









Last Updated on 4월 21, 2023 by Jade(정현호)
안녕하세요.
이번에는 AWS Aurora MySQL 에서 설치형 MySQL로 복제를 구성에 관련 된 여러 가지 내용을 확인 해보도록 하겠습니다.
Contents
구성 환경
• AWS Aurora MySQL : 버전 3.02.0
• 설치형 MySQL 버전 : 8.0.23
• OS : CentOS 버전 7.9
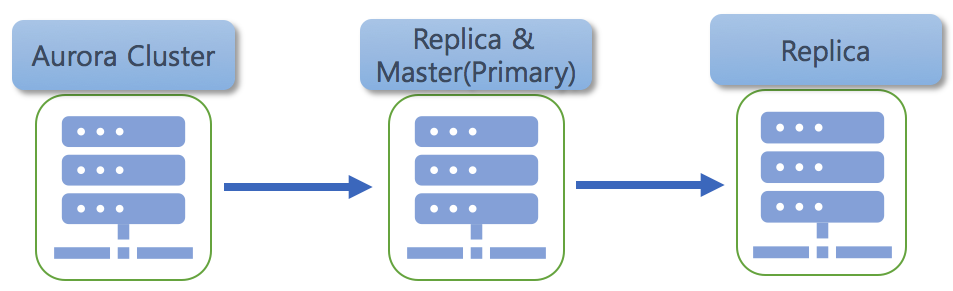
Aurora MySQL Cluster 를 복제 Source 로 하고 다음 단계에서는 설치형 MySQL 에서는 Aurora MySQL을 복제를 하는 구성을 진행하려고 합니다.
그리고 차후에 다시 Replica 을 생성하여 Chaining Replication 형태를 구성하기 위해서 Replica&Master(Primary) 형태로 구성하려고 합니다.
복제 소스가 되는 Aurora MySQL 에서는 별도의 파라미터 그룹을 사용하여 사용중인 환경인 시나리오 입니다.
파라미터 값 변경
Aurora MySQL 에서 파라미터 그룹내 파라미터를 수정하는 단계 입니다.
Aurora MySQL에서 복제를 사용하기 위해서는 먼저 바이너리 로그를 활성화는 과정이 필요하며, 활성화를 위해서 변경해야 할 파라미터는 binlog_format 입니다.
만약 별도의 파라미터 그룹을 사용하지 않는다면 별도의 파라미터 그룹으로 변경하는 작업이 선행 되어야 합니다.
binlog_format 변경
binlog_format 를 변경하기 위해서는 파라미터 그룹 중에서 Cluster Parameter Group 타입의 파라미터를 선택 해야 합니다.
파라미터 마다 Cluster Parameter Group 과 DB Parameter Group 에 모두 있거나 또는 한 곳에만 있거나 하는 형태로 각각 다르며 binlog_format 의 경우는 Cluster Parameter Group 에만 존재 합니다.
클러스터 수준의 파라미터와 DB 수준의 파라미터 그룹에 대한 정보는 아래 문서를 참조하시면 됩니다.
사용중인 파라미터 그룹을 찾아가는 방법으로 변경 하려는 RDS 메뉴 -> Aurora Cluster 에서 찾아갈 수 있습니다.
변경 하려는 클러스터 선택 -> Configuration(설정) -> DB cluster parameter group 을 클릭

파라미터를 선택 후에 검색 창에서 binlog_format 를 입력 합니다.

