









Last Updated on 6월 18, 2023 by Jade(정현호)
안녕하세요
이번 포스팅에서는 KRaft 를 사용한 Kafka 에 대한 내용과 KRaft 에 대한 내용에 대해서 확인해 보도록 하겠습니다.
KRaft
카프카 클러스터를 구성 및 사용하게 되면(분산 애플리케이션 환경), 클러스터 환경 관리를 위한 코디네이터(애플리케이션)가 추가로 필요하기 마련 입니다.
이러한 코디네이터로 아파치 주키퍼가 많이 사용 되고 있으며, 카프카에서도 주키퍼와 같이 사용하는 형태로 개발되어 왔습니다.
주키퍼는 하둡의 서브 프로젝트 중 하나로 출발해서 2011년 아파치의 탑 레벨 프로젝트로 승격이 되며, 여러 애플리케이션과 함께 사용되는 대표적인 분산 시스템 코디네이터 애플리케이션 입니다.
카프카 클러스터에서 주키퍼의 사용 또는 역할로는 주키퍼의 지노드(znode)를 이용해 카프카의 메타데이터(metadata) 관리, 브로커 상태 관리(노드관리), 토픽 관리, 컨트롤러 관리 등의 역할을 하고 있습니다.
다만 주키퍼를 통한 카프카 외부에서 메타데이터 관리 하다보니 데이터 중복 또는 브로커의 메타데이터와 주키퍼의 메타데이터의 불일치, 시스템 복잡성 증가, 서버나 시스템이 추가로 더 필요하거나 더 많은 자바 프로세스 실행 필요와 같은, 더 많은 자원의 소모 등의 문제점이 있습니다.
그리고 컨플루언트의 블로그에서는 다음과 같이 말하고 있습니다.
Actually, the problem is not with ZooKeeper itself but with the concept of external metadata management.
(사실 문제는 ZooKeeper 자체가 아니라 외부 메타데이터 관리 개념에 있습니다.)
카프카 자체가 아닌 외부에서 메타데이터를 관리하기 때문에 카프카 입장에서 주키퍼 사용시 제약사항이나 한계성 등을 느끼게 되며, 이로 인해 kafka의 확장성에 제한이 되는 부분이 있다고 판단하였습니다.
그래서 이러한 여러가지 문제와 고민에 의해서 2019년에 이러한 종속성을 깨고 새로운 메타데이터 관리를 Kafka 자체에 도입할 계획을 만들게 되었습니다.
새롭게 메타데이터 관리를 위해서 만들어진 것이 KRaft 모드 입니다. KRaft 모드는 이전 컨트롤러를 대체하고 Raft 합의 프로토콜의 이벤트 기반 변형을 사용하는 Kafka의 새로운 쿼럼 컨트롤러 서비스를 사용합니다.

[그림1]
Kafka의 새로운 쿼럼 컨트롤러의 이점
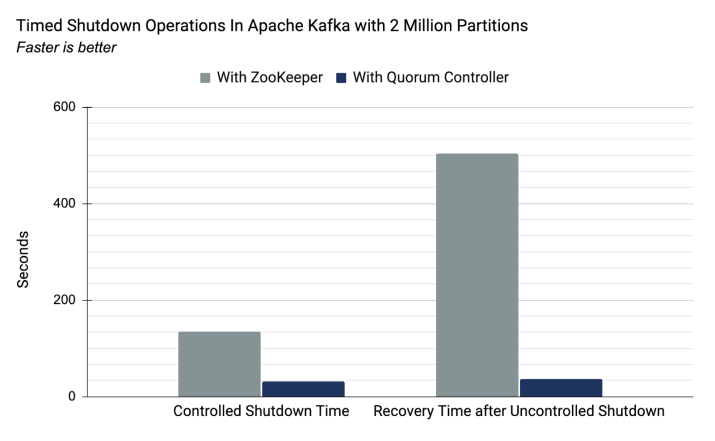
- Kafka 클러스터는 새로운 메타데이터 관리로 향상된 컨트롤 플레인 성능을 통해 수백만 개의 파티션으로 확장할 수 있습니다.
