









Last Updated on 9월 23, 2021 by Jade(정현호)
1. 하둡 설치 환경
아파치 하둡 사이트를 방문하면 0.20 버전부터 포스팅 시점에 3.3.0 까지 다양한 버전을 내려받을 수 있습니다. 설치는 소스코드를 컴파일 설치 와 미리 컴파일되어 패키징 또는 압축되어 있는 바이너리 형태를 통해 진행 할 수 있습니다.
포스팅에서는 2.10.1 버전을 설치 하도록 하겠으며 OS 는 CentOS 7.9 를 사용하였으며 총 4대의 가상 머신을 통해서 진행 하였습니다.
• Hadoop 버전
Ver : 2.10.1 버전
• 가상 머신 서버 (4EA)
vCPU : 2EA
Mem : 2GB
Disk : 50GB
OS : CentOS 7.9
• 서버 별 용도
호스트네임 용도
hdoop1 네임노드(NameNode)
hdoop2 보조네임노드, 데이터노드(DataNode)
hdoop3 데이터노드
hdoop4 데이터노드
• 서버 별 IP 와 호스트네임
hdoop1 192.168.56.71
hdoop2 192.168.56.71
hdoop3 192.168.56.71
hdoop4 192.168.56.71
보조네임노드는 (Active)네임도드의 장애 발생에 대비하는 용도이기 때문에 별도로 설치가 필요 합니다. 포스팅에서는 테스트 환경임으로 hdoop2 호스트에 보조네임노드 와 데이터노드를 같이 설치를 진행 하였습니다.
2. 실행 모드 결정
우선 어떤 방식으로 하둡을 실행할지를 결정할 필요가 있습니다. 하둡은 세 가지 실행 모드가 있습니다. 하둡을 설치하려는 용도에 맞게 모드를 선택해 설치를 해야 합니다.
• 독립 실행(Standardalone) 모드
하둡의 기본 실행 모드 입니다. 하둡 환경설정 파이에 아무런 설정하지 않고 실행하면 로컬 장비에서만 실행되기 때문에 로컬 모드라고도 합니다. 분산환경을 고려한 테스트나 사용이 불가하며, 단순히 맵리듀스 프로그램을 개발하고 해당 맵리듀스를 디버깅하는 용도로 적합한 모드 입니다.
• 가상 분산(Pseudo-distribued) 모드
하나의 장비에 모든 하둡 환경설정을 하고, 하둡 서비스도 이 장비에서만 제공 하는 방식 입니다. HDFS와 맵리듀스 와 관련된 데몬을 하나의 장비에서만 실행하게 됩니다.
• 완전 분산(Fully distributed) 모드
여러 대의 장비에 하둡이 설치된 경우 입니다. 하둡으로 라이브 서비스를 하게 도리 경우 이와 같은 방식으로 구성 합니다.
가상분산 모드를 선택 할 경우 한대의 장비만 준비하면 되고, 완전 분산 모드(Fully Distributed) 선택 할 경우 최소 2대 이상의 장비가 필요 합니다. 포스팅 환경에서는 완전 분산 모드로 진행 하겠습니다.
3. 사전 환경 구성
하둡 설치(구성) 전 필요한 환경을 구성을 먼저 진행이 필요 합니다.
3-1 자바 설치
먼저 하둡을 설치 하기 위해서는 반드시 자비가 미리 설치가 되어있어야 합니다. 하둡은 자바로 개발되어져 있고, 데몬을 구동할 때 JAR 파일을 사용하기 때문에 반드시 자바가 필요 합니다. 하둡 버전별 맞는 자바에 대한 정보는 아래 링크에서 확인 하시면 됩니다.
Supported Java Versions
- Apache Hadoop 3.3 and upper supports Java 8 and Java 11 (runtime only)
- Please compile Hadoop with Java 8. Compiling Hadoop with Java 11 is not supported:
HADOOP-16795 - Java 11 compile support OPEN
- Please compile Hadoop with Java 8. Compiling Hadoop with Java 11 is not supported:
- Apache Hadoop from 3.0.x to 3.2.x now supports only Java 8
- Apache Hadoop from 2.7.x to 2.10.x support both Java 7 and 8
포스팅에서 설치한 CentOS 가 Minimal 타입으로 설치되어 Java 설치전 필요 한 기타 패키지를 설치 하도록 하겠습니다.