AWS Aurora MySQL 의 경우 binlog_format 의 기본값은 OFF 이며, 적용 방식(Apply type) 이 static 임으로 적용 후에 사용중인 인스턴스의 재시작이 필요 합니다.
[참고] RDS for MySQL 의 binlog_format 의 적용 방식은 Dynamic 으로 온라인 중에 변경 가능 합니다.
(RDS for MySQL 와 Aurora MySQL 의 차이가 있음)
다만 RDS for MySQL 에서 바이너리 로그를 활성화 하기 위해서는 RDS 구성 설정에서 백업이 활성화 되어야 합니다.
파라미터 편집을 선택 후 파라미터 값을 변경 합니다 복제 안정성을 위해서 ROW 또는 MIXED 를 선택 하면 되며, 포스팅에서는 ROW 선택 하였습니다.
선택 후 Save changes(변경사항 저장) 을 클릭 합니다
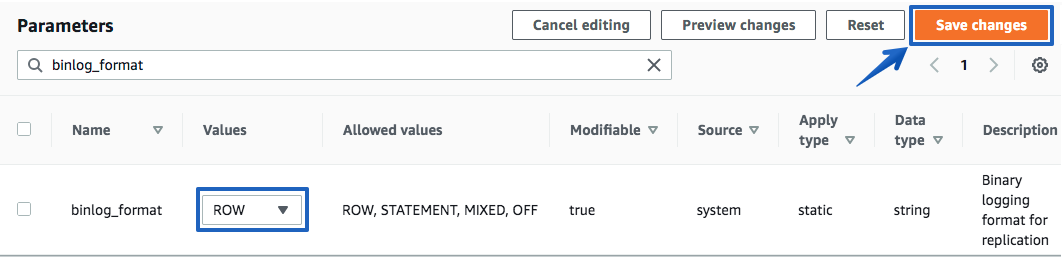
Cluster Parameter Group 의 경우 보통 인스턴스에 적용 중이라고 표시 되지 않거나 재부팅 필요 여부 등이 표시 되지는 않습니다.
다만 binlog_format 의 경우 재부팅이 필요한 파라미터 임으로 사용중인 인스턴스의 파라미터 그룹을 수정 하였다면 인스턴스의 재시작을 해야 적용이 됩니다.
재부팅 전에 DB 에 접속하여 파라미터를 조회하면 변경이 적용 된 것으로 보이나 실제로는 적용이 된 상태는 아니며 Primary 인스턴스에 대한 정보가 확인이 되지 않습니다(show master status 명령어 결과)
mysql> show global variables like '%binlog_format%'; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | binlog_format | ROW | +---------------+-------+ mysql> show master status\G Empty set (0.01 sec) -- 재부팅 전에는 확인이 되지 않음
변경한 파라미터에 대한 반영은 인스턴스 별로 재시작을 해야 적용이 됩니다.

일반적인 경우 1개 이상의 리더 인스턴스가 있을 수 있으며, 그럴 경우 라이터 인스턴스와 리더 인스턴스 모두를 각각 재시작이 필요 합니다.
관련된 내용은 아래 AWS 클러스터 재시작 항목을 참조 하시면 됩니다.
Writer , Reader 2대 일 경우, Failover 를 해서 2개 인스턴스 모두 재시작하는 하는 형태로도 진행 가능 합니다.
이럴 경우 01(또는 1번) 인스턴스가 다시 Writer 로 하고자 한다면 한번 더(총 두번) Failover 를 진행 하면 됩니다.
재시작을 진행해도 된다면 아래의 확인 메세지 항목에서 확인(Confirm) 을 선택하여 재시작을 진행 합니다

