









Last Updated on 9월 6, 2023 by Jade(정현호)
안녕하세요.
이번 포스팅에서는 Replica set 환경에서 프라이머리 선출, 프라이머리 텀 , 스텝 다운 등에 대해서 정리해 보려고 합니다.
전반적인 내용은 Real MongoDB 책과 MongoDB Document 를 참고하였으며 아래 포스팅에서 이어지는 글입니다.

Contents
프라이머리 선출(Primary Election)
레플리카 셋이 새로운 프라이머리를 선출 해야하는 이유는 단 한가지이며, 해당 레플리카 셋에 현재 프라이머리 멤버가 없기 때문입니다.
프라이머리 멤버가 없어진 또는 연결되지 않는 이유는 매우 다양할 수 있습니다.
해당 레플리카 셋에 프라이마리 멤버가 없으면 사용자 변경 요청을 처리 할수 없게 되며, Read Preference 옵션에 따라서 읽기 쿼리 조차도 불가능할 수도 있습니다.
그래서 레플리카 멤버들은 자기가 포함된 레플리카 셋에서 프라이머리가 없어진 것을 알아채면 즉시 새로운 프라이머리를 선출하는 로직을 실행 하게 됩니다.
MongoDB 에서 새로운 프라이머리 선출은 각 멤버의 동기화 문제가 매우 중요하며 MongoDB 3.0 버전까지는 각 서버가 인지하고 있는 시간(Wall Clock) 에 의존하였습니다. 하지만 실제 운영체계의 시간은 서버마다 차이가 있을수 있고 정확치 않을 수 있기 때문에 MongoDB 3.0 버전까지는 프라이머리 선출을 일정시간 주기로 한 번만 실행할 수 있도록 설계하였습니다.
하지만 이런 방식은 많은 문제점을 안고 있었습니다. 이를 해결하기 위해서 MongoDB 3.2 버전부터는 새로운 논리적인 시간이 도입되었습니다. MongoDB 3.0 까지의 프라이머리 선출 방식을 "Protocol version 0" 으로 칭하게 되고, MongoDB 3.2 버전부터 도입된 방식을 "Protocol Version 1" 이라고 하고 있습니다.
프라이머리 텀
MongoDB 3.0 버전까지의 레플리카 셋은 프라이머리 텀(term) 이라는 개념이 없었습니다.
그래서 프라이머리 선출 과정에서 여러 멤버가 동시에 투표를 하면 중복 투표의 위험도 있었으며, 이를 막기 위해 MongoDB 3.2 이전 버전에서는 프라이머리 선출 투표(Protocol Version 0) 를 30초에 한 번만 실행될 수 있도록 설계하였습니다.
이러한 설계의 문제점은 프라이머리 선출을 위한 투표가 한번 실패하게 되면 그 레플리카 셋은 30초 동안 프라이머리가 없는 상태로 대기하는 것을 의미하며, 그 시간동안 사용자 요청을 처리할 수 없음을 의미하게 됩니다.
MongoDB 3.2 이전 버전까지는 이런 중복 투표나 30초 대기 시간이 최대한 발생하지 않도록 실제 내부 적으로 2 단계 투표(Two-Phase Election) 을 실행하도록 설계되었습니다. 프라이머리 선출 시 사전 투표(Speculative-election) 와 본 투표(Authoritative-election) 두 단계로 나누어서 진행하였습니다.
프라이머리가 되고자 하는 세컨드리는 먼저 다른 세컨드리 멤버들에게 프라이머리가 되려고 할 때 반대하는지 하지 않는지를 확인하고, 다른 세컨더리 멤버들이 반대하지 않으면 그때 본 선거를 시작하게 되는 것입니다.
즉 사전 선거를 통해서 본 서거의 실패 상황(프라이머리를 선출하지 못하는 상황)을 최소화하고자 한 것입니다.
MongoDB 3.2 버전(Protocol Version 1) 부터는 위와 같은 복잡한 선출 과정을 해결하기 위해서 프라이머리 텀(논리적인 시간의 의미로 사용)이라는 개념이 도입되었습니다. 투표 식별자이며, 레플리카 셋의 각 멤버들이 프라이머리 선출을 시도할 때마다 1씩 증가하는 논리적 시간(Logical Time) 값입니다. 그래서 각 멤버들은 투표 요청이 식별자를 기준으로 자기가 투표를 했는지 아니면 다시 투표에 참여하는지 결정할 수 있게 됩니다.