- 안정성을 개선하고, 소프트웨어를 간소화하며, Kafka를 보다 쉽게 모니터링, 관리 및 지원할 수 있습니다.
- Kafka가 전체 시스템에 대한 단일 보안 모델을 가질 수 있도록 합니다.
- Kafka를 시작하기 위한 간단한 단일 프로세스 방법 제공
- 컨트롤러 장애 조치(failover)를 거의 즉각적으로 만듭니다.
작동 원리
쿼럼 컨트롤러는 새로운 KRaft 프로토콜을 사용하여 메타데이터가 쿼럼 전체에 정확하게 복제되도록 합니다.
쿼럼 컨트롤러는 이벤트 기반 저장소 모델을 사용하여 상태를 저장하며, 이를 통해 내부 상태 시스템을 항상 정확하게 다시 만들 수 있습니다.
이 상태를 저장하는 데 사용되는 이벤트 로그(메타데이터 항목이라고도 함)는 로그가 무한정 증가할 수 없도록 스냅숏으로 주기적으로 요약됩니다.
쿼럼 내의 다른 컨트롤러는 활성 컨트롤러가 만들고 로그에 저장하는 이벤트에 응답하여 활성 컨트롤러를 따릅니다. 따라서 예를 들어 파티셔닝 이벤트로 인해 한 노드가 일시 중지된 경우 다시 조인할 때 로그에 액세스하여 놓친 이벤트를 빠르게 따라잡을 수 있습니다.
이렇게 하면 사용 불가 기간이 크게 줄어들어 최악의 경우 시스템 복구 시간이 향상됩니다.

[그림2]
KRaft 프로토콜의 이벤트 구동 특성은 ZooKeeper 기반 컨트롤러와 달리 쿼럼 컨트롤러가 활성화되기 전에 ZooKeeper에서 상태를 로드할 필요가 없음을 의미합니다.
리더십이 변경되면 새 활성 제어기에는 이미 메모리에 커밋된 모든 메타데이터 레코드가 있습니다. 또한 KRaft 프로토콜에 사용된 것과 동일한 이벤트 기반 메커니즘이 클러스터 전체에서 메타데이터를 추적하는 데 사용됩니다.
이전에 RPC로 처리 되던 작업은 이제 이벤트 기반이 될 뿐만 아니라 실제 로그를 통신에 사용하는 이점이 있습니다.
[그림3]
KRaft Release Timeline
Apache Kafka 2.8 버전부터 주키퍼 대신 kraft 를 사용할 수 있으나, 2.8.x 버전 부터 3.2.x 버전까지는 개발 단계(얼리 액세스,early access) 입니다.
Kafka 3.3.1 버전에서 부터 Production(운영)에서 사용할 준비가 되었음 발표하면서 KRaft 지원과 ZooKeeper 지원종료(제거)에 대한 릴리즈 타임라인을 발표 하였습니다.
For several years, we have been developing a new way to run Kafka with self-managed metadata. This new mode, called KRaft mode, addresses many urgent scalability and performance issues in Kafka.
Kafka 3.5 버전에서는 ZooKeeper Mode가 deprecated 되며, 3.7 버전에서는 ZK 모드가 포함된 마지막 버전이고, 4.0 버전에서는 KRaft mode 만 지원하는 것으로 계획되어 있습니다.
[참고] 포스팅 작성 기준으로 얼마전에(15 June 2023) Kafka 3.5 버전이 릴리즈 되었습니다.
We are proud to announce the release of Apache Kafka 3.5.0. This release contains many new features and improvements. This blog post will highlight some of the more prominent features. For a full list of changes, be sure to check the release notes.
Kafka 설치 With KRaft
KRaft를 사용하여 Kafka를 설치 해보도록 하겠습니다.(without zookeeper)
설치 환경 및 버전 정보
- OS : RockyLinux 8
- Kafka: 3.4.1(Scala version 2.13)
- JDK : JDK는 11 버전 이상 사용해야 하며, 포스팅에서는 17버전을 사용하였습니다.
