









Last Updated on 4월 26, 2023 by Jade(정현호)
안녕하세요
이번글은 Redis의 데이터 타입과 데이터 타입별 데이터에 대한 입력 및 제어, 삭제 등에 대해서 튜토리얼 형식으로 확인 해 보도록 하겠습니다.
Redis Data Structures
Redis는 다양한 인 메모리 데이터 구조 집합(collection)을 제공 하므로 다양한 사용자 정의 애플리케이션을 손쉽게 사용할 수 있습니다.
![]()
Redis 는 다양한 인 메모리 데이터 구조 집합을 제공 하므로 다양한 사용자 정의 애플리케이션을 손쉽게 사용할 수 있습니다.
Redis 주로 데이터베이스, 캐싱, 세션 관리, message broker 서비스로 stream 와 Pub/Sub 및 랭킹 서비스(Ranking Board), 대기열(queue) 등 다양한 기능으로 사용하고 있습니다.
Redis는 현재 가장 인기 있는 인메모리 Key-Value(키 값) 데이터 스토어로서, BSD 라이선스 이며, 최적화된 C 코드로 작성 되었으며, 다양한 개발 언어를 지원합니다
Redis에서는 다양한 데이터 구조(Data Structures/Collection)를 제공합니다.
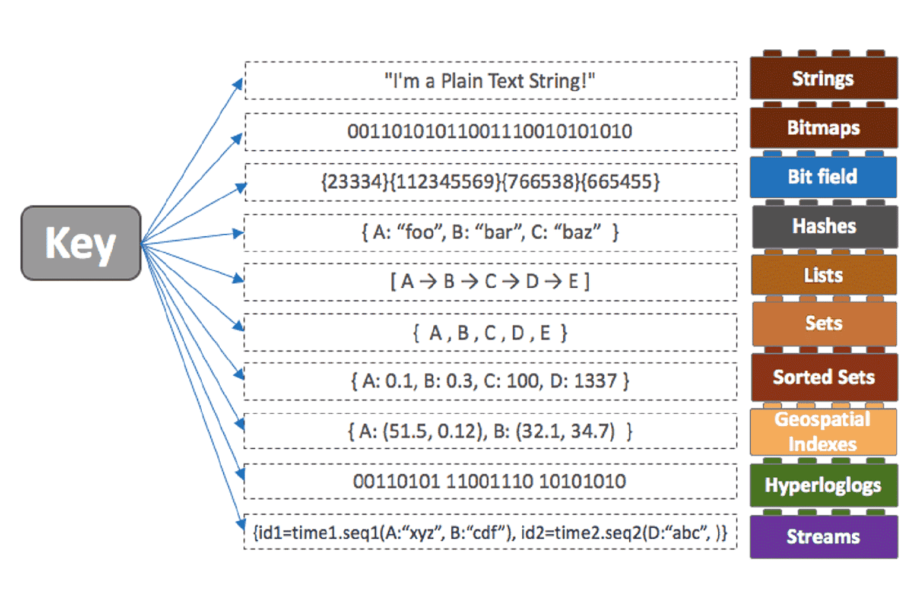
- Strings / Lists / Sets
- Sorted Sets / Hashes
- Bitmaps / Bit filed /HyperLogLogs
- Streams / Geospatial
다양한 데이터 구조를 지원하는 함으로써 Redis는 다양한 용도로 사용 되고 있습니다.
Redis Key
Redis의 key는 binary safe 입니다. 이는 key로 어떤 binary sequence도 사용할 수 있다는 것을 의미합니다.
이것은 "foo"와 같은 문자열에서 부터 JPEG 파일의 내용에 이르기까지 모든 binary sequence를 key로 사용할 수 있음을 의미합니다.
빈 문자열도 유효한 키입니다.
Redis Key에 대한 몇 가지 규칙 있습니다.
-
매우 긴 키는 좋은 생각이 아닙니다. 예를 들어 1024바이트의 Key는 메모리 측면에서뿐만 아니라, 데이터 집합에서 Key를 조회하려면 비용이 많이 드는 몇 가지 Key 비교가 필요할 수 있습니다.
큰 값의 존재와 확인 경우에도 특히 메모리 및 대역폭의 관점에서 해시(예: SHA1)하는 것이 더 나은 방법입니다. -
매우 짧은 키는 종종 좋은 아이디어가 아닙니다. "u1000flw"와 같은 키를 작성하는 대신 "user:1000:followers"와 같이 작성하는 것이 더 가독성이 좋으며, 추가된 공백은 키 객체와 값 객체에 사용되는 공간에 비해 미미합니다. 짧은 키는 메모리를 약간 덜 사용하겠지만, 올바른 균형을 찾는 것이 중요합니다.
-
스키마를 일관되게 사용하는 것이 좋습니다. 예를 들어 "user:1000"과 같이 "object-type:id" 형식을 사용하는 것이 좋습니다. 여러 단어 필드에는 점(.)이나 대시(-)를 사용하는 것이 일반적입니다. 예를 들어 "comment:4321:reply.to"나 "comment:4321:reply-to"와 같이 사용합니다.
-
최대 허용 키 크기는 512MB입니다.
String
String 타입은 Redis 키와 연결할 수 있는 가장 간단한 값 타입입니다. Memcached에서도 유일한 데이터 타입이기 때문에 Redis를 처음 사용하는 사람들도 쉽게 사용할 수 있습니다.
Redis 키는 문자열이므로, 값으로 문자열 타입을 사용하면 문자열을 다른 문자열에 매핑하는 것입니다. 문자열 데이터 타입은 HTML 조각 또는 페이지 캐싱과 같은 여러 사용 사례에 유용합니다.

