









Last Updated on 4월 13, 2022 by Jade(정현호)
안녕하세요
이번 포스팅에서는 MySQL 전반적인 아키텍처에 대해서 정리 하였으며 그중에서 MySQL 엔진 아키텍처를 먼저 정리하였습니다.
해당 내용은 Real MySQL 8.0 책에 대해서 정리한 내용 입니다.
Contents
MySQL 엔진 아키텍처
MySQL 서버는 사람의 머리 역할을 담당하는 MySQL 엔진과 손발 역할을 담당하는 스토리지 엔진으로 구분할 수 있으며, 손과 발 역할을 담당하는 스토리지 엔진은 핸들러 API 를 만족하면 누구든지 스토리지 엔진을 구현하여 MySQL 추가 하여 사용할 수 있습니다.
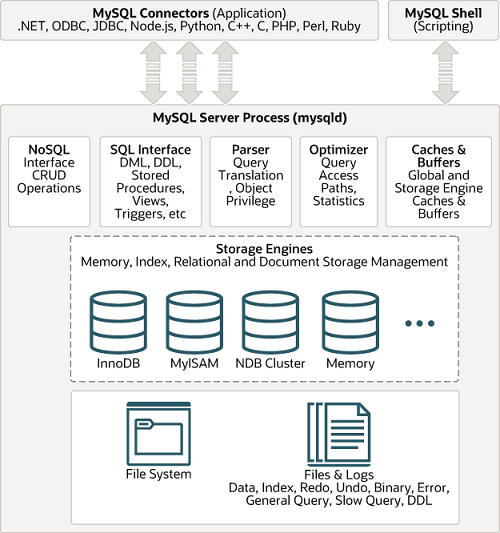
위의 이미지는 기본적인 MySQL 서버 엔진 아키텍처 입니다.
MySQL은 다른 DBMS에 비해 구조가 독특하며 다릅니다 이런 다른점 때문에 다른 DBMS에서는 가질수 없는 많은 장점을 누릴 수 있습니다. 반대로 다른 DBMS 에서는 문제가 되지 않거나 생각치 않아도 될 부분이 가끔 문제가 될수도 있습니다.
MySQL은 보통의 상용 DBMS 와 같이 대부분의 프로그래밍 언어로 부터 접근 방법을 모두 지원 합니다.
MySQL 서버는 크게 MySQL 엔진과 스토리지 엔진 으로 구분 할 수 있습니다.
MySQL 서버 주요 구성 요소
MySQL 엔진
MySQL 엔진은 클라이언트로 부터 접속 및 쿼리 요청을 처리하는 커넥션 핸들러와 SQL 파서 및 전처리기, 쿼리의 최적화된 실행을 위한 옵티마이저가 중심으로 이루어져 있습니다.
MySQL 은 표준 SQL(ANSI SQL) 문법을 지원하기 때문에 표준 문법에 따라 작성된 다른 DBMS에서 사용하는 쿼리도 호환되어 실행 할 수 있습니다
스토리지 엔진
실제 데이터를 디스크 스토리지에 저장하거나 디스크 스토리지로 부터 데이터를 읽어오는 부분을 스토리지 엔진이 담당 합니다.
MySQL 에서는 여러가지 스토리지 엔진을 사용할 수 있습니다.
아래와 같이 테이블을 생성하게 되면 해당 테이블은 앞으로 정의 된 스토리지 엔진에서 처리하게 됩니다.
SQL> create table tb_test(col1 int, col2 varchar(100)) ENGINE=InnoDB;
위에서 생성한 테이블은 InnoDB 스토리지 엔진으로 정의 하였기 때문에 앞으로 쿼리의 처리는 InnoDB 스토리지 엔진에서 처리를 하게 됩니다.
각 스토리지 엔진은 성능 향상을 위해서 각각의 다른 형태의 캐시 기능을 내장하고 있습니다.
핸들러 API
MySQL 엔진의 쿼리 실행기에서 데이터를 쓰거나 읽거나 할 때는 각 스토리지 엔진에 쓰기 또는 읽기를 요청 하게 되며, 이러한 요청을 핸들러(Handler) 요청이라고 하고, 여기서 사용 되는 API를 핸들러 API 라고 합니다.
