









Last Updated on 9월 14, 2021 by Jade(정현호)
해당 글은 아래 이전글에서 이어 지는 글 입니다.
HDFS의 파일 저장
HDFS의 파일 저장은 클라이언트가 네임노드에게 파일 저장을 요청하는 단계, 클라이언트가 데이터노드에게 패킷을 전송하는 단계, 클라이언트가 파일 저장을 완료 하는 단계로 구성 됩니다. 이번 포스팅에서는 파일 저장의 단게별 세부 동작에 대해서 확인 해보도록 하겠습니다.
1. 파일 저장 요청
클라이언트가 HDFS에 파일을 저장하는 경우 파일을 저장하기 위한 스트림을 생성을 해야 합니다. 아래 이미지는 클라이언트가 네임노드와 통신 과정을 통해 파일 저장용 스트림 객체를 생성하는 과정입니다.
진행 순서
1. 하둡은 FileSystem 이라는 추상 클래스에 일반적인 파일 시스템을 관리하기 위한 메서드를 정의하게 됩니다. 그리고 이 추상 클래스를 상속받아 각 파일 시스템에 맞게 구현된 다양한 파일 시스템 클래스를 제공 하고 있습니다. HDFS 에 파일을 저장하는 경우 DistributedFileSystem 을 사용하며 클라이언트는 DistributedFileSystem의 create 메서드를 호출해 스크림 객체를 생성하게 됩니다.
2. DistributedFileSystem 은 클라이언트에게 반환할 스트림 객체로, FSDataOutputStream을 생성 합니다. FSDataOutputStream 은 데이터노드 와 네임노드의 통신을 관리하는 DFSOutputStream을 래핑하는 클래스 이며 DistributedFieSystem은 DFSOutputStream 을 생성하기 위해서 DFSClient 의 create 메서드를 호출하게 됩니다.
3. DFSClient 는 DFSOutputStream 을 생성하게 되며 이때 DFSOutputStream 은 RPC 통신으로 네임노드의 create 메서드를 호출하게 됩니다 네임노드는 클라이언트의 요청이 유효한지 검사를 진행하게 되며 이미 생성된 파일이거나 권한에 문제가 있거나, 현재 파일 시스템의 용량을 초과한다면 오류를 발생시키게 됩니다.
네임노드는 파일 유효성 검사 결과가 정상 일 경우 파일 시스템 이미지에 해당 파일의 엔트리를 추가 합니다. 마지막으로 네임노드는 클라이언트에게 해당 파일을 저장할 수 있는 제어권을 부여 하게 됩니다.
4. 네임노드의 유효성 검사를 통과했다면 DFSOutputSteram 객체가 정상적으로 생성 됩니다. DistributedFileSystem 은 DFSOutputStream 을 래핑한 FSDataOutputStream 을 클라이언트에게 반환합니다.
2. 패킷 전송
클라이언트가 네임노드에게서 파일 제어권을 얻게 되면 파일 저장을 진행합니다. 이때 클라이언트는 파일을 네임노드에게 전송하지 않고 각 데이터노드에 전송 합니다. 그리고 저장할 파일은 패킷 단위로 나눠서 전송하게 됩니다 
진행 순서
1. 클라이언트는 스트림 객체의 write 메서드를 호출해 파일 저장을 시작하게 되며 DFSOutputStream은 클라이언트가 저장하는 파일을 64k 크기의 패킷으로 분할 합니다.
2. DFSOutputStream 은 전송할 패킷을 내부 큐인 데이터큐(dataQueue)에 등록 합니다 DFSOutputStream의 내부스레드가 데이터큐에 패킷이 등록된 것을 확인하면 DFSOutputSream 의 내장 클래스인 DataStreamer는 네임노드의 addBlock 메서드를 호출 하게 됩니다.
3. 네임노드는 DataStreamer에게 블록을 저장할 데이터노드 목록을 반환합니다. 이 목록은 복제본 수와 동일한 수의 데이터노드를 연결한 파이프라인을 형성 합니다. 예를 들어 HDFS의 복제본 수가 3으로 설정돼 있다면 데이터노드 3개가 파이프라인을 형성하게 됩니다.
4. DataStreamer 는 파이프라인의 첫 번째 데이터노드부터 패킷 전송을 시작하게 되며, 데이터노드는 클라이언트와 다른 데이터노드로 부터 패킷을 주고 받기 위해 DataXceiverServer 데몬을 실행 합니다. DataXceiverServer 는 클라이언트 및 다른 데이터노드와 패킷 교환 기능 제공 합니다.
첫 번째 데이터노드는 패킷을 저장하면서, 두 번째 데이터노드에게 패킷 저장을 요청합니다. 두 번째 데이터노드도 패킷을 저장하면서, 세 번째 데이터노드에게 패킷 저장을 요청 합니다. 마지막으로 세 번째 데이터노드가 패킷을 저장 합니다.