- Kakfa 설치 위치 : /usr/local/kafka
- KRaft의 log.dirs 위치 : /usr/local/kafka/kraft-combined-logs
[참고] Temurin JDK 링크
파일 다운로드 및 압축 해제
wget https://downloads.apache.org/kafka/3.4.1/kafka_2.13-3.4.1.tgz tar xvf kafka_2.13-3.4.1.tgz -C /usr/local
* OS root 유저가 아닌 일반 유저 사용시 명령어 앞에 sudo 를 붙여서 사용 하시면 됩니다.
사용 및 관리 편의성을 위해서 심볼릭 링크를 생성 하도록 하겠습니다.
cd /usr/local ln -s kafka_2.13-3.4.1 kafka
properties 설정
config/kraft 디렉토리 아래에는 KRaft Mode를 위한 server.properties 기본 파일이 존재 합니다.
해당 파일을 수정 해서 사용하시면 됩니다.
1개의 서버(또는 가상화 VM) 에서 3노드 클러스터를 생성해서 사용하려면 server.properties에서 다음과 같이 3개의 새 파일을 만들어서 사용 하면 됩니다.
cp server.properties server1.properties
cp server.properties server2.properties
cp server.properties server3.properties
포스팅에서는 개발/테스트용으로 생성을 진행함으로 브로커가 1개인 카프카를 구성하였으며 그에 따라서 server.properties 파일을 1개를 이용하였습니다.
cd /usr/local/kafka/config/kraft vi server.properties ## log.dirs 수정 log.dirs=/usr/local/kafka/kraft-combined-logs
server.properties 에는 여러 설정 내역이 있으며, 구동이 가능한 기본값이 설정되어 있으며, 일단 구동을 위해서는 log.dirs 만 사용하는 환경에 맞게 수정해주시면 됩니다.
log.dirs 기본값은 "/tmp/kraft-combined-logs" 으로 설정(기재)되어 있으므로 /tmp/kraft-combined-logs 으로 사용하려고 할 경우 변경하지 않아도 됩니다.
포스팅에서는 /usr/local/kafka/kraft-combined-logs 경로를 사용하였으며, 그에 따라서 아래와 같이 디렉토리를 생성하였습니다.
mkdir -p /usr/local/kafka/kraft-combined-logs
Kafka 클러스터 ID 생성 및 포맷
kafka 서버를 시작하기 전에 kafka 클러스터 ID를 생성해야 하며, 아래와 같이 생성 할 수 있습니다.
cd /usr/local/kafka ./bin/kafka-storage.sh random-uuid jaShGO9YR12vntLHlWQQBA
실행하면 위와 같이 랜덤하게 생성된 uuid 를 확인 할 수 있습니다.
다음은 스토리지 디렉토리를 포맷합니다. 명령어는 아래와 같으며 위에서 확인된 uuid 를 입력 합니다.
cd /usr/local/kafka ./bin/kafka-storage.sh format -t jaShGO9YR12vntLHlWQQBA -c ./config/kraft/server.properties 실행 출력 내용) Formatting /tmp/kraft-combined-logs with metadata.version 3.4-IV0.
수행이 완료 되면 config/kraft/server.properties 파일의 log.dirs 파라미터에서 설정한 디렉토리가 포맷됩니다.
JAVA 환경 설정
테스트 및 개발 환경에서 특히 카프카 클러스터 구성시 1개 서버에서 다수의 Java 프로세스의 구동에 따라서 메모리가 다소 부족할 수 도 있습니다. 테스트 및 개발 등의 환경일 경우 다음과 같이 환경변수를 선언하여 사용하는 jvm 메모리량을 제한할 수 있습니다.
export KAFKA_HEAP_OPTS="-Xms512m -Xmx512m"
용량은 사용하는 시스템 환경에 따라서 조절하시면 됩니다.