• 기본 패키지 설치
[root]#yum -y install net-tools gcc gcc-c++ \ cmake vim git wget curl rsync unzip zip openssl
• 자바 설치
포스팅에서는 자바 1.8 버전을 설치하도록 하겠습니다 (모든 서버)
[root]# yum -y install java-1.8.0-openjdk.x86_64 \ java-1.8.0-openjdk-devel [root]# java -version openjdk version "1.8.0_292" OpenJDK Runtime Environment (build 1.8.0_292-b10) OpenJDK 64-Bit Server VM (build 25.292-b10, mixed mode)
3-2 프로토콜 버퍼 설치
하둡 2를 설치(사용) 하려면 반드시 프로토콜 버퍼(Protocol Buffer)의 설치가 필요 합니다. 프로토콜 버퍼는 구글에서 공개한 오픈소스 직렬화 라이브러리 입니다. IT 기술의 발달로 이기종 서버 간의 데이터 통신 또는 서로 다른 종류의 언어로 개발된 시스템간의 통신이 빈번하게 발생되고 있습니다 이러한 데이터에 대해서 전달하는 방식은 크게 텍스트 포멧(XML,JSON) 등을 이용하는 방법과 바이너리(Binary) 데이터를 이용하는 방법이 있을 수 있습니다.
텍스트 포맷을 이용하는 방식이 데이터를 이해하기 쉽고 각 언어별로 여러 종류의 파서가 제공되고 있어서 활용하기도 편리하긴 하지만, 데이터의 자체의 크기가 크고 그에 따라서 파서의 성능이 떨어진다는 단점이 있으며 , 바이너리 데이터는 데이터의 크기가 작기 때문에 성능이 좋지만 바이너리 코드를 만들고 이를 해독해야 하는 모듈을 별도로 만들어야 하는 부담이 있습니다.
구글은 이러한 바이너리 데이터 방식을 지원하기 위한 프로토콜 버퍼를 오픈소스로 공개하였으며 프로토콜 버퍼는 데이터를 연속된 비트로 만들고 이렇게 만들어진 비트를 해석해 원래의 데이터를 만들수 있습니다. 그래서 하둡2도 내부 데몬 간의 데이터 통신을 위해서 프로토콜 버퍼를 사용 하고 있습니다.
설치는 2.5.0 버전으로 설치하면 되며 Source Compile 로 설치해도 되며 이미 컴파일 된 바이너리 인 패키지를 이용하여 설치를 하여도 됩니다. 포스팅에서는 패키지(yum) 으로 패키지 설치를 진행하도록 하겠습니다.(모든 서버 설치)
설치 후 아래와 같이 버전이 정확히 출력되는지도 확인을 합니다
[root]# yum -y install protobuf protobuf-devel \ protobuf-java protobuf-c-compiler [root]# protoc --version libprotoc 2.5.0
3-3 그룹 생성 및 유저 생성
하둡을 설치하고 실행할 별도의 그룹 과 유저를 생성 하도록 하겠습니다(모든 서버) sudo 사용이 가능하도록 CentOS 에서 기본 sudo 그룹인 wheel 그룹을 세컨드 그룹으로 지정하였습니다.
# 그룹 생성 [root]# groupadd -g 1000 hadoop # 유저 생성(sudo 그룹까지 추가) [root]# useradd -g hadoop -G wheel -u 1000 hadoop # 패스워드 생성 [root]# passwd hadoop
포스팅 에서는 wheel 그룹에서 sudo 사용시 패스워드를 없이 사용하기 위해서 NOPASSWD 로 변경 하겠습니다
[root]# visudo ## 주석 처리 # %wheel ALL=(ALL) ALL ## 주석 해제 %wheel ALL=(ALL) NOPASSWD: ALL
3-4 /etc/hosts 수정
모든 서버(4개) 에서 /etc/hosts 를 아래와 같이 공통적으로 사용가능 하도록 지정을 합니다. IP 및 호스트명은 포스팅에서 사용되는 예시 입니다.
[root]# vi /etc/hosts 192.168.56.71 hdoop1 192.168.56.72 hdoop2 192.168.56.73 hdoop3 192.168.56.74 hdoop4
3-5 방화벽 및 SELinux 비 활성화
아래와 같이 방화벽 및 SELinux 를 중지 및 비 활성화를 합니다(모든 서버)
[root]# systemctl stop firewalld [root]# systemctl disable firewalld [root]# vi /etc/sysconfig/selinux SELINUX=disabled # disabled 으로 변경하고 저장 # SELinux stop(Disable) [root]# setenforce 0
3-6 서버간 SSH 인증 설정
서버 간의 SSH 접속 시 패스워드를 확인 하지 않고 자동 로그인이 가능하도록 생성한 공개키를 다른 서버에 전송하는 작업을 수행 합니다.(모든 서버, hadoop 일반 유저)
3-6-1 Key 생성
먼저 SSH 키를 생성을 진행 합니다 키 생성은 ssh-keygen 명령어를 이용 합니다.