(그래서 프라이머리 텀(Term) 은 투표 식별자(Vote Identifier) 이라고도 불립니다)
프라이머리 텀은 단순히 투표를 할 때만 사용되는 것이 아니라 프라이머리 멤버가 사용자의 데이터 변경 요청을 실행한 다음 변경 내용을 OpLog 에 기록할 때마다 현재 텀(Term) 식별자를 같이 기록을 하게 됩니다. 그 정보를 이용해 특정 OpLog가 어느 멤버가 프라이머 였을 때 로그 인지를 식별할 수 있게 해줍니다.
프라이머리 멤버가 네트워크 문제나 서버 장애로 연결할 수 없게 되면 투표가 시작되고, 새로운 프라이머리를 선출하게 됩니다. 이때 부터 프라이머리 텀이 1 증가하게 됩니다.
하지만 프라미머리 선출을 위한 투표가 항상 성공하는 것은 아닙니다. 즉 새로운 프라이머리를 뽑지 못하고 투표에 실패할 수도 있으며 이럴 경우에는 프라이머리 텀 값만 증가하고 끝나게 됩니다. 그리고 새로운 투표를 다시 시작하게 됩니다.
그리고 새로운 프라이머리가 선출되면 그때 부터 프라이머리 텀이 다시 1 증가하게 되는 과정으로 진행되게 됩니다.
프라이머리 스텝 다운
Replica set 에서 Primary 가 보이지 않으면 다른 Secondary 멤버들은 모두 자신의 레플리카 셋에 프라이머리 멤버가 없다고 판단하게 됩니다. 레플리카 셋 설정된 electionTimeoutMillis 내에 응답이 없다면 레플리카 셋의 각 멤버는 현재 Primary가 없어졌다고 판단하여 새로운 Primary 선출을 위한 투표를 시작하게 됩니다.
이렇게 장애나 문제 등에 의해서 프라이머리가 없어지는 상황뿐만 아니라 다음의 명령을 통해서 관리자가 의도적으로 프라이머리를 세컨더리로 내리는(Step Down) 작업도 할 수 있습니다. 다음의 명령어 두개는 MongoDB 관리 작업을 위해서 프라이머리를 세컨더리로 전환하기 위해서 사용할 수 있게 됩니다.
- rs.stepDown() 명령으로 프라이머리를 스텝 다운함
- rs.reconfig() 명령으로 레클리카 셋 멤버의 우선 순위(Priority) 를 변경함
rs.stepDown()
rs.stepDown() 는 아래와 같이 2개의 인자값을 통해서 사용하게 됩니다.
rs.stepDown(stepDownSecs, secondaryCatchUpPeriodSecs)
rs.stepDown() 명령은 프라이머리 멤버에서만 실행할 수 있으며, 이 명령이 실행되면 즉시 프라이머리를 내려놓고 stepDownSecs 파라미터에 지정한 시간동안 다시 프라미머리가 될 수 없게 됩니다. 즉 다른 세컨더리 멤버가 프라이머리가 될 수 있는 시간적 여유를 지정하는 것입니다.
만약 stepDownSecs 시간 동안 세컨더리 멤버 중에서 새로운 프라이머리가 선출되지 못한다면 원래 프라이머리였던 멤버가 다시 프라이머리로 선출될 가능성이 높게 되는 방식입니다.
그리고 프라이머리가 스텝 다운을 하게 되면 그 레플리카 셋에는 일시적으로 프라이머리가 없느 상태가 되게 됩니다. 물론 프라이머리가 없는 시간을 최소화하면 최소화할 수록 사용자 요청을 빨리 처리할 수 있을 것입니다. 하지만 기존의 프라이머리가 스텝 다운되는 시점에 다른 세컨더리가 기존 프라이머리의 OpLog 내용을 모두 반영(복제 완료)하였다고 보장하기는 어렵습니다.
만약 데이터 변경이 많아서 복제가 지연되고 있는 상태라면 밀린 복제에 대해서 동기화 완료를 위해 더 많은 시간이 필요할 수도 있습니다. 그래서 rs.stepDown() 명령은 두 번째 인자로 주어진 secondaryCatchUpPeriodSecs 파라미터의 시간동안 새로운 프라이머리를 선출하지 않고 기다리면서 밀려 있던 복제가 모두 완료(동기화) 되기를 기다리게 됩니다.
그렇다고 해서 무조건 프라이머리 선출을 secondaryCatUpPeriodSecs 파라미터의 시간동안 미루는 것이 아니라 최대한 기다린다는 의미입니다. 즉 복제 동기화가 2~3초 만에 완료된다면 레플리카 셋은 secondaryCatUpPeriodSecs 시간만큼을 기다리지 않고 완료되면 바로 프라이머리를 선출을 시작합니다.
rs.config()
rs.config() 명령은 사실 세컨드리를 프라이머리로 전환하는 등의 레플리케이션의 역할(Role) 을 변경하는 직접적인 명령어는 아닙니다.