이제 부터 redis-cli를 사용하여 데이터 타입에 대해서 조금 더 자세히 살펴보겠습니다.
Redis에서는 쿼리나 언어라고 대신에 명령어(command) 라고 하며 사용하는 데이터 타입에 따라서 사용하는 명령어가 분류 되어 있습니다.
아래 Commands 도큐먼트에서 확인 할 수 있으며, 링크 사이트에서 확인 해보시면 아주 많은 명령어가 있는 것을 확인 하실 수 있습니다.
"Filter by group" 에서 데이터 타입 등을 선택하면 해당 타입에 사용할 수 있는 커맨트만 필터하여 확인 할 수 있습니다.
다음은 String 데이터 타입에서 사용 가능 명령어 입니다.
- APPEND
- DECR
- DECRBY
- GET
- GETDEL
- GETEX
- GETRANGE
- GETSET
- INCR
- INCRBY
- INCRBYFLOAT
- LCS
- MGET
- MSET
- MSETNX
- PSETEX
- SET
- SETEX
- SETNX
- SETRANGE
- STRLEN
- SUBSTR
이와 같이 많은 수의 명령어가 있습니다. 포스팅에서 다루지 않은 명령어에 대한 내용은 위의 Commands 도큐먼트에서 확인 할 수 있습니다.
> set mykey somevalue OK > get mykey "somevalue"
새로운 데이터를 입력할 때 SET 명령어을 통해서 하며, 이미 키와 연결된 값이 있으면, SET 명령어는 해당 값을 대체합니다.
이때, 키가 문자열이 아닌 다른 데이터 타입과 연결되어 있더라도 SET 명령어는 새로운 값을 할당합니다.
최대 512MB 까지 가능하며, 값으로 모든 종류의 문자열(바이너리 데이터 포함)을 사용할 수 있으며, 예를 들어 JPEG 이미지를 값으로 저장할 수도 있습니다.
SET 명령어에는 추가 인수를 사용할 수 있으며 여러가지 옵션이 있습니다.
예를 들어, nx 는 키가 없는 경우에만 입력 할 수 있으며 키가 이미 존재하면 SET이 실패하게 됩니다.
xx 는 키가 이미 있는 경우에만 입력 하게 되며, 키가 존재 하지 않으면 입력되지 않습니다.
> set mykey newval nx OK > set mykey newval nx (nil) > del mykey # 테스트를 위해 삭제 (integer) 1 > set mykey newval xx (nil)
String 데이터 타입에서 문자열로 수행할 수 있는 흥미로운 작업이 있습니다. 예를 들어, atomic increment 기능을 다음과 같이 수행 할 수 있습니다.
> set counter 100 OK > incr counter (integer) 101 > incr counter (integer) 102 > incrby counter 50 (integer) 152
INCR 명령어는 문자열 값을 정수로 구문 분석하고, 1을 증가시킨 다음 새로운 값을 설정합니다. INCRBY, DECR 및 DECRBY와 같은 다른 비슷한 명령어도 있습니다.
내부적으로는 항상 동일한 명령어이지만, 약간 다른 방식으로 작동합니다.
문자열을 조작하기 위한 여러 명령어가 있습니다. 예를 들어, GETSET 명령어는 새 값을 설정하고 이전 값을 결과로 반환하여 키를 설정합니다.
예를 들어, Redis 키를 INCR을 사용하여 새로운 방문자가 웹 사이트를 방문할 때마다 증가시키는 시스템이 있다면, 이 정보를 한 시간에 한 번 수집하고 증분을 하나도 놓치지 않고 싶을 수 있습니다.
GETSET 명령어를 사용하여 키를 "0"의 새 값으로 할당하고 이전 값을 다시 읽을 수 있습니다.
단일 명령에서 여러 키의 값을 설정하거나 검색하는 기능도 지연 시간을 줄이는 데 유용합니다. 이럴때는 MSET 및 MGET 명령어를 사용 합니다.
> mset a 10 b 20 c 30 OK > mget a b c 1) "10" 2) "20" 3) "30"
특정 타입에 대해 정의되어 있지 않은 명령어들도 있습니다. 이러한 명령어들은 키 상호 작용하기 위해 유용하며, 따라서 모든 유형의 키와 함께 사용할 수 있습니다.
예를 들어, EXISTS 명령어는 데이터베이스에 지정된 키가 존재하는지 여부를 나타내는 1 또는 0을 반환하며, DEL 명령어는 값의 유형과 상관없이 키를 삭제 합니다.
> set mykey hello OK > exists mykey (integer) 1 > del mykey (integer) 1 > exists mykey (integer) 0
TYPE 명령어는 저장된 값의 종류 정보를 반환하는 명령어 입니다.
> set mykey x OK > type mykey string > del mykey (integer) 1 > type mykey none
Lists
리스트(List)는 쓰이는 형태나 방법, 보이는(출력되는) 부분이 배열로 보일 수 있습니다.
다만 Redis의 리스트(List) 데이터 타입에 대해 조금 더 자세하게 설명하기 위해서는, 약간의 이론적인 내용을 시작하는 것이 좋을 것 같습니다.
예를 들어 "파이썬 리스트"는 이름이 시사하는 것과 같은 링크드 리스트(linked list)가 아니라 배열(Array)입니다 (실제로 루비(Ruby)에서는 동일한 데이터 타입을 Array라고 부릅니다).
매우 일반적인 관점에서, 리스트는 그저 순서대로 정렬된 요소(elements)의 시퀀스입니다.
10,20,1,2,3 은 리스트입니다.
그러나 배열(Array)을 사용하여 구현된 리스트의 속성은 링크드 리스트를 사용하여 구현된 리스트의 속성과 매우 다릅니다.