InnoDB 스토리지 엔진도 핸들러 API 를 이용해 MySQL 엔진과 데이터를 주고 받게 됩니다.
이러한 핸들러 사용에 대한 정보는 아래 명령어로 확인 할 수 있습니다.
SQL> show global status like '%Handler%';
MySQL 스레딩 구조
MySQL 서버는 프로세스 기반이 아닌 스레드 기반으로 동작합니다.
그래서 크게 포그라운드 스레드와 백그라운드 스레드로 구분 할 수 있습니다.
MySQL 서버에서 실행 중인 스레드의 목록은 performance_schema 데이터베이스의 threads 테이블을 통해 확인 할 수 있습니다
SQL> select thread_id, name,type, processlist_user,processlist_host from performance_schema.threads order by type, thread_id;
확인되는 여러개의 스레드 중에서 'thread/sql/one_connection' 스레드가 실제 사용자의 요청을 처리 하는 포그라운드 스레드 입니다.
백그라운드 스레드 개수는 MySQL 서버의 설정에 따라서 내용과 수는 가변적이며, 동일한 이름의 스레드가 2개 이상 보이는 것은 여러개 스레드가 동일 작업을 병렬로 처리하는 경우 입니다.
포그라운드 스레드
포그라운드 스레드는 최소한 MySQL 서버에 접속된 클라이언트 수 만큼 존재 하며, 주로 각 사용자 요청한 쿼리를 처리 합니다.
작업을 마치고 커넥션을 종료하면 해당 스레드는 다시 스레드 캐시(Thread Cache) 로 돌아가게 됩니다.
이때 스레드 캐시에 일정 개수 이상의 대기 중인 스레드가 있다면 캐시에 넣지 않고 스레드를 종료 합니다
(관련 시스템 변수 : thread_cache_size)
포그라운드 스레드는 데이터를 MySQL의 데이터 버퍼나 캐시로 부터 가져오며 버퍼카 캐시에 없는 경우 직ㅈ버 디스크의 데이터나 인덱스 파일로 부터 데이터를 읽어서 처리를 하게 됩니다.
MyISAM 테이블은 디스크 쓰기 작업까지 포그라운드 스레드가 처리하지만, InnoDB 테이블은 데이터 버퍼나 캐시까지만 포그라운드 스레드가 처리하고 나머지 작업은 백그라운드 스레드가 처리 하게 됩니다.
백그라운드 스레드
MyISAM의 경우에는 해당 사항이 없는 부분이지만, InnoDB 는 아래와 같이 여러 작업이 백그라운드로 처리 됩니다.
• 인서트 버퍼(Insert Buffer)를 병합하는 스레드
• 로그를 디스크로 기록하는 스레드
• InnoDB 버퍼 풀의 데이터를 디스크로 기록하는 스레드
• 데이터를 버퍼로 읽어 오는 스레드
• 잠금이나 데드락을 모니터랑 하는 스레드
여러 스레드 중 가장 중요한 것은 로그 스레드(Log thread) 와 버퍼의 데이터를 데이터로 내려쓰기 작업을 처리하는 쓰기 쓰레드(Write thread) 일 것 입니다.
MySQL 5.5 버전부터 데이터 읽기 스레드와 데이터 읽기 스레드의 개수를 2개 이상으로 설정할 수 있습니다.
(관련 시스템 변수 : innodb_write_io_threads , innodb_read_io_threads)
InnoDB 에서도 데이터를 읽는 작업은 주로 클라이언트 스레드에서 처리 되기 때문에 읽기 스레드는 많이 설정할 필요가 없지만, 쓰기 스레드는 아주 많은 작업을 백그라운드에서 처리 하기 때문에 내장 일반 디스크 일 경우 2~4 정도, DAS 나 SAN , NVMe 와 같은 더 빠른 디스크 유형을 사용할 경우 최적으로 사용할 수 있을 만큼 충분히 설정하는 것 이 좋습니다.
데이터 쓰기 작업은 지연(버퍼링) 되어 처리 할 수도 있지만 읽기 작업은 절대로 지연되지 않습니다.
그래서 일반 적인 상용 DBMS 에는 대부분 쓰기 작업은 버퍼링(지연)해서 일괄 처리 하는 기능이 탑재되어 있으며, InnoDB도 이런 방식을 사용 합니다.