재시작 완료 후에 다시 DB에 접속하여 정보를 조회 했을 때 아래와 같이 정보가 확인이 되게 됩니다.
mysql> show master status\G
*************************** 1. row ***************************
File: mysql-bin-changelog.000002
Position: 156
Binlog_Do_DB:
Binlog_Ignore_DB:
Executed_Gtid_Set:
binlog I/O cache
바이너리 로그를 활성화 하게 되면 binlog 이벤트에 대한 로깅이 트랜잭션 커밋과 같은 중요한 작업의 일부와 통합되기 때문에 데이터베이스 성능을 저하시킬수 있습니다.(커밋 대기 시간 증가 및 처리량 감소)
일반적인 MySQL에서는 binlog 파일을 로컬 스토리지(디스크)에 작성하게 되지만, Aurora MySQL은 binlog 파일을 Aurora 스토리지 엔진에 쓰게 됩니다.
MySQL은 binlog 이벤트를 binlog 파일에 쓸 뿐만 아니라 동일한 파일에서 binlog 이벤트를 읽기 때문에 MySQL이 이러한 binlog 이벤트를 다른 MySQL 데이터베이스로 복제하기 시작할 때 binlog 파일에 의해 성능 병목 현상이 발생 될 수 도 있습니다.
Aurora MySQL 2.10 버전부터(3.0 버전도 포함) 이와 같은 성능 저하 사례를 개선하기 위해 binlog I/O 캐시라는 새로운 기능이 도입 되었으며, Aurora MySQL은 바이너리 로그를 활성화하면 binlog 이벤트를 동일한 파일에 능동적으로 복제합니다.
binlog I/O 캐시는 최신 binlog 이벤트를 순환 캐시(circular cache)에 보관하여 Aurora 스토리지 엔진의 읽기 I/O를 최소화합니다.
(binlog I/O 캐시는 db.t2 및 db.t3 인스턴스 클래스를 제외한 대부분의 Aurora MySQL 인스턴스에서 활성화됩니다.)
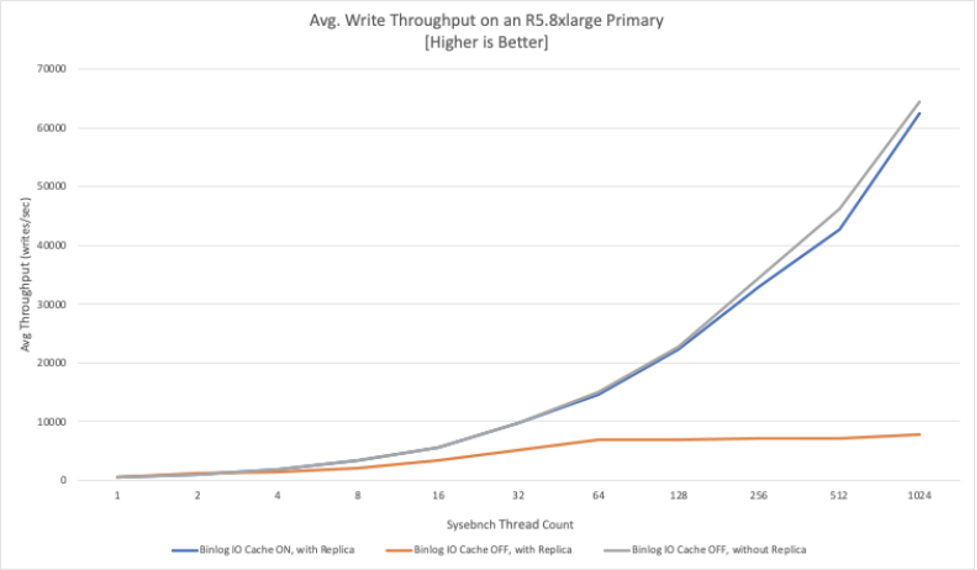
다음 그래프(그림1)에서는 binlog I/O 캐시를 켜고(파란색 선), binlog I/O 캐시 끄고(주황색 선) 초당 평균 쓰기 수를 측정했습니다. 이는 binlog I/O 캐시를 통해 얻을 수 있는 처리량 향상을 보여 주고 있습니다.
[그림1]
또한 그래프(그림1)에서 "without Replica" 설정 처리량은 회색 선으로 표시되어 있으며, 읽기 전용 복제본의 I/O 경합 없이 최적의 성능을 보여 줍니다.
이는 binlog I/O 캐시가 활성화되면 원본 인스턴스가 쓰기 처리량(파란색)의 증가에 따라 복제본이 연결되지 않은 것처럼(회색) 최적의 쓰기 처리량으로 확장될 수 있음을 보여 줍니다.
AWS 클러스터 재시작
Aurora MySQL 버전에 따라서 라이터 인스턴스 재기동에 관련된 동작이 차이가 나게 됩니다.
Aurora PostgreSQL 및 버전 2.10 이전 Aurora MySQL
- Aurora PostgreSQL 호환 버전 과 Aurora MySQL 호환 버전 버전 1 및 버전 2.10 이전 버전의 경우 클러스터의 라이터 DB 인스턴스를 재부팅 하여 전체 Aurora DB 클러스터를 재부팅 합니다.
즉 라이터 DB 인스턴스를 재부팅하면 클러스터의 각 리더 DB 인스턴스에 대해서도 재부팅이 시작됩니다.
이 방식으로 클러스터 전체 파라미터 변경 사항이 모든 DB 인스턴스에 동시에 적용하게 할 수 있습니다.
그러나 모든 DB 인스턴스를 재부팅하면 클러스터가 잠시 중단 됨에 따라 전제 다운이 발생 됩니다.
Aurora MySQL 버전 2.10 이상
- Aurora MySQL 버전 2.10 이상에서는 클러스터의 리더 인스턴스를 재부팅하지 않고 Aurora MySQL 클러스터의 라이터 인스턴스를 재부팅할 수 있습니다.
이렇게 하면 라이터 인스턴스를 재부팅하는 동안 읽기 작업에 대한 클러스터의 고가용성을 유지하는 데 도움이 됩니다. 나중에 편리한 일정에 따라 리더 인스턴스를 재부팅할 수 있습니다.
그래서 지금 사용하는 버전이 2.10 이전 버전이라면 라이터 인스턴스의 재기동에 주의 해야 합니다.
사용하는 버전 2.10 이하거나 아니면 조금 더 다운타임을 줄이기 위해서는 failover 를 하는 것도 방법입니다.
Auora MySQL 에서 Failover 하면 라이터 인스턴스로 승격되는 대상 과 현재 라이터 인스턴스(곧 리더 인스턴스가 될 인스턴스) 모두 리부팅 하게 됩니다.
순서는 라이터 인스턴스로 승격이 되는 리더 인스턴스 -> 현재 라이트 인스턴스(곧 리더 인스턴스가 될) 순으로 진행 됩니다.
#### 순서는 위에서 아래 입니다.
# 인스턴스 02 - Reader
May 15, 2022, 3:47:04 PM UTC
DB instance shutdown
May 15, 2022, 3:47:12 PM UTC