## hadoop 유저로 변경 [root]# su - hadoop [hadoop]$ ssh-keygen -t rsa -b 4096 Generating public/private rsa key pair. Enter file in which to save the key (/home/hadoop/.ssh/id_rsa): [엔터] Created directory '/home/hadoop/.ssh'. Enter passphrase (empty for no passphrase): [엔터] Enter same passphrase again: [엔터] Your identification has been saved in /home/hadoop/.ssh/id_rsa. Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub. The key fingerprint is: SHA256:J52+2342342sdfsdfasdfasfasdfasf hadoop@xxxx The key's randomart image is: +---[RSA 4096]----+ |xxxxxxxx .. | |.xxxxxx.. | | o.xxxxxxx | |+xxxxxxxxx . | |=..xxxxxx + | |+.. . o.++ | |.xxxxxxxxxxx | | xxxxxxxxxxxx | | xxxxxxxx | +----[SHA256]-----+
3-6-2 공개키 전송(Copy)
생성 한 공개키(.pub)를 모든 서버로 전송 해야 합니다.
1번 서버에서 -> 1,2,3,4번 서버로
2번 서버에서 -> 1,2,3,4번 서버로
3번 서버에서 -> 1,2,3,4번 서버로
4번 서버에서 -> 1,2,3,4번 서버로
* 자기 노드(서버) 에도 키를 복사합니다
ssh-copy-id 를 이용하면 되며 아래와 같이 수행 합니다.
명령어 예시 : 매니저 서버-> 1번 서버로 공개키 복사
[hadoop]$ ssh-copy-id -i hdoop2 hadoop@hdoop2's password: [유저 패스워드입력] Number of key(s) added: 1 Now try logging into the machine, with: "ssh 'hdoop2'" and check to make sure that only the key(s) you wanted were added.
전송이 완료 되었다면 패스워드 없이 접속이 되는지 확인 해봅니다.
[hadoop]$ ssh hdoop2 Last login: Fri 2021 [hadoop@hdoop2 ~]$ hostname hdoop2 <– 정상적으로 접속이 확인됨
위와 같은 방법으로 공개키를 서버간에 모두 복사(전송)합니다.
4. 설치
설치는 위에서 언급된 것처럼 포스팅 시점에서 2.x.x 대 버전의 최신본인 2.10.1 버전 으로 설치를 진행 할 것입니다. 하둡은 아래 링크 에서 다운 받을 수 있습니다.

4-1 파일다운 로드 및 압축 해제
파일은 wget 등으로 직접 다운 로드 받을 수 있으며 다운로드 후 압축 해제 등을 진행 합니다. 파일은 첫번째 서버(master) 에서만 받아서 설정을 완료 후에 다른 노드로 복사를 진행 할 예정입니다.
# haoop 유저로 진행 hadoop$ wget https://downloads.apache.org/hadoop/common/hadoop-2.10.1/hadoop-2.10.1.tar.gz hadoop$ tar zxvf hadoop-2.10.1.tar.gz hadoop$ ln -s hadoop-2.10.1 hadoop
4-2 profile 설정 및 디렉토리 생성
기본적으로 필요한 몇가지 환경 변수에 대해서 ~/.bash_profile 파일에 HADOOP_HOME 변수를 추가하고, PATH에 하둡 실행 파일을 위한 경로도 추가해줍니다.(모드 노드)
hadoop$ vi ~/.bash_profile export HADOOP_HOME=/home/hadoop/hadoop export JRE_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.292.b10-1.el7_9.x86_64/jre export JAVA_HOME=$JRE_HOME export PATH=$PATH:$JRE_HOME/bin:$HADOOP_HOME/bin/:$HADOOP_HOME/sbin export HADOOP_HOME_WARN_SUPPRESS=TRUE source ~/.bash_profile
환경 변수 설정 이후 필요한 디렉토리를 아래와 같이 생성 합니다.
mkdir -p $HADOOP_HOME/pids mkdir -p $HADOOP_HOME/data/hdfs/namenode mkdir -p $HADOOP_HOME/data/hdfs/datanode mkdir -p $HADOOP_HOME/data/yarn/nm-local-dir mkdir -p $HADOOP_HOME/data/yarn/system/rmstore
4-3 하둡 환경설정 파일
하둡 데몬을 실행 시키기 위해서 설정이 필요한 환경 설정 파일이 있으며 해당 파일을 설정을 해야 설치 작업이 마무리가 되게 됩니다. 수정해야할 설정 파일은 Hadoop 설치 파일 홈 디렉토리 하위 디렉토리인 etc/hadoop 에 저장되어 있습니다.
