 한가지 더 선택권이 추가 되었다는 중요한 의미가 될것도 같으며, MySQL 에서 사용하던 데이터에 대해서 별도의 ETL 이나 CDC 또는 이기종 DW 용 DB 를 사용하지 않고도 MySQL 인스턴스를 사용할 수 있다는 점도 매우 큰 장점이 될 것이라고 생각이 됩니다.
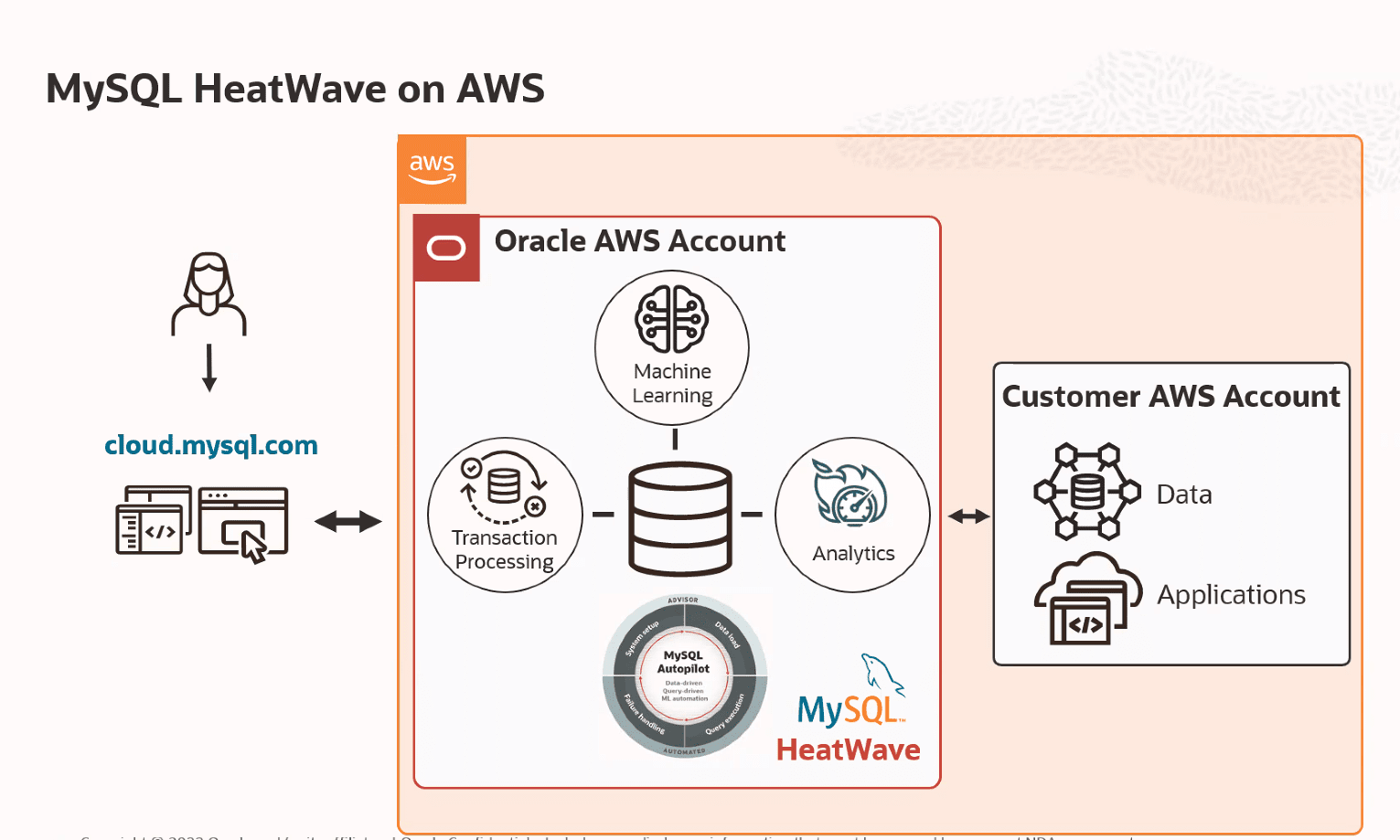
[oracle-is-bringing-mysql-heatwave-to-aws]
들은 바에 의하면 AWS 에서 HeatWave 서비스는 아직 국내에서는 Pre Release 형태인것으로 알고 있으며, 사용시에 사용중인 AWS 계정에 대한 정보를 Oracle과 협업을 통해서 별도의 작업이 진행이 필요하다고 하며, 그 이후에 RDS 나 EC2 와 같은 AWS 내 리소스로 확인될 것이라고 전해들었습니다.
(이부분은 명확치 않음, 조금 더 정확히 아시는 내용은 코멘트나 이메일 부탁드립니다)
앞으로 AWS 에서 사용에 대한 부분이 확인된다면 추가적으로 내용은 업데이트 하도록 하겠으며, 이번 포스팅은 여기서 마무리 하도록 하겠습니다.
Reference
Reference URL
• mysql.com/heatwave-introduction
• mysql.com/tpch-quickstart
• oracle.com/heatwave-for-mysql-technical-deep-dive
• github.com/oracle/heatwave-tpch
• oracle.com/mysql-heatwave-on-aws
Documents
• MySQL HeatWave White Paper
연관된 다른 글




Principal DBA(MySQL, AWS Aurora, Oracle)
핀테크 서비스인 핀다에서 데이터베이스를 운영하고 있어요(at finda.co.kr)
Previous - 당근마켓, 위메프, Oracle Korea ACS / Fedora Kor UserGroup 운영중
Database 외에도 NoSQL , Linux , Python, Cloud, Http/PHP CGI 등에도 관심이 있습니다
purityboy83@gmail.com / admin@hoing.io