DB instance restarted
# 인스턴스01 - Writer
May 15, 2022, 3:47:12 PM UTC
A new writer was promoted. Restarting database as a reader.
May 15, 2022, 3:47:17 PM UTC
DB instance restarted
인스턴스가 2개인 경우(라이터 1개 , 리더 1개) 이런 식으로 failover 를 하고 다시 failover 를 해서 적은 다운 타임 재부팅을 진행 할 수 있습니다.
01 :W / 02 :R -> Failover -> 01:R / 02:R 로 변경 되었다가 다시 Failover 를 통해서 01:W / 02:R 로 변경 하시면 됩니다.
binlog 보관주기 변경
복제본에 대한 데이터베이스의 초기 복사가 완료 되고 복제가 설정되기 전까지 binlog 파일은 보존이 되어있어야 합니다.
binlog 파일의 보관 기간을 설정이 필요하며, 이 설정을 지정하지 않으면 Aurora MySQL 에서 기본값은 NULL 입니다.
Aurora MySQL에 대해 NULL은 이진 로그가 느리게 정리됨을 의미합니다
그래서 Aurora MySQL 이진 로그는 특정 기간(보통 하루 이하) 시스템에 남아 있을 수 있습니다.
현재 binlog 보관 주기에 대한 정보는 rds_show_configuration 를 통해서 확인 할 수 있습니다.
mysql> CALL mysql.rds_show_configuration; +------------------------+-------+------------------------------------------+ | name | value | description | +------------------------+-------+------------------------------------------+ | binlog retention hours | NULL | binlog retention hours specifies | | | | the duration in hours before binary logs | | | | are automatically deleted. | +------------------------+-------+------------------------------------------+
기본적으로는 설정된 내역이 없으므로 설정이 필요 합니다.
[참고] RDS for MySQL의 경우 NULL은 이진 로그가 보존되지 않음을 의미합니다(0시간).
아래는 binlog 파일 보관주기를 6일로 설정하는 내용 입니다.
mysql> CALL mysql.rds_set_configuration('binlog retention hours', 144);
mysql> CALL mysql.rds_show_configuration;
+------------------------+-------+------------------------------------------+
| name | value | description |
+------------------------+-------+------------------------------------------+
| binlog retention hours | 144 | binlog retention hours specifies |
| | | the duration in hours before binary logs |
| | | are automatically deleted. |
+------------------------+-------+------------------------------------------+
binlog 보관주기 설정에 따라서 고정적으로 Storage 공간이 사용 되게 됩니다. 그러므로 복제 설정이 완료 된 이후에는 binlog 보관주기 값을 1~2일 정도로 조절(변경) 하는 것이 필요 하다고 생각 합니다.
복제 구성
Aurora MySQL 에서 복제 구성하기 위한 사전 준비가 완료 되었으며, 복제 작업을 진행 하도록 하겠습니다.
복제 방식은 여러가지로 구분 할 수 있으며, 그 중에서 binlog 파일과 포지션 정보를 통해서 복제하는 방법과 gtid 를 통해서 복제를 수행하는 방법으로도 구분 할 수 있습니다.
포스팅은 보통적으로 많이 사용 되는 binlog 파일과 포지션 정보를 통한 복제 설정으로 내용이 작성되었습니다.
Snapshot
복제 설정을 위해서 binlog 파일 정보와 포지션 정보가 필요하며, Aurora MySQL 에서 확인 하기 위해서는 snapshot 을 이용해야 합니다.
snapshot은 Aurora Cluster 의 Write instance 에서 진행할 수 있습니다.
작업(Action) 메뉴 -> 스냅샷 생성(Take snapshot) 을 선택 합니다.