즉, Array로 구현된 리스트 속성 != linked list 속성
Redis의 list 데이터 타입은 linked list를 통해 구현됩니다. 따라서 list 안에 수백만 개의 요소가 있다 하더라도, list의 맨 앞이나 맨 뒤에 새로운 요소를 추가하는 작업은 일정한 시간 내에 수행됩니다.
따라서, LPUSH 명령을 사용하여 10개의 요소가 있는 list의 맨 앞에 요소를 추가하는 속도와 1000만 개의 요소가 있는 list의 맨 앞에 요소를 추가하는 속도는 동일합니다.
장점에 비해 단점은 무엇일까요? 배열을 사용하여 구현한 목록에서는 인덱스로 요소(elements)에 빠르게 접근할 수 있습니다(constant time indexed access)
그러나 링크드 리스트로 구현된 목록에서는 요소에 접근하기 위한 작업량이 인덱스에 비해 상대적으로 비례하여 증가하기 때문에(선형 시간 색인 액세스) 덜 빠릅니다.
Redis의 List는 매우 긴 목록에 요소를 매우 빠르게 추가할 수 있어야 하는 데이터베이스 시스템에서는 linked list로 구현됩니다.
또 다른 강력한 이점으로는 Redis List가 일정한 길이로 일정한 시간 안에 가져올 수 있다는 점이 있습니다.
List 데이터 타입에서 사용할 수 있는 명령어 목록 입니다.
- BLMOVE
- BLMPOP
- BLPOP
- BRPOP
- BRPOPLPUSH
- LINDEX : 리스트 키에 저장된 인덱스 요소값을 반환하며, 0은 첫번재 1은 두번째를 의미 합니다
-1은 뒤에서 첫번째, -2는 뒤에서 두번째를 의미 합니다. - LINSERT
- LLEN
- LMOVE
- LMPOP
- LPOP : 리스트 키에 저장된 목록의 첫 번째 요소를 제거하고 반환
- LPOS
- LPUSH
- LPUSHX
- LRANGE : list형식으로 저장된 키의 값을 개수를 인덱스를 지정하여 조회함. 음수의 경우일 경우는 마지막 값을 의미
-1 은 마지막 값, -2 마지막에서 2번째 값, -3 마지막에서 3번째 값 - LREM : 리스트내 요소를 삭제함
- LSET
- LTRIM
- RPOP : 리스트 키에 저장된 목록의 마지막 요소를 제거하고 반환
- RPOPLPUSH
- RPUSH : 지정된 모든 값을 키에 저장된 목록의 끝(오른쪽)에 입력
- RPUSHX
LPUSH 명령어는 리스트의 왼쪽 (맨 앞)에 새 요소(element)를 추가하고, RPUSH 명령어는 리스트의 오른쪽 (맨 끝)에 새 요소(element)를 추가합니다.
LRANGE 명령어는 리스트에서 요소의 범위를 추출합니다.
> rpush mylist A (integer) 1 > rpush mylist B (integer) 2 > lpush mylist first (integer) 3 > lrange mylist 0 -1 1) "first" 2) "A" 3) "B"
LRANGE 명령어는 반환할 범위의 첫 번째와 마지막 요소를 나타내는 두 개의 인덱스를 가져옵니다.
두 인덱스 모두 음수일 수 있으며, Redis에게 끝에서부터 계산하도록 지시할 수도 있습니다.
따라서 -1은 리스트의 마지막 요소(element)이고, -2는 마지막에서 두 번째 요소가 됩니다.
그래서 0 -1 는 처음 부터 끝까지 출력을 의미 합니다.
lpush 와 rpush는 가변 인자 명령어이며, 한 번의 호출로 여러 원소를 리스트에 추가할 수 있습니다.
> rpush mylist 1 2 3 4 5 "foo bar" (integer) 9 > lrange mylist 0 -1 1) "first" 2) "A" 3) "B" 4) "1" 5) "2" 6) "3" 7) "4" 8) "5" 9) "foo bar"
Redis 리스트에서 중요한 작업 중 하나는 원소를 팝(pop)하는 기능입니다.
팝(pop) 작업은 리스트에서 원소를 가져오고 동시에 리스트에서 제거하는 작업입니다.
리스트의 양쪽에서 원소를 팝(pop)할 수 있으며, 마찬가지로 양쪽에서 원소를 푸시(push)할 수 있는 것과 유사합니다.
> del mylist # 테스트를 위해 키를 삭제 > rpush mylist a b c (integer) 3 > rpop mylist "c" > rpop mylist "b" > rpop mylist "a" > rpop mylist (nil)
비어 있는 list에 대해서 마지막으로 한번 더 pop 을 수행하면 null 이 회신 됩니다.
Redis는 List에 element가 비어있다면 null 을 회신합니다.
위의 상황 같이 Lists 에서 element를 제거할 때 모두 제거하여 값이 비어 있으면(null을 회신 받았다면) 키는 자동으로 삭제됩니다.
> exists mylist (integer) 0 <!!-- 존재 하지 않음
리스트내에서 특정 element를 삭제하고자 할 때에는 lrem 을 사용 합니다.
> LREM key count element
명령어를 위와 같이 수행하며 세번째 인수 count에서 양수를 지정하면 앞에서 부터 지정한 수만큼 삭제하고, 음수로 입력하면 뒤에서 부터 그 수 만큼을 삭제하게 됩니다.