하지만 MyISAM 은 그렇지 않고 사용자 스레드가 쓰기 작업 까지 함께 처리 하도록 되어있습니다
그래서 InnoDB 에서는 DML 로 데이터가 변경되는 경우 데이터가 디스크의 데이터 파일로 완전히 저장 될때 까지 기다리지 않아도 됩니다.
메모리 할당 및 사용 구조
MySQL 에서 사용 되는 메모리 공간은 크게 글로벌 메모리 영역과 로컬 메모리 영역으로 구분 할 수 있습니다.
글로벌 메모리 영역
글로벌 메모리 영역은 MySQL 서버가 시작 되면서 생성된 영역으로 생성이 되면 모든 스레드에 의해 공유 되며, 대표적인 영역은 다음과 같습니다.
테이블 캐시
InnoDB 버퍼 풀
InnoDB 어댑티브 해시 인덱스
InnoDB 리두 로그 버퍼
로컬 메모리 영역
클라이언트 스레드가 쿼리를 처리 하는데 사용하는 메모리 영역 이며, 대표적으로 커넥션 버퍼와 정렬(sort) 버퍼 등이 있습니다.
클라이언트가 사용되는 메모리 공간이라고 하여 클라이언트 메모리 영역이라고 하며, 서버와의 커넥션 세션이라고 하기 때문에 로컬 메모리 영역 이라고도 표현 합니다.
스레드 별로 독립적으로 사용 되고, 다른 스레드와 공유 되지 않으며, 로컬 메모리 공간의 중요한 특징으로 각 쿼리의 용도별로 필요할 때만 공간이 할당되고 필요하지 않은 경우 할당되지 않을수 있습니다.
또한 커넥션이 열려 있는 동안 계속 할당된 상태로 남아 있는 공간도 있으며(커넥션 버퍼나 결과 버퍼), 그렇지 않고 쿼리를 실행하는 순간만 할당하는 소트 버퍼나 조인 버퍼가 있습니다.
플러그인 스토리지 엔진 모델
MySQL 의 특징 중에 대표적인 것은 플러그인 모델 입니다.
플러그인에서 사용할 수 있는 것이 스토리지 엔진만 있는 것은 아닙니다. 예를 들어 검색 엔진을 위한 검색어 파서도 플러그인 형태로 개발해서 사용할 수 있으며, 사용자 인증을 위한 Native Authentication 이나 Caching SHA-2 Authentication 등도 플러그인으로 구현되어 제공이 되고 있는 것 입니다.
MySQL은 이미 많은 스토리지 엔진을 가지고 있지만 사용자의 요구사항과 필요에 의해 추가로 다른 형태의 스토리지 엔진이 필요 할 수도 있습니다.
이러한 요건을 바탕으로 직접 스토리지 엔진을 개발 하여 사용할 수 도 있습니다.
앞에서 설명 한 내용과 같이 쿼리 수행에서의 대부분의 작업은 MySQL 엔진 영역에서 처리가 되며 "데이터 읽기/쓰기" 작업만 스토리지 엔진이 처리하게 됩니다.
MySQL 에서는 핸들러(Handler) 라는 단어를 자주 접하게 될 것 입니다.
프로그래밍에서 어떤 기능을 호출하기 위한 역할을 하는 객체를 핸들러(Handler) 라고 표현하며 MySQL 엔진이 스토리지 엔진을 조정하기 위해서 핸들러 라는 것을 사용하게 되는 것 입니다.
각 스토리지 엔진에서 데이터를 읽거나 저장하기 위해서는 핸들러를 통해야 하며, 상태 변수 가운데 "Handler_" 로 시작하는 것이 많음을 확인 할 수도 있습니다.
사용중인 MySQL 서버에서 지원하는 스토리지 엔진이 어떤 것이 있는지는 아래 쿼리를 통해서 확인 하실수 있습니다.
mysql> show engines;
Support 컬럼에 표시되는 값은 아래 4가지 입니다.