snapshot 이름을 지정 후에 하단의 스냅샷 생성(Take snapshot) 을 클릭 합니다.

snapshot 생성이 시작하게 되면 아래와 같이 생성중 임을 확인 할 수 있으며 새로고침 버튼을 눌러서 진행중 또는 완료 여부 를 확인 할 수 있습니다.

snapshot 생성은 백업을 실행하는 것으로 업무 와 시스템 상황을 고려하여 snapshot 수행 시간이나 일자를 고려 해야 합니다.
생성이 완료 되면 아래와 같은 상태를 확인 할 수 있습니다.
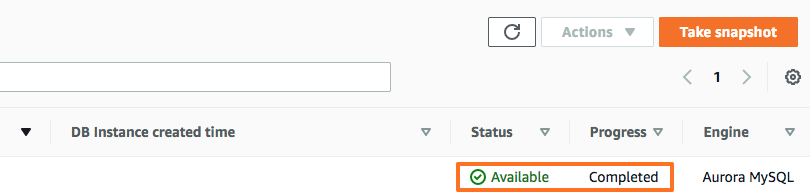
스냅샷을 통한 클러스터 생성
이전 단계에서 생성한 snapshot 을 통해서 새로운 Aurora Cluster 생성을 진행 합니다.
생성된 snapshot 을 선택 후 스냅샷 복원(Restore snapshot) 을 선택 합니다.