수정을 해야하거나 하는 대표적인 파일은 아래와 같습니다.
(경로 $HADOOP_HOME/etc/hadoop)
• hadoop-env.sh
- 하둡을 실행하는 쉘 스크립트 파일에서 필요한 환경변수를 설정 합니다
- 이 파일에는 JAVA 경로 , 클래스 패스, 데몬 실행 옵션, LOG DIR, PID DIR 등을 설정 합니다.
- 파일 수정 : 아래와 같이 환경변수를 설정 합니다.
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.292.b10-1.el7_9.x86_64/jre export HADOOP_PID_DIR=/home/hadoop/hadoop/pids
• masters
- 보노네임노드를 실행할 서버를 설정 합니다.
- 가상 분산 모드로 설치 할 경우 보조네임노드를 실행 해야 합니다.
- 네임노드 HA 를 구성할 경우 스탠바이 네임노드가 보조네임노드의 기능을 대체 합니다.
- 가상 분산 모드로는 네임노드 HA 를 구성할 수 없기 때문에 보조네임노드를 반드시 실행 해야 합니다.
- 하둡 2 에서는 masters 파일이 생성돼 있지 않습니다. 가상 분산 모드로 하여 masters 파일이 필요할 경우 vi 에디터 등으로 내용을 입력하면서 파일을 생성 하면 됩니다.
• slaves
- 데이터노드를 실행할 서버를 설정 합니다.
- 여러개의 데이터노드를 설정할 수 있으며 아래와 같이 한줄에 하나의 서버를 기재 하면 됩니다.
- IP 또는 /etc/hosts 에 정의된 호스트 명을 사용 합니다.
hdoop2 hdoop3 hdoop4
• core-site.xml
- HDFS 와 맵리듀스에서 공통적으로 사용할 환경 정보를 설정 합니다.
- share/hadoop/common/hadoop-common-2.10.1.jar 에 포함돼 있는 core-default.xml 을 오버라이드 한 파일 입니다.
- core-site.xml 에 설정값이 없을 경우 core-default.xml 에 있는 기본 값을 사용 합니다
- 클러스터내 Name Node의 대한 설정이며, 아래와 같이 설정 합니다.
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hdoop1:9000</value>
</property>
</configuration>
•hdfs-site.xml
- HDFS에서 사용할 환경 정보를 설정 합니다
- share/hadoop/common/hadoop-common-2.10.1.jar 에 포함돼 있는 hdfs-default.xml 을 오버라이드 한 파일 입니다.
- hdfs-site.xml 에 설정값이 없을 경우 hdfs-default.xml 에 있는 기본값을 사용 합니다.
- dfs.replication : 이 속성은 HDFS의 저장될 데이터의 복제본 개수를 의미 합니다.
이 값을 1으로 설정하면 가상 분산 모드로 하둡을 실행
이 값을 3으로 설정하면 완전 분선 모드로 하둡을 구성(Fully-Distributed Mode)
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/data/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/data/hdfs/datanode</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>hdoop1:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hdoop1:50090</value>
</property>
</configuration>
•mapred-site.xml
- 맵리듀스에서 사용할 환경 정보를 설정 합니다.
- share/hadoop/common/hadoop-common-2.10.1.jar 에 포함돼 있는 mapred-default.xml 을 오버라이드 한 파일 입니다.
- mapred-site.xml 에 설정값이 없을 경우 mapred-default.xml 에 있는 기본값을 사용 합니다.
- mapreduce.framework는 맵리듀스 Job을 어떠한 모드로 실행할지를 나타냅니다
- 실행 모드는 로컬 모드 와 얀 모드(yarn) 가 있습니다.
- 로컬 모드는 하나의 JVM만으로 맵리듀스 Job을 실행하는 것으로 디버깅이나 테스트 용도로 적합 합니다.
hadoop$ cp mapred-site.xml.template mapred-site.xml
hadoop$ vi mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
•yarn-env.sh
- 얀을 실행하는 쉘 스크립트에서 필요한 환경 변수를 설정 합니다
- profile 이나 .bash_profile 등에서 JAVA_HOME 변수가 설정되어 있다면 별도로 설정할 필요는 없습니다.