> rpush mylist "hello" (integer) 1 > rpush mylist "hello" (integer) 2 > rpush mylist "foo" (integer) 3 > rpush mylist "hello" (integer) 4 > rpush mylist "foo" (integer) 5 > lrange mylist 0 -1 1) "hello" 2) "hello" 3) "foo" 4) "hello" 5) "foo" > lrem mylist 1 "hello" (integer) 1 > lrange mylist 0 -1 1) "hello" 2) "foo" 3) "hello" 4) "foo" > rpush mylist "hello" (integer) 5 > rpush mylist "hello" (integer) 6 > lrange mylist 0 -1 1) "hello" 2) "foo" 3) "hello" 4) "foo" 5) "hello" 6) "hello" > lrem mylist -2 "hello" (integer) 2 > lrange mylist 0 -1 1) "hello" 2) "foo" 3) "hello" 4) "foo" > lrem mylist 1 "foo" (integer) 1 > lrange mylist 0 -1 1) "hello" 2) "hello" 3) "foo"
0은 지정한 element 모두를 삭제 합니다.
> lrange mylist 0 -1 1) "hello" 2) "hello" 3) "foo" > lrem mylist 0 "hello" (integer) 2 > lrange mylist 0 -1 1) "foo"
Hashes
Redis 에서 하나의 Key에 여러 Value의 저장이 필요할 경우 Hash 데이터 타입을 사용할 수 있습니다.
Hash 데이터 타입은 하나의 Key에 하나 이상의(여러개의) Field 와 Value로 구성하여 사용 합니다.

해시(hash)는 가변적(mutable)이므로 초기 선언시 에만이 아니라 언제든지 Field-Value pairs을 추가, 변경, 증가 또는 제거할 수 있습니다.
Redis 해시는 필드 값들을 문자열로 저장하기 때문에 평면적(flat)이며 중첩된 배열이나 객체는 없습니다.
Redis 해시의 필드 이름은 미리 정의할 필요가 없으며, 필요에 따라 필드를 추가하거나 제거할 수 있습니다.
Redis 해시는 스키마리스(schemeless) 형태로 구성되어 있지만, 관계형 데이터베이스 테이블의 경량 객체 또는 행(row)으로 생각할 수 있습니다.
해시는 최대 4,294,967,295(2^32 - 1)개의 필드-값 쌍을 저장할 수 있습니다.
Hash 에서 사용 가능한 명령어는 다음과 같습니다.
- HDEL
- HEXISTS
- HGET
- HGETALL
- HINCRBY
- HINCRBYFLOAT
- HKEYS
- HLEN
- HMGET
- HMSET
- HRANDFIELD
- HSCAN
- HSET
- HSETNX
- HSTRLEN
- HVALS
Hash에서 사용되는 기본 제어 명령어인 hset,hget 등에 예시를 살펴보도록 하겠습니다.
> hset user:1000 username antirez birthyear 1977 verified 1 (integer) 3 > hget user:1000 username "antirez" > hget user:1000 birthyear "1977" > hgetall user:1000 1) "username" 2) "antirez" 3) "birthyear" 4) "1977" 5) "verified" 6) "1"
위의 예제에서는 일반적으로 사용되는 Redis키(key) 네이밍 컨벤션(naming convention)을 사용하고 있습니다.
"user"라는 단어로 시작하여 저장하는 항목의 유형(type)을 의미하게 됩니다. 그 다음에는 콜론(:)과 이 id를 기재하였습니다.
다음은 콜론(:) 뒤에 값을 바꿔서 다른 user 를 저장하는 유형의 예제입니다.
> hset user:1001 username michael birthyear 1965 verified 1 (integer) 3 > hget user:1001 username "michael" > hget user:1001 "1965" > hgetall user:1001 1) "username" 2) "michael" 3) "birthyear" 4) "1965" 5) "verified" 6) "1"
hset 명령은 Hash의 여러 필드를 설정하는 반면 hget은 단일 필드를 검색합니다.
hmget은 hget과 비슷하지만 값 배열을 반환합니다
• hmget
> hmget user:1000 username birthyear 1) "antirez" 2) "1977"
• hget
> hget user:1000 username "antirez"
hincrby와 같이 개별 필드에서 작업을 수행할 수 있는 명령어도 있습니다.
hincrby는 저장된 값(숫)를 증가 시킵니다.
> hget user:1000 birthyear "1977" > hincrby user:1000 birthyear 10 (integer) 1987 > hincrby user:1000 birthyear 10 (integer) 1997
지원하는 값의 범위는 부호 있는 64비트 정수로 제한됩니다.
앞에 - 부호를 사용하면 감소가 됩니다.
> hincrby user:1000 birthyear -10 (integer) 1987 > hincrby user:1000 birthyear -10 (integer) 1977
Hash 데이터 타입은 언제든지 삭제 및 추가가 가능합니다.
hdel 명령어를 통해서 지정한 특정 field를 삭제할 수 있습니다.
> hdel user:1000 birthyear # birthyear 필드를 삭제 합니다. (integer) 1 > hgetall user:1000 1) "username" 2) "antirez" 3) "verified" 4) "1" > hmset user:1000 birthyear 1977 # 다시 추가 합니다. OK > hgetall user:1000 1) "username" 2) "antirez" 3) "verified" 4) "1" 5) "birthyear" 6) "1977"
Sets
Set은 순서가 지정되지 않은(정렬되지 않은), 중복 되지 않은 고유 문자열(구성원) 집합입니다.
Set을 사용하면 다음 작업을 효율적으로 수행할 수 있습니다
- 고유한 항목 추적 (예: 특정 블로그 게시물에 접근하는 모든 고유한 IP 주소 추적)
- 관계 표현 (예: 특정 역할을 가진 모든 사용자의 집합)
- 교집합, 합집합 및 차집합과 같은 일반적인 집합 연산 수행
다음은 Sets 데이터 타입에서 사용할 수 있는 명령어 입니다.