생성시 필수적으로 지정하거나 변경 해야하는 내용에 대해서 설정하면 되며, 먼저 아래와 같이 DB 이름(클러스터명)을 입력을 해야 합니다.
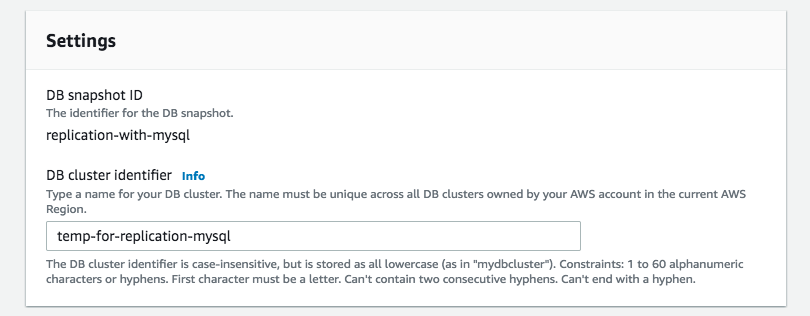
그 다음 네트워트(VPC) 에 대한 설정을 진행 하며 각각의 환경에 맞게 VPC 나 서브넷 그룹을 변경 합니다.

Public Access 의 경우 원본 Aurora DB에서의 설정과 무관하게 NO 가 먼저 선택되어 있으므로 사용하는 환경에 따라서 변경이 필요 할 수 있습니다.

인스턴스 클래스 타입의 경우 해당 DB는 생성 후 필요한 정보(binlog 파일과 pos 정보) 확인 후 삭제 될 예정으로 선택 가능한 가장 낮은 클래스를 선택 합니다.
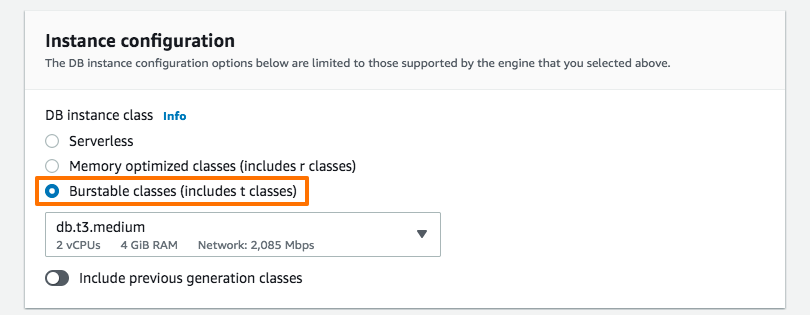
이 부분은 파라미터 그룹의 선택 대한 부분으로 기존에(복제 원본 대상의) 사용중인 파라미터 그룹을 동일하게 선택 합니다.
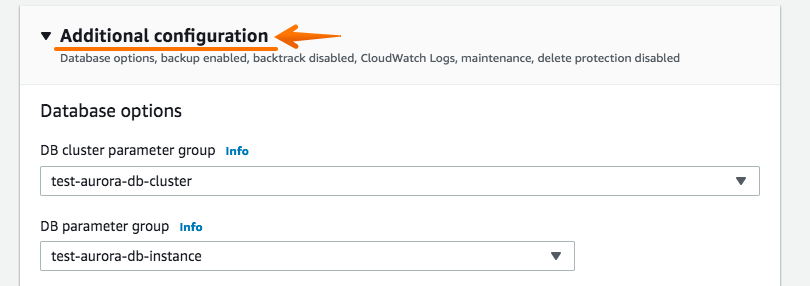
지금 생성 하는 인스턴스는 복제 설정이 완료 후에 바로 삭제할 임시성 인스턴스 임으로 아래와 같이 2개 항목에 대해서는 체크 해제(uncheck) 하고 아래의 클러스터 복원(Restore DB Cluster) 를 선택 합니다

복원을 선택하면 아래와 같이 Aurora DB 클러스터와 1개의 Write instance 생성이 시작 됩니다.

복원된 인스턴스의 로그&이벤트 정보에서 binlog 파일명과 포지션 정보를 확인 합니다.