또한 첫 번째 데이터노드에 패킷을 저장할 때 DFSOutputStream 은 내부 큐인 승인큐(askQueue) 에 패킷을 등록 하고 승인큐는 패킷 전송이 완료됐다는 응답을 기다리는 패킷이 등록돼 있으며, 모든 데이터노드로 부터 응답을 받았을 때만 해당 패킷이 제거 됩니다.
5. 각 데이터노드는 패킷이 정상적으로 저장되면 자신에게 패킷을 전송한 데이터노드에게 ACK 메세지를 전송 합니다. ACK 메세지는 패킷 수신이 정상적으로 완료됐다는 승인 메세지 입니다. 승인 메세지는 파이프라인을 통해 DFSOutputStream 에게까지 전달 됩니다.
6. 각 데이터노드는 패킷 저장이 완료되면 네임노드의 blockReceived 메서드를 호출 합니다. 이를 통해 네임노드는 해당 블록이 정상적으로 저장됐다는 것을 인지 합니다.
7. DFSOutputStream 의 내부 스레드인 ResponseProcessor 는 파이프라인에 있는 모든 데이터노드로부터 승인 메시지를 받게 되면 해당 패킷을 승인큐에서 제거합니다. 만약 패킷을 전송하는 중에 장애가 발생하면 승인 큐에 있는 모든 패킷을 데이터큐로 이동 합니다.
그리고 네임노드에게서 장애가 발생한 데이터노드가 제거된 새로운 데이터노드 목록을 내려 받게 되고 마지막으로 새로운 파이프라인을 생성 한 후에 다시 패킷 전송 작업을 시작 합니다.
3. 파일 닫기
이제 스트림을 닫고 파일 저장을 완료를 합니다. 아래 이미지와 같이 클라이언트가 파일을 닫는 과정입니다.
진행 순서
1. 클라이언트는 DistributedFileSystem 의 Close 메서드를 호출해 파일 닫기를 요청 합니다.
2. DistribuedFileSystem 은 DFSOutputStream 의 Close 메서드를 호출 합니다 이 메서드는 DFSOutputStream 에 남아 있는 모든 패킷을 파이프라인으로 플러쉬(flush) 합니다.
3. DFSOutputStream 은 네임노드의 complete 메서드를 호출해 패킷이 정상적으로 저장됐는지 확인 합니다. 네임노드의 최소 블록 복제본 수만 저장됐다면 complete 메서드는 true 를 반환 합니다. DFSOutputStream 은 true 를 반환 받으면 파일 저장이 완료 된 것으로 설정 합니다.
HDFS의 파일 읽기
HDFS에 저장된 파일을 조회하는 과정에 대해서 단계 별로 확인 해보도록 하겠습니다.
1. 파일 조회 요청
클라이언트는 입력 스트림 객체를 이용해 HDFS 에 저장된 파일을 조회 할 수 있습니다. 아래 이미지는 클라이언트가 입력 스트림 객체를 생성하는 과정을 나타내고 있습니다.
진행 순서
1. 클라이언트는 DistriubutedFileSystem의 open 메서드를 호출해 스트림 객체 생성을 요청 하게 됩니다.
2. DistributedFileSystem 은 FSDataInputStream 객체를 생성합니다. 이때 FSDataInputStream은 DFSDataInputStream 과 DFSInputStream 을 차례대로 래핑 합니다. DistributedFileSystem 은 마지막 래핑이 되는 DFSInputStream 을 생성하기 위해 DFSClient 의 open 메서드를 호출 합니다.
3. DFSClient 는 DFSInputStream 을 생성 하고 이때 DFSInputStream은 네임노드의 GetBlockLocations 메서드를 호출해 조회 대상 파일의 블록 위치 정보를 조회 하게 됩니다.
[참고] DFSInputStream 은 한 번에 모든 블록을 조회하지 않고 기본 블록 크기의 10배수만큼 블록을 조회 합니다. 예를 들어 HDFS 기본 블록 크기가 64MB 이면 640MB의 블록을 조회 합니다.
4. 네임노드는 조회 대상 파일의 블록 위치 목록을 생성한 후 목록을 클라이언트에 가까운 순으로 정렬 합니다. 정렬이 완료 되면 DFSInputStream에 정렬된 블록 위치 목록을 반환합니다. DistributedSystem은 DFSClient 로 부터 전달 받은 DFSInputStream 을 이용해 FSDataInputStream 으로 생성해서 클라이언트에게 반환 합니다.
2. 블럭 조회
클라이언트가 실제 블록을 조회하는 과정에 대해서는 아래 이미지와 같은 순서(과정) 으로 진행 되게 됩니다.
진행 순서
1. 클라이언트는 입력 스트림 개체의 read 메서드를 호출해 스트림 조회를 요청 하게 됩니다.