YES : 스토리지 엔진이 포함되어 있고, 사용 가능으로 활성화 상태
DEFAULT : 'YES' 와 동일한 상태이지만, 필수 스토리지 엔진을 의미함
NO : MySQL 서버에 포함되어 있지 않음
DISABLED : 포함 되어있지만 파라미터에 의해 비활성화 된 상태
MySQL 서버가 적절히 준비가 되어있다면 플러그인 형태로 빌드된 스토리지 엔진의 라이브러리를 다운로드 해서 넣기만 하면 사용할 수 가 있습니다. 또한 플러그인 형태의 스토리지 엔진은 손쉽게 업그레이드를 할 수도 있습니다.
스토리지 엔진이외 모든 플러그인의 내용은 "show plugins" 명령어로 확인 할 수 있습니다.
컴포넌트
MySQL 8.0 부터는 기존의 플러그인 아키텍처를 대체하기 위해서 컴포넌트 아키텍처가 지원하게 되었습니다.
관련 해서는 이전 포스팅에서 정리하여 내용을 참고해주시면 됩니다.

쿼리 실행 구조(쿼리 처리 절차)
쿼리를 실행하는 관점에서 MySQL 구조를 간략하게 글로 설명과 기능별로 아래와 같이 나눠볼 수 있습니다.
쿼리 파서(Parser) -> 전처리기(Preprocessor) -> 쿼리 옵티마이저(Query Optimizer) -> 쿼리 실행기(Query Execution) -> 핸들러(스토리지 엔진)
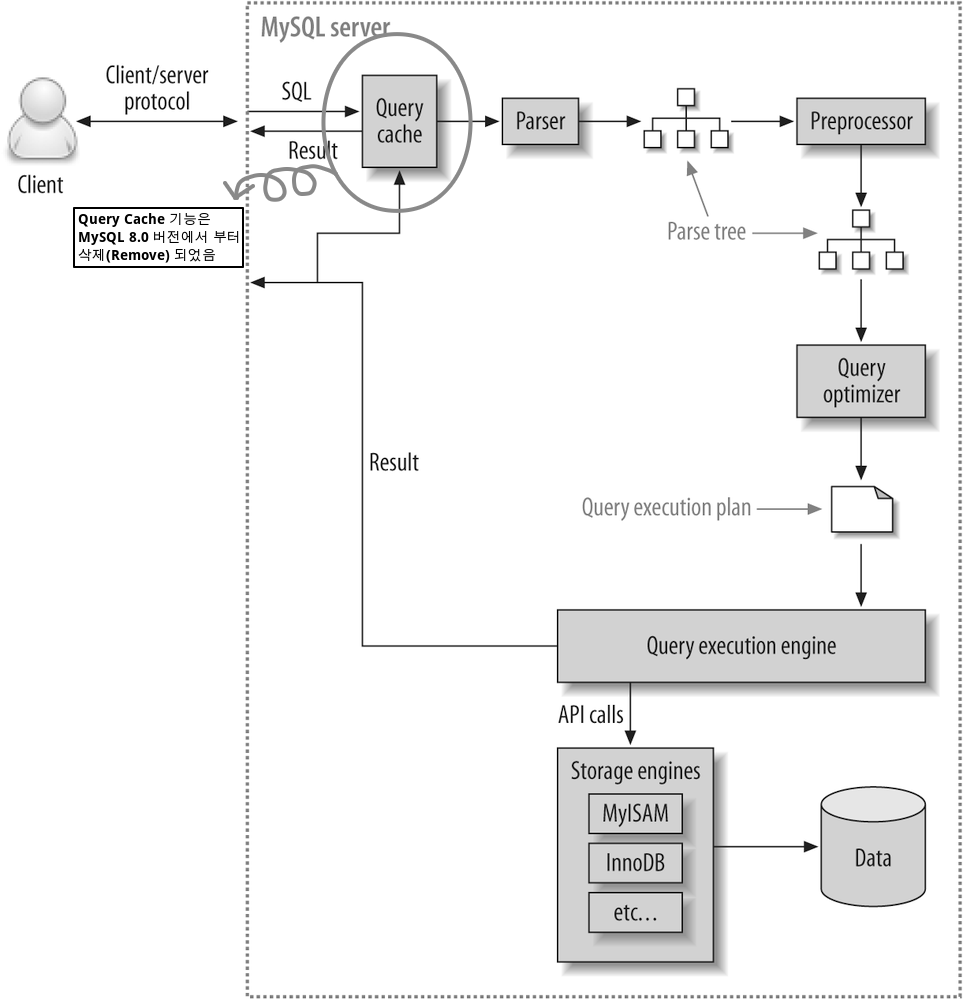
[oreilly.com/high-performance-mysql]
[참고] MySQL 8.0 에서는 Query Cache 기능이 Remove 되었습니다.