초기 데이터 Migration
복제 설정을 하기전에 초기 데이터를 unload 및 load 하는 마이그레이션 과정이 필요 합니다.
• 데이터 unload
PROMPT> mysqldump -h 엔드포인트정보 \ --databases 데이터배이스명 --single-transaction --set-gtid-purged=OFF \ --no_create_db \ -u 계정명 -p > backup.sql
mysqldump 를 통해서 데이터 백업을 진행하면 되며, 데이터는 동일하기 때문에 백업 수행은 snapshot 으로 신규 생성한 임시 Aurora Cluster 에서 수행해도 됩니다.
용량이 크다면 사용중인 운영 DB의 부하를 주지 않기 위해서 더욱 snapshot 으로 생성한 임시 DB 에서 데이터 백업을 수행 하면 됩니다.
위의 명령어에서 중간의 --no_create_db 는 추출되는 SQL 문장에서 drop database 와 create database 를 기록하지 않기 위해서 지정한 옵션으로 데이터를 로드 할 Replica 인스턴스에 데이터베이스가 생성되어 있다면 위와 같이 --no_create_db 를 사용하면 됩니다.
Replica 인스턴스에서 별도로 database 를 생성하지 않았거나, 생성해야할(또는 복제 대상의) 데이터베이스가 많다면 위의 옵션을 제거 하고 dump 를 받아서 적재를 수행하는 것도 한가지 방법 입니다.
• 데이터 load
$ mysql -u 계정명 -p ... -- 접속 후 source 명령어로 데이터 적재 mysql> source basckup.sql
백업된 sql 파일은 위와 같이 Replica 인스턴스에 접속하여 source 명령어로 적용을 하면 됩니다.
server_id 확인
복제 환경에서 서버 별로(인스턴스 별로) server_id 는 고유 해야 합니다.
먼저 Aurora Read Replica 에서 접속하여 server_id를 확인 해봅니다.
mysql> select @@server_id; +-------------+ | @@server_id | +-------------+ | 1213919770 | +-------------+
RDS 에서 server_id 는 수정이 불가능한 항목으로 RDS 안의 정보등으로 설정됩니다.

Source 대상의 Aurora Cluster 에서 지정되는 server_id 의 단위가 커서 중복이 될 수 확율은 매우 낮으나 복제 시작전에 Replica 인스턴스의 server-id 값에 대해서 확인은 해보고 진행하도록 합니다.
$ grep -i server-id /etc/my.cnf server-id=38023
* my.cnf 경로는 default 경로이며, 위의 server-id 는 예시 입니다.
Replica의 binlog 활성화
Replica 인스턴스에서 또 다른 복제 설정으로 Replica 를 연결하는 chaining replication 구성시에는 Replica 에서도 binlog 활성화 및 상황에 따라서 추가적인 파라미터도 활성화가 필요 합니다.
설치형 MySQL 의 my.cnf 설정파일에서 아래와 같이 설정 합니다.
$ vi /etc/my.cnf log-bin=binlog-1 log_slave_updates=ON binlog_expire_logs_seconds=86400
log_slave_updates 는 Replica 이면서 Master(Primary) 일 경우 소스 서버(Primary)에서 수신한 변경 내역을 Replica 인스턴스의 자체 바이너리 로그에 기록하는지 여부의 시스템 변수 입니다.
위의 설정으로 binlog 를 활성화 하였다면 binlog 보관 주기도 설정도 필요 합니다.
관련 시스템 변수는 binlog_expire_logs_seconds 이며 기본 값은 2592000초로 30일(30*24*60*60초) 입니다.
8.0 버전 부터 초 단위로 설정 가능 하며 위에서의 86400 초는 1일 설정이며 값은 예시 입니다.
추가로 Multi-Threaded Replication 을 설정 하려면 아래 포스팅을 참조하여 Replica 인스턴스에서 설정을 진행하시면 됩니다.