2. DFSInputStream은 첫 번째 블록과 가장 가까운 데이터노드를 조회한 후, 해당 블록을 조회하기 위한 리더기를 생성 하고, 클라이언트와 블록이 저장된 데이터노드가 같은 서버에 있다면 로컬 블록 리더기 인 "BlockReadLocal" 을 성생하게 되고, 데이터노드가 원격에 있을 경우 "RemoteBlockReader" 를 생성하게 됩니다.
3. DFSInputStream 은 리더기의 read 메서드를 호출해 블록을 조회하게 되고, BlockReaderLocal 은 로컬 파일 시스템에 저장된 블록을 DFSInputStream 에게 반환하게 됩니다. 그리고 RemoteBlockReader는 원격에 있는 데이터노드에게 블록을 요청하며, 데이터노드의 DataXceiverServer 가 블록을 DFSInputStream 에게 반환합니다.
[참고] DFSInputStream 은 조회한 데이터의 체크섬을 검증하며, 체크섬에 문제가 있을 경우 다른 데이터노드에게 블록 조회를 요청 하게 됩니다.
4. DFSInputStream 은 파일을 모두 읽을 때까지 계속해서 블록을 조회하며, 만약 DFSInputStream 이 저장하고 있던 블록을 모두 읽었는데도 파일을 모두 읽지 못했다면 네임노드의 getBlockLocations 메서드를 호출해 불필요한 블록 위치 정보를 다시 요청 하게 됩니다. 이와 같이 파일을 끊김 없이 연속적으로 읽기 때문에 클라이언트는 스트리밍 데이터를 읽는 것처럼 처리 할 수 있습니다.
5. 네임노드는 DFSInputStream 에 클라이언트에게 가까운 순으로 정렬된 블록 위치 목록을 반환 합니다.
3. 입력 스트림 닫기
클라이언트가 모든 블록을 읽고 나면 입력 스트림 객체를 다아야 합니다. 아래 이미지는 입력 스트림을 닫는 과정 입니다.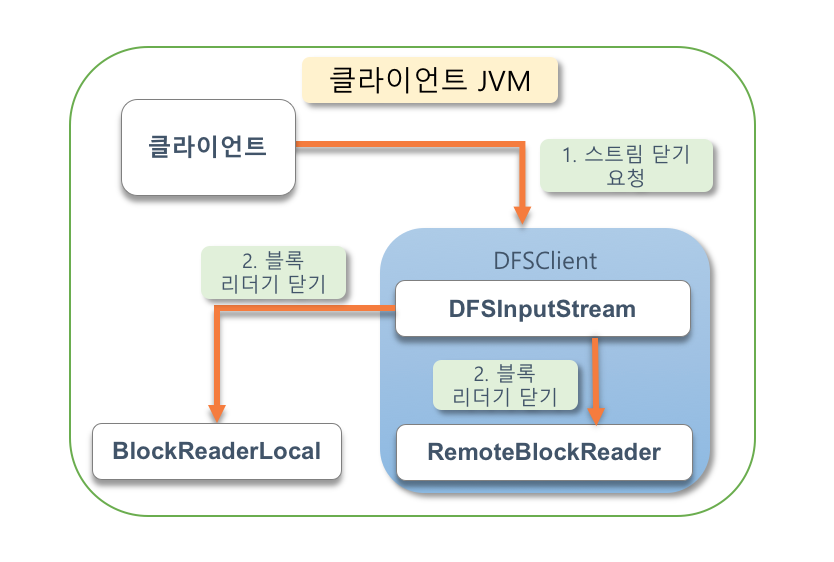
진행 순서
1. 클라이언트는 입력 스트림 객체의 close 메서드를 요청 해 스트림 닫기를 요청 합니다.
2. DFSInputStream 은 데이터노드와 연결돼 있는 커넥션을 종료 하며 블록 조회용으로 사용하였던 리더기도 닫아 주게 됩니다.
여기까지 HDFS 에 대한 이론적인 부분과 파일 저장,열기 등에 대해서 확인 하였습니다. 다음 포스팅에서 계속 진행하도록 하겠습니다.
※ Ref : 시작하세요! 하둡 프로그래밍(개정 2판) 책의 내용을 정리한 포스팅 입니다


Principal DBA(MySQL, AWS Aurora, Oracle)
핀테크 서비스인 핀다에서 데이터베이스를 운영하고 있어요(at finda.co.kr)
Previous - 당근마켓, 위메프, Oracle Korea ACS / Fedora Kor UserGroup 운영중
Database 외에도 NoSQL , Linux , Python, Cloud, Http/PHP CGI 등에도 관심이 있습니다
purityboy83@gmail.com / admin@hoing.io
정리자료로 노션에 개인정리를 위해 이미지를 캡쳐하여 사용했습니다. 혹시나 사용이 어려울 경우 알려주시면 지우겠습니다. 감사합니다.
안녕하세요
출처 링크만 남겨주시면 됩니다.
감사합니다.