- SADD : 집합을 새로 생성하거나 기존키에 멤버를 추가
- SCARD : 집합에 속해 있는 멤버의 수(count) 를 구함
- SDIFF : 차집합을 구함
- SDIFFSTORE
- SINTER : 교집합을 구함
- SINTERCARD
- SINTERSTORE
- SISMEMBER
- SMEMBERS
- SMISMEMBER
- SMOVE
- SPOP : 집합에서 랜덤하게 member를 추출
- SRANDMEMBER : 집합에서 랜덤하게 member를 조회
- SREM : 집합 내 멤버를 삭제
- SSCAN
- SUNION : 합집합을 구함, DB의 UNION과 같음
- SUNIONSTORE : 여러 집합 사이에서 합집합을 수행하고 결과를 다른 집합으로 저장
SADD 명령어를 통해 새로운 요소를 세트(set)에 추가할 수 있습니다. 또한 sets에 대해 다른 몇 가지 작업을 수행할 수도 있습니다.
예를 들어, 주어진 요소가 이미 있는지 확인하거나, 여러 세트 간의 교집합, 합집합 또는 차집합을 수행하는 것과 같은 작업이 가능합니다.
> sadd myset 3 1 2 (integer) 3 > smembers myset 1) "1" 2) "2" 3) "3" > scard myset (integer) 3
위에서는 3개의 elements를 set에 추가하고, elements를 모두 출력 하였습니다.
예상과는 다르게 정렬된 결과가 출력되었습니다.
일반적으로 Set 데이터타입의 집합의 요소의 순서는 신뢰할 수 없습니다. 특정한 순서로 원한다면, 리스트나 Sorted set을 사용해야 합니다.
Set(집합)이 충분히 빫은 경우(아래에서 설명), Redis는 Set을 정렬된 정수 배열 또는 intset 으로 저장 합니다.
정렬된 배열로 Set 을 저장함으로써 오버헤드를 낮출 뿐만 아니라 표준 SET 연산을 빠르게 수행할 수 있습니다.
SET에서 intset 사용 제한 값은 set-max-intset-entries 에서 확인 할 수 있으며 기본값은 512개 입니다.
설정된 512개 이전에는 inset 으로 encoding 되며, 항목이 512개를 초과하면 hashtable로 표현 됩니다.
이와 같이 Sets 데이터타입은 정렬되지 않은 고유의 값의 집합 이라는 속성이 일반적이기 때문에 출력시에 element 순서를 자유롭게 결정될 수 있으며, 특정 순서로 원한다면 리스트나 Sorted set을 사용해야 합니다.
scard 명령어는 집합내의 elements 수, 즉 저장된 값을 갯수를 출력 합니다.
다음은 Set내에서 데이터가 있는지, element을 확인하는 명령어 예시 입니다.
> sismember myset 3 (integer) 1 > sismember myset 30 (integer) 0
3은 멤버이고, 30은 멤버가 아닙니다.(존재하지 않음)
Sets 데이터 타입은 고유한 값을 저장 합니다.
> SADD user:123:favorites 561 (integer) 1 > SADD user:123:favorites 347 (integer) 1 > SADD user:123:favorites 742 (integer) 1 > SADD user:456:favorites 561 (integer) 1 > smembers user:123:favorites 1) "347" 2) "561" 3) "742"
위에서 user:123:favorites 입력시 561 값을 두번 입력하였지만, 중복이 허용지 않기 때문에 값 561은 한번 출력 되게 됩니다.
만약 123 유저와 456 유저가 공통적으로 좋아하는 책이 있는지를 확인 이라는 요건 처럼 공통된 정보, 즉 교집합을 구할 때는 SINTER 를 명령어를 사용 합니다.
> SINTER user:123:favorites user:456:favorites 1) "561"
차집합과 합집합도 수행할 수 있으며 SDIFF와 SUNION을 이용 합니다.
## 차집합 > SDIFF user:123:favorites user:456:favorites 1) "347" 2) "742" ## 합집합 > SUNION user:123:favorites user:456:favorites 1) "347" 2) "561" 3) "742"
집합에서 특정 element(멤버)를 추출하는 명령어는 SPOP 을 사용 합니다. 예를 들어 포커 게임을 구현하기 위해서 deck(덱)을 집합으로 구현하였을때, 각 플레이어에게 5장씩을 랜덤하게 제공한다고 가정하겠습니다.
> sadd deck C1 C2 C3 C4 C5 C6 C7 C8 C9 C10 CJ CQ CK D1 D2 D3 D4 D5 D6 D7 D8 D9 D10 DJ DQ DK H1 H2 H3 H4 H5 H6 H7 H8 H9 H10 HJ HQ HK S1 S2 S3 S4 S5 S6 S7 S8 S9 S10 SJ SQ SK ** 가로 길이가 길어서 개행되어 있습니다. ** 실제 입력시에는 한줄로 입력 합니다.
SPOP 커맨드는 무작위로 element를 제거하고 반환하는 명령이므로 이 경우에 사용할 수 있는 적절한 명령어 입니다.
그러나 덱에 직접 SPOP적용하면 다음 게임 플레이에서 다시 카드 덱을 채워야 할 수 있으므로, 먼저 덱 키에 저장된 세트의 사본을 game:1:deck 키에 만들도록 하겠습니다.
이렇게 집합의 별도 사본 저장을 할 때는 SUNIONSTORE를 사용할 수 있습니다.
SUNIONSTORE는 일반적으로 여러 집합 사이에서 합집합을 수행하고 결과를 다른 집합에 저장하지만, 단일 집합의 합집합은 그 자체가 집합임으로 다른 집합으로 저장할 수 있습니다.