모든 설정(my.cnf) 이 완료 되었다면 MySQL 을 재시작 합니다.
$ sudo systemctl restart mysqld
* 설치 방법에 따라서 재시작 명령어는 다를 수 있습니다.
복제 전용 유저 생성
복제 설정(연결) 을 위해서는 복제 전용 유저 생성 해서 하도록 하겠습니다.
• 유저 생성 및 권한 지정
mysql> CREATE USER 'repl_user'@'%' IDENTIFIED WITH mysql_native_password BY '패스워드'; mysql> GRANT REPLICATION CLIENT, REPLICATION SLAVE ON *.* TO 'repl_user'@'%';
* 계정명과 대역대는 예시입니다.
change master 및 복제시작
Replica 인스턴스에서 change master 명령어를 통해서 복제를 설정 할수 있습니다.
해당 부분은 AWS RDS for MySQL 이 아닌 설치형 MySQL 환경에서의 복제 설정 내용 입니다.
Replica 인스턴스에 접속하여 아래와 같이 수행을 합니다.
mysql> CHANGE REPLICATION SOURCE TO SOURCE_HOST = '클러스터_엔드포인트', SOURCE_PORT = 3306, SOURCE_USER = '복제유저_계정명', SOURCE_PASSWORD = '비밀번호', SOURCE_LOG_FILE = 'mysql-bin-changelog.000002', SOURCE_LOG_POS = 670;
참고1) MySQL 8.0.23 부터 새로운 새로운 명령어가 도입 되었음
참고2) SOURCE_HOST(이전의 MASTER_HOST) 는 8.0.17 이전 버전까지는 호스트명 60 자까지 지원 하였고, 그 이후 버전 부터는 최대 255자 까지 호스트명이 지원됨
참고3) binlog 가 Write instance 및 Reader instance 모두에서 활성화 되어 있음
참고4) 8.0.23 이전 버전의 CHANGE MASTER 명령어
mysql> CHANGE MASTER TO MASTER_HOST = '클러스터_reader_엔드포인트', MASTER_PORT = 3306, MASTER_USER = '복제유저_계정명', MASTER_PASSWORD = '비밀번호', MASTER_LOG_FILE = 'mysql-bin-changelog.000002', MASTER_LOG_POS = 670;
설정이 완료 되었다면 복제를 시작 합니다.
mysql> start replica; mysql> show replica status\g 또는 mysql> start slave; mysql> show slave status\G
Replica 인스턴스가 접속한 복제 대상, 즉 Source 환경의 인스턴스에 접속하여 아래 명령어로 Replica 인스턴스 정보를 확인 해봅니다.
mysql> show slave hosts\G
*************************** 1. row ***************************
Server_id: 38023
Host:
Port: 3306
Master_id: 2128467298
Slave_UUID: ......
추가로 Source 환경의 Aurora Cluster Write instance 에서 접속하여 테이블이나 데이터를 입력하여 복제가 정상적으로 수행 되는지를 확인 해봅니다.
Post Action
복제가 완료 되었다면 복제 진행을 위해서 생성 과 설정 한 내역에 대해서 정리를 진행해야 하며 아래 항목에 대해서 정리를 합니다.
1. snapshot 으로 생성한 임시 Aurora MySQL Cluster
2. snapshot 복원을 위해서 생성한 snapshot
3. binlog 보관 기간 변경(아래는 24시간(1일) 로 변경하는 예시임)
mysql> CALL mysql.rds_set_configuration('binlog retention hours', 144);
4. mysqldump 로 백업(unload) 받은 sql 파일 삭제
Reference
Reference URL
• aws.amazon.com/AuroraMySQL.Replication
• amazon.com/aurora-mysql-improve-binlog-performance
• aws.amazon.com/Aurora.Managing.ParameterGroups
• aws.amazon.com/USER_RestoreFromSnapshot
• aws.amazon.com/USER_CreateSnapshotCluster
•aws.amazon.com/mysql_rds_set_configuration
관련된 다른 글



Principal DBA(MySQL, AWS Aurora, Oracle)
핀테크 서비스인 핀다에서 데이터베이스를 운영하고 있어요(at finda.co.kr)
Previous - 당근마켓, 위메프, Oracle Korea ACS / Fedora Kor UserGroup 운영중
Database 외에도 NoSQL , Linux , Python, Cloud, Http/PHP CGI 등에도 관심이 있습니다
purityboy83@gmail.com / admin@hoing.io