- yarn-env.sh 에서는 최대 힙 크기를 1GB를 기본 값으로 사용 합니다
JAVA_HEAP_MAX=Xmx1000M
- 그래서 리소스 매니저, 노드매니저, 얀 히스토리 서버가 모두 최대 힙 크기 1GB 로 설정 됩니다.
- 각 데몬 별로 힙 크기를 다르게 설정할 경우 yarn-env.sh 파일에서 별도로 설정이 필요합니다.
•yarn-site.xml
- 얀에서 사용할 환경 정보를 설정합니다.
- share/hadoop/common/hadoop-common-2.10.1.jar 에 포함돼 있는 yarn-default.xml 을 오버라이드 한 파일 입니다.
- yarn-site.xml 에 설정값이 없을 경우 yarn-default.xml 에 있는 기본값을 사용 합니다.
- Resource Manager 관련 설정
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/home/hadoop/data/yarn/nm-local-dir</value>
</property>
<property>
<name>yarn.resourcemanager.fs.state-store.uri</name>
<value>/home/hadoop/data/yarn/system/rmstore</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hdoop1</value>
</property>
<property>
<name>yarn.web-proxy.address</name>
<value>0.0.0.0:8089</value>
</property>
</configuration>
4-4 hadoop 파일 전송
설정을 완료 하였다면 설정된 하둡2 설치 파일을 rsync 등의 명령어 등을 통해서 전체 서버에 배포합니다.
## 첫번째 서버(master) 에서 수행 # rsync 를 통해 remote 파일 전송 hadoop$ rsync -avzr --progress hadoop-2.10.1 hdoop2:~/ hadoop$ rsync -avzr --progress hadoop-2.10.1 hdoop3:~/ hadoop$ rsync -avzr --progress hadoop-2.10.1 hdoop4:~/ # ssh 를 통해 심볼릭 링크 생성 hadoop$ ssh hdoop2 ln -s hadoop-2.10.1 hadoop hadoop$ ssh hdoop3 ln -s hadoop-2.10.1 hadoop hadoop$ ssh hdoop4 ln -s hadoop-2.10.1 hadoop
5. 하둡 실행
5-1 네임노드 초기화
이제 네임노드를 초기화하고 모든 데몬을 실행하면 됩니다. 아래와 같이 hadoop 명령어를 호출해 초기화를 진행 합니다.(초기에 한번)
hadoop$ cd $HADOOP_HOME/bin hadoop$ ./hdfs namenode -format
[참고] 하둡1의 hadoop 명령어는 하둡2 에서 deprecated 된 명령어로 hdfs 명령어를 사용 하게 됩니다.
네임노드를 초기화(format) 를 하면 아래와 같은 로그가 출력 됩니다.
21/04/29 00:15:54 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = hdoop1/192.168.56.71 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.10.1 STARTUP_MSG: classpath = /home/hadoop/.. STARTUP_MSG: build = https://github.com/apache/hadoop -r 1827467c9a56f133025f28557bfc2c562d78e816; compiled by 'centos' on 2020-09-14T13:17Z STARTUP_MSG: java = 1.8.0_292 ************************************************************/ 21/04/29 00:15:54 INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT] 21/04/29 00:15:54 INFO namenode.NameNode: createNameNode [-format] Formatting using clusterid: CID-9e6aca79-0ee0-4964-8539-a073fd619a93 21/04/29 00:15:54 INFO namenode.FSEditLog: Edit logging is async:true 21/04/29 00:15:54 INFO namenode.FSNamesystem: KeyProvider: null 21/04/29 00:15:54 INFO namenode.FSNamesystem: fsLock is fair: true 21/04/29 00:15:54 INFO namenode.FSNamesystem: Detailed lock hold time metrics enabled: false 21/04/29 00:15:54 INFO namenode.FSNamesystem: fsOwner = hadoop (auth:SIMPLE) 21/04/29 00:15:54 INFO namenode.FSNamesystem: supergroup = supergroup 21/04/29 00:15:54 INFO namenode.FSNamesystem: isPermissionEnabled = false 21/04/29 00:15:54 INFO namenode.FSNamesystem: HA Enabled: false 21/04/29 00:15:54 INFO common.Util: dfs.datanode.fileio.profiling.sampling.percentage set to 0. Disabling file IO profiling 21/04/29 00:15:54 INFO blockmanagement.DatanodeManager: dfs.block.invalidate.limit: configured=1000, counted=60, effected=1000 21/04/29 00:15:54 INFO blockmanagement.DatanodeManager: dfs.namenode.datanode.registration.ip-hostname-check=true 21/04/29 00:15:54 INFO blockmanagement.BlockManager: dfs.namenode.startup.delay.block.deletion.sec