사용하는 환경에 따라서 JAVA_HOME 변수를 선언해서 사용해야할 수 도 있습니다.
export JAVA_HOME=/usr/local/jdk-17.0.7+7
위와 같은 변수를 사용하는 OS유저 .bash_profile 에서 선언하여 사용할 수 있으며, 또는 kafka 실행전에 명시적으로 환경변수를 선언 후에 kafka를 실행하는 방법도 있습니다.
또는 bin 디렉토리에 있는 실행/종료 스크립트에서 공통적으로 호출(사용)하는 kafka-run-class.sh 파일내 최상단에서 선언 하여도 됩니다.
Kafka 시작/중지
Kafka 시작 및 중지하는 방법은 크게 systemd 서비스를 생성 하거나 kafka-server-start.sh/kafka-server-stop.sh 을 직접 실행하는 방법 두 가지로 나눌 수 있습니다.
• start.sh/stop.sh 사용
## 시작 cd /usr/local/kafka ./bin/kafka-server-start.sh -daemon ./config/kraft/server.properties ## 종료 cd /usr/local/kafka ./bin/kafka-server-stop.sh -daemon ./config/kraft/server.properties
• systemd 서비스 이용
systemd 서비스로 사용하기 위해서는 다음과 같이 service 파일 작성을 해야 합니다.
파일경로 및 파일명 : /etc/systemd/system/kafka.service
[Unit] Description=Apache Kafka server (broker) [Service] Type=forking User=root Group=root Environment='KAFKA_HEAP_OPTS=-Xms512m -Xmx512m' ExecStart=/usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/kraft/server.properties ExecStop=/usr/local/kafka/bin/kafka-server-stop.sh LimitNOFILE=16384:163840 Restart=on-abnormal [Install] WantedBy=multi-user.target
위와 같이 systemd 서비스 파일 작성이 완료 되었다면 처음에는 enable 설정을 진행한 다음 서비스를 시작 합니다.
## 서비스 enable 설정(1회 실행) sudo systemctl daemon-reload sudo systemctl enable kafka ## 시작 sudo systemctl start kafka ## 종료 sudo systemctl stop kafka
• 카프카 시작 점검
카프카 실행 후 정상적으로 실행 되었는지는 프로세스 체크와 포트 오픈 체크, 로그 확인 등을 진행합니다.
java 프로세스 체크로 kafka 프로세스 유무를 확인 합니다.
ps -ef | grep java | grep kraft/server.properties
포트 오픈 여부 체크는 9092 와 9093 포트에 대해서 체크합니다.
포트 오픈 여부 확인 sudo netstat -antp | grep 9092 tcp6 0 0 :::9092 :::* LISTEN 9671/java sudo netstat -antp | grep 9093 tcp6 0 0 :::9093 :::* LISTEN 9671/java tcp6 0 0 127.0.0.1:51664 127.0.0.1:9093 ESTABLISHED 9671/java tcp6 0 0 127.0.0.1:9093 127.0.0.1:51664 ESTABLISHED 9671/java
이번 포스팅에서는 KRaft와 KRaft 를 사용한 kafka 설치에 대해서 확인해보았으며, 포스팅은 여기에서 마무리 하도록 하겠습니다.
kafka 설치 이후에 Kafka Connect 를 이용한 DB CDC복제 설정에 관한 내용이 필요하실 경우 아래 포스팅을 이어서 읽어보시면 됩니다.
Reference
Reference URL
• confluent.io/learn/kraft
• confluent.io/what-is-kraft-and-how-do-you-use-it
• confluent.io/blog/removing-zk-dependency-in-kafka
• KAFKA/KIP-833
• KAFKA/KIP-500

Principal DBA(MySQL, AWS Aurora, Oracle)
핀테크 서비스인 핀다에서 데이터베이스를 운영하고 있어요(at finda.co.kr)
Previous - 당근마켓, 위메프, Oracle Korea ACS / Fedora Kor UserGroup 운영중
Database 외에도 NoSQL , Linux , Python, Cloud, Http/PHP CGI 등에도 관심이 있습니다
purityboy83@gmail.com / admin@hoing.io