Query Cache 기능은 동일 SQL 실행시 쿼리 처리 과정에서 Parsing, Preprocesor, Query Optimizer 단계를 수행하지 않고 캐시에 담겨진 이전 결과를 즉시 반환 합니다.
다만 단점으로 테이블 데이터가 변경되면 캐싱된 데이터 삭제가 필요하고 그 과정에서 퀴리 캐시에 접근하는 쓰레드에 Lock이 걸리게 되고(Waiting for query cache lock) 그에 따라서 동시 처리 기능 저하가 발생되는 경우가 많았습니다.
위의 그림은 5.7 버전까지의 Flow Chart 이며 그래서 Query Cache 에 대한 이미지를 별도로 수정하였습니다.
1) 쿼리 파서
쿼리 문장을 토큰(MySQL 이 인식할 수 있는 최소 단위의 어휘나 기호)으로 분리해 트리 구조로 만드는 과정이며, 쿼리의 문법 오류가 이 단계에서 확인 되며, 문법 오류가 있을 경우 사용자에게 오류 메세지가 전달 됩니다.
2) 전처리기(Preprocessor)
이전의 Parser 과정을 통해서 만들어진 파서 트리를 기반으로 문장에 구조적인 문제점이 있는지를 확인 하며, 토큰의 테이블 이름,컬럼명, 내장함수 와 같은 객체를 매핑해 해당 객체의 존재 여부와 접근 권한 등을 확인하는 과정을 해당 과정에서 수행하게 됩니다.
3) 쿼리 옵티마이저
쿼리 문장을 저렴한 비용(Cost)으로 가장 빠르게 처리 할지를 결정하는 역할 과 실행계획을 작성을 담당하며, DBMS의 두뇌에 해당한다고 할 수 있습니다.
옵티마이저에는 대표적으로 지정된 우선 순위에 따라서 스코어를 매겨서 실행 계획을 수립하는 RBO (Rule-Based Optimizer) 와 수행 가능한 방법의 비용 과 테이블 통계 정보를 통한 Cost 에 따른 실행 계획을 수립하는 CBO(Cost-Based Optimizer) 가 있으며 MySQL 에서는 CBO 를 사용하며 최근의 대부분 RDB 에서의 기본 옵티마이저는 CBO 를 사용하고 있습니다
여기에서 사용되는 Cost 의 기준은 여러가지가 있으며 where 절의 검색조건 유무, 조인 유무, join 조건, 인덱스 , 인덱스 통계 정보 등의 조건들과 그로 인하여 가능한 여러 실행 계획의 Cost 를 비교하여 결정하게 됩니다.
쿼리를 수행 후 아래와 같이 마지막 실행한 쿼리의 Cost 를 확인 할 수 있습니다.
mysql> SHOW STATUS LIKE '%Last_query_cost%'; +-----------------+--------------+ | Variable_name | Value | +-----------------+--------------+ | Last_query_cost | 19069.348704 | +-----------------+--------------+
4) 실행 엔진
옵티마이저가 두뇌라면 실행 엔진과 핸들러는 손과 발에 비유할 수 있을 것 같습니다.
옵티마이저 -> 실행 엔진 -> 핸들러
실행 엔진은 만들어진 실행 계획대로 각 핸들러에게 요청을 하게 되고 또 다시 받은 결과를 또 다른 핸들러 요청하여 입력으로 연결하는 역할을 하게 됩니다.
5) 핸들러(스토리지 엔진)
핸들러는 MySQL 서버의 가장 밑단에서 MySQL의 실행 엔진의 요청에 따라서 데이터를 디스크에 저장하고 디스크로 부터 읽어 오는 역할을 담당하게 됩니다.
핸들러는 결국 스토리지 엔진을 의미하며, InnoDB 의 테이블일 경우 핸들러는 InnoDB 스토리지 엔진이 되게 됩니다.