사용법은 sunionstore 커맨드는 "sunionstore 저장될_키이름 소스_키1 소스_키2" 와 같이 사용 합니다.
> sunionstore game:1:deck deck (integer) 52
deck 집합을 game:1:deck 으로 저장하였습니다.
다음과 같이 5개의 카드를 램덤하게 추출하여 플레이어에게 제공할 수 있습니다.
> spop game:1:deck "S2" > spop game:1:deck "H10" > spop game:1:deck "C5" > spop game:1:deck "H9" > spop game:1:deck "C9" > scard game:1:deck (integer) 47
5장의 카드(element)를 SPOP 을 통해서 추출하여 플레이어에게 제공되었기 때문에 scard 로 조회했을때 남은 카드(element)가 47 이라는 것을 확인 할 수 있습니다.
SRANDMEMBER 명령어는 집합에서 요소(element)를 제거하지 않고 무작위로 가져올 때 사용됩니다. 이 명령어는 SPOP과 달리 가져오면서 제거 하지 않기 때문에 element를 가져올 때 이전에 출력된 값이 동일하게 나올 수도 있습니다.
물론 무작위로 추출되기 때문에 동일한 값이 나오지 않을수도 있습니다.
> SRANDMEMBER game:1:deck "H1" > SRANDMEMBER game:1:deck "HK" > SRANDMEMBER game:1:deck "HK" > SRANDMEMBER game:1:deck "C8" > SRANDMEMBER game:1:deck "SK" > scard game:1:deck (integer) 47
SRANDMEMBER는 값을 가져온 후 제거 하지 않음으로 집합내 element 수는 기존과 동일하게 47인것을 확인 할 수 있습니다.
Sorted sets
Sorted sets은 연관된 스코어에 의해 정렬되는 고유한 문자열(members)의 컬렉션입니다.
Sorted sets은 Set과 Hash가 혼합된 형태의 데이터 타입입니다.
Set과 같이 정렬된 집합은 유일하고(중복되지 않고) 반복되지 않는 문자열 요소로 구성됩니다. 그러므로 일종의 set과도 유사합니다.

SETS 안의 element들은 정렬되어 있지 않지만, Sorted sets의 모든 element들은 부동 소수점 값(floating point value)을 가지는 점수(score)에 따라서 정렬됩니다.
정렬된 집합의 elements는 순서대로 처리(조회 등) 됩니다.
하나 이상의 문자열이 동일한 점수를 가지는 경우, 문자열은 사전식으로 정렬됩니다.
- B와 A가 서로 다른 점수를 가진 두 요소라면, A.score가 B.score보다 크면 A>B 입니다.
- B와 A가 정확히 동일한 점수를 가진 경우, A 문자열이 B 문자열보다 사전식으로 크면 A>B입니다.
- Sorted sets은 고유한 요소만 갖기 때문에, B와 A 문자열은 동일할 수 없습니다.
Sorted Set을 사용하는 몇 가지 예시는 다음과 같습니다.
- 리더보드(Leaderboards): 예를 들어, Sorted Set을 사용하여 대규모 온라인 게임에서 가장 높은 점수를 가진 사용자의 정렬된 목록을 쉽게 유지할 수 있습니다.
- 비율 제한(Rate limiters): 특히, Sorted Set을 사용하여 sliding-window rate limiter를 구축하여 과도한 API 요청을 방지할 수 있습니다.
다음은 Sorted sets 에서 사용 가능한 명령어 입니다.
- BZMPOP
- BZPOPMAX
- BZPOPMIN
- ZADD : 집합에 score 와 멤버를 추가
- ZCARD : 집합에 속한 멤버의 수를 카운트함
- ZCOUNT : score 통한 범위를 지정한 갯수 카운트
- ZDIFF
- ZDIFFSTORE
- ZINCRBY
- ZINTER
- ZINTERCARD
- ZINTERSTORE
- ZLEXCOUNT
- ZMPOP
- ZMSCORE
- ZPOPMAX
- ZPOPMIN
- ZRANDMEMBER
- ZRANGE
- ZRANGEBYLEX
- ZRANGEBYSCORE
- ZRANGESTORE
- ZRANK
- ZREM
- ZREMRANGEBYLEX
- ZREMRANGEBYRANK
- ZREMRANGEBYSCORE
ZREVRANGE - ZREVRANGEBYLEX
- ZREVRANGEBYSCORE
- ZREVRANK
- ZSCAN
- ZSCORE
- ZUNION
- ZUNIONSTORE
간단한 예시로, 일부 해커 이름을 선택하여 정렬된 집합 요소로 추가하고, 그 해커들의 출생년도를 "score"로 사용해보겠습니다.
> zadd hackers 1940 "Alan Kay" (integer) 1 > zadd hackers 1957 "Sophie Wilson" (integer) 1 > zadd hackers 1953 "Richard Stallman" (integer) 1 > zadd hackers 1949 "Anita Borg" (integer) 1 > zadd hackers 1965 "Yukihiro Matsumoto" (integer) 1 > zadd hackers 1914 "Hedy Lamarr" (integer) 1 > zadd hackers 1916 "Claude Shannon" (integer) 1 > zadd hackers 1969 "Linus Torvalds" (integer) 1 > zadd hackers 1912 "Alan Turing" (integer) 1
ZADD는 SADD와 비슷하지만, 추가할 요소 앞에 오는 것이 점수(score)를 추가적인 인자로 받습니다.
ZADD는 가변 인자(variadic)이기 때문에, 여러 개의 score-value 쌍을 지정할 수도 있습니다.
Sorted sets을 사용하면 해커들의 출생 연도에 따라 정렬된 목록을 쉽게 반환할 수 있습니다. 사실 이미 정렬된 상태이기 때문입니다.