is set to 000:00:00:00.000 21/04/29 00:15:54 INFO blockmanagement.BlockManager: The block deletion will start around 2021 Apr 29 00:15:54 21/04/29 00:15:54 INFO util.GSet: Computing capacity for map BlocksMap 21/04/29 00:15:54 INFO util.GSet: VM type = 64-bit 21/04/29 00:15:54 INFO util.GSet: 2.0% max memory 889 MB = 17.8 MB 21/04/29 00:15:54 INFO util.GSet: capacity = 2^21 = 2097152 entries 21/04/29 00:15:54 INFO blockmanagement.BlockManager: dfs.block.access.token.enable=false 21/04/29 00:15:54 WARN conf.Configuration: No unit for dfs.heartbeat.interval(3) assuming SECONDS 21/04/29 00:15:54 WARN conf.Configuration: No unit for dfs.namenode.safemode.extension(30000) assuming MILLISECONDS 21/04/29 00:15:54 INFO blockmanagement.BlockManagerSafeMode: dfs.namenode.safemode.threshold-pct = 0.9990000128746033 21/04/29 00:15:54 INFO blockmanagement.BlockManagerSafeMode: dfs.namenode.safemode.min.datanodes = 0 21/04/29 00:15:54 INFO blockmanagement.BlockManagerSafeMode: dfs.namenode.safemode.extension = 30000 21/04/29 00:15:54 INFO blockmanagement.BlockManager: defaultReplication = 3 21/04/29 00:15:54 INFO blockmanagement.BlockManager: maxReplication = 512 21/04/29 00:15:54 INFO blockmanagement.BlockManager: minReplication = 1 21/04/29 00:15:54 INFO blockmanagement.BlockManager: maxReplicationStreams = 2 21/04/29 00:15:54 INFO blockmanagement.BlockManager: replicationRecheckInterval = 3000 21/04/29 00:15:54 INFO blockmanagement.BlockManager: encryptDataTransfer = false 21/04/29 00:15:54 INFO blockmanagement.BlockManager: maxNumBlocksToLog = 1000 21/04/29 00:15:54 INFO namenode.FSNamesystem: Append Enabled: true 21/04/29 00:15:54 INFO namenode.FSDirectory: GLOBAL serial map: bits=24 maxEntries=16777215 21/04/29 00:15:54 INFO util.GSet: Computing capacity for map INodeMap 21/04/29 00:15:54 INFO util.GSet: VM type = 64-bit 21/04/29 00:15:54 INFO util.GSet: 1.0% max memory 889 MB = 8.9 MB 21/04/29 00:15:54 INFO util.GSet: capacity = 2^20 = 1048576 entries 21/04/29 00:15:54 INFO namenode.FSDirectory: ACLs enabled? false 21/04/29 00:15:54 INFO namenode.FSDirectory: XAttrs enabled? true 21/04/29 00:15:54 INFO namenode.NameNode: Caching file names occurring more than 10 times 21/04/29 00:15:54 INFO snapshot.SnapshotManager: Loaded config captureOpenFiles: falseskipCaptureAccessTimeOnlyChange: false 21/04/29 00:15:54 INFO util.GSet: Computing capacity for map cachedBlocks 21/04/29 00:15:54 INFO util.GSet: VM type = 64-bit 21/04/29 00:15:54 INFO util.GSet: 0.25% max memory 889 MB = 2.2 MB 21/04/29 00:15:54 INFO util.GSet: capacity = 2^18 = 262144 entries 21/04/29 00:15:54 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.window.num.buckets = 10 21/04/29 00:15:54 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.num.users = 10 21/04/29 00:15:54 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.windows.minutes = 1,5,25 21/04/29 00:15:54 INFO namenode.FSNamesystem: Retry cache on namenode is enabled 21/04/29 00:15:54 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is 600000 millis 21/04/29 00:15:54 INFO util.GSet: Computing capacity for map NameNodeRetryCache 21/04/29 00:15:54 INFO util.GSet: VM type = 64-bit 21/04/29 00:15:54 INFO util.GSet: 0.029999999329447746% max memory 889 MB = 273.1 KB 21/04/29 00:15:54 INFO util.GSet: capacity = 2^15 = 32768 entries 21/04/29 00:15:54 INFO namenode.FSImage: Allocated new BlockPoolId: BP-2033484593-192.168.56.71-1619622954949 21/04/29 00:15:54 INFO common.Storage: Storage directory /home/hadoop/data/hdfs/namenode has been successfully formatted. 