복제
MySQL 서버에서 복제(Replication)은 매우 중요한 기능과 역할을 담당하고 있으며, 지금까지 MySQL 서버에서 복제는 계속해서 많은 발전을 거듭해 왔습니다.
MySQL 복제에 관해서는 아래 포스팅을 참조하시면 됩니다.



스레드 풀
MySQL 서버 상용 버전의 엔터프라이즈 에디션(EE) 에서는 스레드 풀(Thread Pool) 기능을 제공하고 있지만,MySQL 커뮤니티 에디션에서는 기능을 지원하지 않습니다.
MySQL 엔터프라이즈 에디션의 스레드 풀은 MySQL 서버 프로그램에 내장되어 있지만, Percona Server의 스레드 풀은 플러그인 형태로 구현되어 있습니다.
그래서 MySQL 커뮤니티 에디션에서 스레드 풀 기능을 사용 하고자 할 경우 동일한 버전의 Percona Server 에서 스레드 풀의 플러그인 라이브러리(thread_pool.so) 을 커뮤니티 에디션으로 가져와 설치를 해서 사용 할 수 있습니다
스레드 풀은 동시 처리 요청이 많더라도 MySQL 서버의 CPU가 제한된 개수의 스레드 처리에만 집중 할 수 있게 해서 서버 자원 소모를 줄이는데 목적이 있습니다.
더 자세한 사항은 추후 별도로 포스팅하도록 하겠습니다
트랜잭션 지원 메타데이터
데이터베이스에서 테이블 구조 정보, 오브젝트 정보 등의 여러 정보를 담아 두는 곳을 보통 데이터 딕셔너리 또는 메타데이터 라고 합니다.
MySQL 서버는 5.7 버전까지는 테이블의 구조를 확장자 FRM 파일에 저장하고 일부 스토어드 프로시저 등은 또 다른 파일(TRN,TRG,PAR,...) 기반으로 관리를 하였습니다.
이러한 파일 기반의 메타데이터는 생성 과 변경 작업에 대해서 트랜잭션이 지원 하지 않기 때문에 테이블의 생성 또는 변경 도중에 MySQL이 비정상적으로 종료가 된다면 일관되지 않은 상태로 남아 있을수 있는 문제점이 있었습니다.
MySQL 8.0 에서는 이러한 문제점을 보완/해결 하기 위해서 테이블의 구조나 스토어드 프로시저 코드 관련된 정보를 모두 InnoDB의 테이블에 저장하도록 개선 하였습니다.
MySQL 서버가 작동하고 하는데 기본적으로 필요한 테이블을 묶어서 시스템 테이블 이라고 하며 이런 시스템 테이블이 모두 InnoDB 스토리지 엔진에 저장되어 사용하도록 개선 되었습니다.
시스템 테이블과 데이터 딕셔너리 정보 모두 mysql DB에 저장되며 mysql.idb 이름의 테이블 스페이스에 저장되게 됩니다.
이런 개선 사항 덕분에 8.0 버전 부터는 스키마 변경 작업 중간에 MySQL 이 비정상 종료 되더라도 스키마 변경이 완전 성공 또는 완전 실패로 정리되게 됩니다(작업 중인 상태로 남아 있는 것을 방지함)
MySQL 아키텍처 중에서 엔진 아키텍처에 대해서 정리 하였고, 다음 포스팅에서는 InnoDB 스토리지 엔진 아키텍처에 대해서 정리하도록 하겠습니다.
해당 포스팅은 Real MySQL 8.0 책의 많은 내용 중에서 일부분의 내용만 함축적으로 정리한 것으로 모든 내용 확인 및 이해를 위해서 직접 책을 통해 모든 내용을 확인하시는 것을 권해 드립니다
Reference
Reference Book
• Real MySQL 8.0
다음 이어지는 글

관련된 다른 글



Principal DBA(MySQL, AWS Aurora, Oracle)
핀테크 서비스인 핀다에서 데이터베이스를 운영하고 있어요(at finda.co.kr)
Previous - 당근마켓, 위메프, Oracle Korea ACS / Fedora Kor UserGroup 운영중
Database 외에도 NoSQL , Linux , Python, Cloud, Http/PHP CGI 등에도 관심이 있습니다
purityboy83@gmail.com / admin@hoing.io