Implementation note: Sorted sets은 스킵 리스트와 해시 테이블을 모두 포함하는 dual-ported 데이터 구조를 사용하여 구현되므로, element를 추가할 때마다 Redis는 O(log(N)) 작업을 수행합니다.
이것은 성능에 좋은 것이며, 정렬된 element를 요청할 때 Redis는 추가 작업을 수행할 필요가 없습니다. 이미 모두 정렬된 상태입니다.
> zrange hackers 0 -1 1) "Alan Turing" 2) "Hedy Lamarr" 3) "Claude Shannon" 4) "Alan Kay" 5) "Anita Borg" 6) "Richard Stallman" 7) "Sophie Wilson" 8) "Yukihiro Matsumoto" 9) "Linus Torvalds"
0 -1은 첫 번째 요소부터 마지막 요소까지의 인덱스를 의미합니다. (LRANGE 명령어와 마찬가지로 여기서도 -1은 마지막 요소를 나타냅니다.)
역순으로 출력하려면 ZREVRANGE을 사용 합니다.
> zrevrange hackers 0 -1 1) "Linus Torvalds" 2) "Yukihiro Matsumoto" 3) "Sophie Wilson" 4) "Richard Stallman" 5) "Anita Borg" 6) "Alan Kay" 7) "Claude Shannon" 8) "Hedy Lamarr" 9) "Alan Turing"
zrange을 통해서도 가능하며 REV 인자를 추가해서 사용할 수 있습니다.
> zrange hackers 0 -1 rev 1) "Linus Torvalds" 2) "Yukihiro Matsumoto" 3) "Sophie Wilson" 4) "Richard Stallman" 5) "Anita Borg" 6) "Alan Kay" 7) "Claude Shannon" 8) "Hedy Lamarr" 9) "Alan Turing"
score 와 같이 출력되길 원한다면 WITHSCORES 인자를 추가로 사용 합니다.
> zrange hackers 0 -1 withscores 1) "Alan Turing" 2) "1912" 3) "Hedy Lamarr" 4) "1914" 5) "Claude Shannon" 6) "1916" 7) "Alan Kay" 8) "1940" 9) "Anita Borg" 10) "1949" 11) "Richard Stallman" 12) "1953" 13) "Sophie Wilson" 14) "1957" 15) "Yukihiro Matsumoto" 16) "1965" 17) "Linus Torvalds" 18) "1969"
위의 예제를 복합적으로 사용하여 집합에서 출생년도가 늦은(나이가 어린) Top3 을 구하려고 한다면 다음과 같이 사용 합니다.
> zrange hackers 0 2 rev withscores 1) "Linus Torvalds" 2) "1969" 3) "Yukihiro Matsumoto" 4) "1965" 5) "Sophie Wilson" 6) "1957" 또는 zrevrange hackers 0 2 withscores 1) "Linus Torvalds" 2) "1969" 3) "Yukihiro Matsumoto" 4) "1965" 5) "Sophie Wilson" 6) "1957"
다만, zrevrange 명령어는 Redis Version 6.2.0 버전 부터 Deprecated 되었으며, zrange 명령어에서 rev 인자를 추가하여 사용하는 것으로 대체 되었습니다.
Sorted sets은 범위를 조작할 수 있습니다. 예를 들어 1950년 이전에 태어난 모든 사람을 가져오겠습니다. 이때 ZRANGEBYSCORE 명령을 사용합니다
> zrangebyscore hackers -inf 1950 1) "Alan Turing" 2) "Hedy Lamarr" 3) "Claude Shannon" 4) "Alan Kay" 5) "Anita Borg"
zrangebyscore 명령어는 Redis Version 6.2.0 버전 부터 Deprecated 되었으며, zrange 명령어에서 byscore 인자를 추가하여 사용하는 것으로 대체 되었습니다.
> zrange hackers -inf 1950 byscore 1) "Alan Turing" 2) "Hedy Lamarr" 3) "Claude Shannon" 4) "Alan Kay" 5) "Anita Borg"
<start>와 <stop>은 각각 음의 무한대와 양의 무한대를 나타내는 -inf와 +inf 를 사용할 수 있습니다.
즉, 모든 element를 특정 점수에서 또는 특정 점수까지 가져오기 위해 정렬된 집합에서 가장 높은 점수 또는 가장 낮은 점수를 입력해야 할때 -inf와 +inf 를 사용할 수 있습니다.
score로 범위를 지정해서 member를 삭제 할 수 있습니다.
> zremrangebyscore hackers 1940 1960 (integer) 4
주어진 조건의 score에 해당하는 멤버를 삭제하고 삭제한 건수를 return 합니다.
zrank는 입력한 요소의 순위를 확인 합니다.
> zrank hackers "Linus Torvalds" (integer) 4
ZREVRANK 명령어는 elements가 내림차순으로 정렬되는 것을 고려하여 순위를 얻기 위해 사용됩니다. 즉 descending 한 다음의 rank 입니다.
> zrevrank hackers "Linus Torvalds" (integer) 0
sorted sets의 score는 언제든지 업데이트 할 수 있습니다. ZADD 명령어는 집합에 멤버를 추가할 때 사용하지만, 기존의 멤버의 score 를 변경 할 때도 사용합니다.
> zadd hackers 2023 "Linus Torvalds" (integer) 0 > zscore hackers "Linus Torvalds" "2023"
이미 sorted set에 포함된 요소에 대해 ZADD를 호출하면 해당 멤버의 점수(및 위치)가 O(log(N)) 시간 복잡도로 업데이트됩니다. 따라서 sorted sets은 업데이트가 많은 경우에 적합합니다.