21/04/29 00:15:54 INFO namenode.FSImageFormatProtobuf: Saving image file /home/hadoop/data/hdfs/namenode/current/fsimage.ckpt_0000000000000000000 using no compression 21/04/29 00:15:55 INFO namenode.FSImageFormatProtobuf: Image file /home/hadoop/data/hdfs/namenode/current/fsimage.ckpt_0000000000000000000 of size 325 bytes saved in 0 seconds . 21/04/29 00:15:55 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 21/04/29 00:15:55 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid = 0 when meet shutdown. 21/04/29 00:15:55 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at hdoop1/192.168.56.71 ************************************************************/
5-2 Hadoop Start
이제 sbin 디렉토리에 있는 start-all.sh 쉘 스크립트를 이용하여 하둡을 기동을 하게 되면 namenode , datanode, nodemanager, secondarynamenode, yarn 데몬을 실행 시킵니다. 참고로 데몬 실행과 종료를 위한 쉘 스크립트는 sbin 디렉토리에 있습니다
hadoop$ cd $HADOOP_HOME/sbin hadoop$ ./start-all.sh This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh Starting namenodes on [hdoop1] hdoop1: starting namenode, logging to /home/hadoop/hadoop-2.10.1/logs/hadoop-hadoop-namenode-hdoop1.out hdoop4: starting datanode, logging to /home/hadoop/hadoop-2.10.1/logs/hadoop-hadoop-datanode-hdoop4.out hdoop3: starting datanode, logging to /home/hadoop/hadoop-2.10.1/logs/hadoop-hadoop-datanode-hdoop3.out hdoop2: starting datanode, logging to /home/hadoop/hadoop-2.10.1/logs/hadoop-hadoop-datanode-hdoop2.out Starting secondary namenodes [hdoop1] hdoop1: starting secondarynamenode, logging to /home/hadoop/hadoop-2.10.1/logs/hadoop-hadoop-secondarynamenode-hdoop1.out starting yarn daemons starting resourcemanager, logging to /home/hadoop/hadoop-2.10.1/logs/yarn-hadoop-resourcemanager-hdoop1.out hdoop2: starting nodemanager, logging to /home/hadoop/hadoop-2.10.1/logs/yarn-hadoop-nodemanager-hdoop2.out hdoop4: starting nodemanager, logging to /home/hadoop/hadoop-2.10.1/logs/yarn-hadoop-nodemanager-hdoop4.out hdoop3: starting nodemanager, logging to /home/hadoop/hadoop-2.10.1/logs/yarn-hadoop-nodemanager-hdoop3.out
[참조] This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
start-all.sh 스크립트는 Deprecated 로 현재는 사용가능하지만 start-dfs.sh 와 start-yarn.sh 로 대체 된 상태 입니다.
start-all.sh 대신 실행시에는 start-dfs.sh 와 start-yarn.sh 를 순서대로 실행 합니다.
• jps 조회
hadoop$ jps 3029 SecondaryNameNode 5675 Jps 2829 NameNode 5407 ResourceManager
[참고] jps 명령어는 Java Virtual Machine Process Status Tool 약자로 jvm 위에서 돌아가는 프로세스를 확인 하는 툴 입니다.
5-3 Jobhistoryserver 기동
하둡2는 얀을 위한 웹 인터페이스 외에도 맵리듀스 job의 이력만 별도로 볼수 있는 서버를 제공하고 있습니다. 하둡의 map reduce 의 job history 를 web UI 에서 볼 수 있는 19888 포트에 접속하기 위해선 job history process 를 실행시켜야 합니다.
hadoop$ cd $HADOOP_HOME/sbin hadoop$ ./mr-jobhistory-daemon.sh start historyserver starting historyserver, logging to /home/hadoop/hadoop-2.10.1/logs/mapred-hadoop-historyserver-hdoop1.out
jps 를 통해 JobHistoryServer 가 구동되어 있는지를 확인 합니다.