이러한 특성 때문에 일반적인 사용 사례는 리더 보드(leader boards)입니다.
사용자를 점수별로 정렬하여 상위 N 사용자와 랭크 가져오기 작업을 결합하여 리더 보드에서 상위 N 사용자 및 사용자의 랭크를 표시하는 것입니다.
Bitmaps
Bitmaps 데이터 타입은 문자열을 비트 백터(0 과 1로 표현)처럼 다룰 수 있도록 합니다. 또한 하나 이상의 문자열에 대해서 비트 연산을 수행할 수도 있습니다.

비트맵의 가장 큰 장점 중 하나는 정보를 저장할 때 공간 절약할 수 있다는 점 입니다.
문자열은 binary safe blob이며 최대 길이는 512 MB이므로 2^32개 bit 까지 사용 할 수 있습니다.(2^32 => 4,294,967,296)
비트맵 사용 사례 중 일부는 다음과 같습니다.
- 집합의 멤버가 0부터 N까지의 정수에 해당하는 경우 효율적인 집합 표현
- 파일 시스템이 권한을 저장하는 방식과 유사하게 각 비트가 특정 권한을 나타내는 객체 권한
Bitmaps 데이터타입에서 사용할 수 있는 명령어는 다음과 같습니다.
- BITCOUNT
- BITFIELD
- BITFIELD_RO
- BITOP
- BITPOS
- GETBIT
- SETBIT
비트는 SETBIT 및 GETBIT 명령을 사용하여 설정하고 검색할 수 있습니다.
> setbit key 10 1 (integer) 0 > getbit key 10 (integer) 1 > getbit key 11 (integer) 0
SETBIT 명령어는 첫 번째 인자로 비트 번호를, 두 번째 인자로 설정할 값을(1 또는 0) 받습니다. 이 명령어는 자동으로 문자열의 길이를 늘립니다.
GETBIT 명령어는 지정된 인덱스에 해당하는 비트의 값을 반환합니다. 대상 키에 저장된 문자열 길이를 벗어난 비트에 대해서는 항상 0으로 간주됩니다.
그룹 비트를 조작하는 세 가지 명령어가 있습니다
- BITOP는 다른 문자열 간에 비트 연산을 수행합니다. 제공되는 연산은 AND, OR, XOR 및 NOT 입니다.
- BITCOUNT는 1로 설정된 비트 수를 보고합니다.
- BITPOS는 문자열에서 1 또는 0으로 설정된 첫 번째 비트의 위치를 반환합니다.
Bitmaps 데이터 타입의 가장 큰 장점은 적은 저장 공간이며, 참여 여부, 유저 방문자수 카운트 등을 할 때 bit 값을 1로 변경하여 간단하고 빠르게 참여수나 방문자수를 확인 할 수 있습니다.
HyperLogLogs
HyperLogLog는 집합에서 유일한 원소의 갯수 확인하기 위해 사용하며,집합의 카디널리티를 추정하는 데이터 타입입니다. 확률론적 데이터 구조로, 완벽한 정확도 대신 효율적인(적은) 공간 활용을 제공합니다.
일반적으로 고유한 항목을 카운팅하려면 이미 체크한 항목을 중복해서 카운팅하지 않도록 기억하기 위해 카운트하려는 항목의 수에 비례하는 양의 메모리를 사용해야 합니다. 즉 대상의 값이 클수록 많은 양의 메모리를 사용하게 됩니다.
메모리를 절약하는 대신에 약간의 정밀도를 낮추어 카디널리티를 추청하며, 표준 오차가 있는 추정치가 나오게 됩니다.
Redis HyperLogLog 데이터 타입은 최대 12KB를 사용하며, 표준 오차는 0.81%입니다. 그렇기 때문에 아주 적은 메모리 사용량으로 0.81% 표준오차의 추정 카디널리티를 얻을 수 있습니다.
HyperLogLogs 데이터 타입에서 사용할 수 있는 명령어 입니다.
- PFADD
- PFCOUNT
- PFDEBUG
- PFMERGE
- PFSELFTEST
HyperLogLogs 를 사용하는 간단한 예제를 확인 해보도록 하겠습니다.
redis> PFADD hll1 foo bar zap a (integer) 1 redis> PFCOUNT hll1 (integer) 4 redis> PFADD hll2 a b c foo (integer) 1 redis> PFCOUNT hll2 (integer) 4 redis> PFMERGE hll3 hll1 hll2 "OK" redis> PFCOUNT hll3 (integer) 6
PFADD는 HyperLogLog에 항목을 추가하며, PFCOUNT는 집합의 항목 수에 대한 추정치를 반환합니다.
PFMERGE는 두 개 이상의 HyperLogLog를 하나로 결합합니다.
이번 포스팅에서는 Redis 의 데이터 타입에 대해서 튜토리얼 형식으로 확인해보았으며, 여기서 마무리 하도록 하겠습니다.
Reference
Reference URL
• redis.io/docs/data-types
• redis.io/docs/data-types/tutorial
• redis.com/glossary/redis-hashes
• redis.com/glossary/rate-limiting
• redis.com/redis-enterprise/data-structures
• redis.com/memory-optimizations
• redis.com/ebook/intset-encoding-for-sets
관련된 다른 글


Principal DBA(MySQL, AWS Aurora, Oracle)
핀테크 서비스인 핀다에서 데이터베이스를 운영하고 있어요(at finda.co.kr)
Previous - 당근마켓, 위메프, Oracle Korea ACS / Fedora Kor UserGroup 운영중
Database 외에도 NoSQL , Linux , Python, Cloud, Http/PHP CGI 등에도 관심이 있습니다
purityboy83@gmail.com / admin@hoing.io