hadoop$ jps 5748 JobHistoryServer <--- 3029 SecondaryNameNode 5820 Jps 2829 NameNode 5407 ResourceManager
히스토리 서버는 stop-all.sh 이나 stop-yarn.sh 에서는 종료 되지 않음으로 종료시 다음과 같이 별도로 종료를 해야 합니다.
hadoop$ cd $HADOOP_HOME/sbin hadoop$ ./mr-jobhistory-daemon.sh stop historyserver
5-3 웹 프록시 기동
그 다음에는 웹 프록시 서버를 실행 합니다. 프록시 서버가 실행되고 있지 않으면 웹 인터페이스에서 애플리케이션 마스터 관련 페이지에 접근할 수 없습니다.
hadoop$ cd $HADOOP_HOME/sbin hadoop$ ./yarn-daemon.sh start proxyserver starting proxyserver, logging to /home/hadoop/hadoop-2.10.1/logs/yarn-hadoop-proxyserver-hdoop1.out hadoop$ jps 5940 Jps 3029 SecondaryNameNode 5898 WebAppProxyServer <--- 2829 NameNode 5407 ResourceManager
6. 하둡 웹 인터페이스
하둡1과 마찬가지로 하둡2에서도 여러가지 웹 인터페이스를 제공하고 있습니다.
6.1 HDFS 관리용 웹 인터페이스
웹 브라우저에서 첫번재 서버(마스터) 주소 와 함께 50070 포트로 접속을 하면 아래와 같이 접속이 되는 것을 확인 할 수 있습니다
• 접속 주소 예시 : http://hdoop1:50070
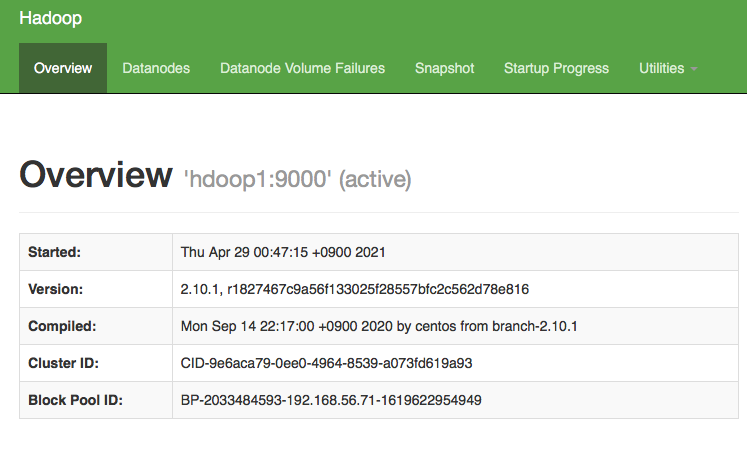
이 화면에서는 HDFS 사용 통계 정보, 데이터 노드 상태 정보, 스냅샷 생성 현황, 네임노드 실행 진행 상태, HDFS 저장 데이터 및 로그 조회와 같은 기능을 실행할 수 있습니다
위와 같이 NameNode 정보 웹페이지가 표시되고 HDFS 정보가 정확하다면 정상적으로 HDFS가 구동된 것입니다
6.2 yarn을 위한 웹 인터페이스
하둡2에서는 얀을 위해 웹 인터페이스도 제공 합니다. 이 화면에서는 얀 클러스터 자원 현황, 얀 클러스터에서 실행되는 어플리케이션의 모니터링, 스케줄러 정보 등 얀과 관련된 정보가 제공 됩니다.
• 접속 주소 예시 : http://hdoop1:8088
6.3 히스토리 서버 웹 인터페이스
웹 브라우저에서 19888 포트로 접속을 하면 아래와 같이 접속이 되는 것을 확인 할 수 있습니다. 얀 클러스터에서 실행된 맵리듀스 Job 이력만을 제공 합니다
• 접속 주소 예시 : http://hdoop1:19888

여기 까지 하둡 2.10.1 버전 설치에 관하여 진행된 내역을 정리하였습니다.
※ Ref : 시작하세요! 하둡 프로그래밍(개정 2판) 책의 내용을 정리한 포스팅 입니다

이전 글
다음 글

Principal DBA(MySQL, AWS Aurora, Oracle)
핀테크 서비스인 핀다에서 데이터베이스를 운영하고 있어요(at finda.co.kr)
Previous - 당근마켓, 위메프, Oracle Korea ACS / Fedora Kor UserGroup 운영중
Database 외에도 NoSQL , Linux , Python, Cloud, Http/PHP CGI 등에도 관심이 있습니다
purityboy83@gmail.com / admin@hoing.io