하지만 rs.reconfig() 명령으로 레프리카 셋 멤버의 priority 를 변경하면 기존의 프라이머리가 즉시 세컨더리 멤버로 전환이 되게 됩니다.
다음과 같이 3개의 멤버로 구성된 레플리카 셋이 있습니다.
호스트명 역할 Priority
----------------------------------------------------
mongodb1 Primary 1
mongodb2 Secondary 1
mongodb3 Secondary 1
먼저 config 상태를 조회해 보겠습니다.
test-rs-0:PRIMARY> rs.conf()
{
"_id" : "test-rs-0",
"version" : 4,
"term" : 3,
"protocolVersion" : NumberLong(1),
"writeConcernMajorityJournalDefault" : true,
"members" : [
{
"_id" : 0,
"host" : "mongodb1:27017",
"arbiterOnly" : false,
"buildIndexes" : true,
"hidden" : false,
"priority" : 1,
"tags" : {
},
"slaveDelay" : NumberLong(0),
"votes" : 1
},
{
"_id" : 1,
"host" : "mongodb2:27017",
"arbiterOnly" : false,
"buildIndexes" : true,
"hidden" : false,
"priority" : 1,
"tags" : {
},
"slaveDelay" : NumberLong(0),
"votes" : 1
},
{
"_id" : 2,
"host" : "mongodb3:27017",
"arbiterOnly" : true,
"buildIndexes" : true,
"hidden" : false,
"priority" : 0,
"tags" : {
},
"slaveDelay" : NumberLong(0),
"votes" : 1
}
],
"settings" : {
"chainingAllowed" : true,
"heartbeatIntervalMillis" : 2000,
"heartbeatTimeoutSecs" : 10,
"electionTimeoutMillis" : 10000,
"catchUpTimeoutMillis" : -1,
"catchUpTakeoverDelayMillis" : 30000,
"getLastErrorModes" : {
},
"getLastErrorDefaults" : {
"w" : 1,
"wtimeout" : 0
},
"replicaSetId" : ObjectId("6241da4c826dbf781c4e0559")
}
}
Note
MongoDB 3.6 버전 부터 Arbiter 의 우선 순위는 0 이 되었습니다. MongoDB 3.6으로 Replica set 을 업그레이드할 때 기존 구성에서 Arbiter의 우선 순위가 1인 경우 MongoDB 3.6 에서 Arbiter 의 우선 순위가 0 이 되도록 재구성하게 됩니다.
Arbiter 는 1개의 선출 투표권을 가지고 있으며, 기본적으로 우선 순위는 0으로 설정됩니다.
Arbiter가 아닌 일반 멤버에서도 우선 순위 0은 Primary가 될 수 없는 구성원입니다.
우선 순위 0인 멤버는 Secondary 멤버가 아닌 Passive 멤버가 됩니다.
이 레플리카 셋의 프라이머리에 접속해서 다음과 같이 mongodb2 멤버의 priority 를 2로 변경하고 rs.reconfig() 명령으로 레플리카 셋의 속성 설정을 변경 진행하겠습니다.
test-rs-0:PRIMARY> var cfg = rs.conf()
test-rs-0:PRIMARY> cfg.members[1].priority=2
test-rs-0:PRIMARY> rs.reconfig(cfg)
{
"ok" : 1,
"$clusterTime" : {
"clusterTime" : Timestamp(1649757106, 1),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
},
"operationTime" : Timestamp(1649757106, 1)
}
[엔터 몇번입력]
test-rs-0:SECONDARY>
<-- prompt 가 변경 되었음
위의 명령으로 레플리카 셋의 설정이 변경되면 현재 프라이머리인 mongodb1 멤버는 자기 자신보다 높은 순위(priority)를 가진 멤버가 레플리카 셋에 나타난 것을 확인하고 즉시 Primary 롤을 버리고(step down) 세컨더리로 전환하게 됩니다.
엔터를 몇번 입력하면 프롬프트에 확인되는 Role 정보도 PRIMARY 에서 SECONDARY 로 변경되게 됩니다
그러면서 레플리카 셋의 세컨더리들은 프라이머리가 없어졌기 때문에 다시 프라이머리 선출을 시도하게 되고, mongodb2 서버가 우선순위(priority)가 더 높기 때문에 프라이머리로 선출되게 됩니다.
사실 MongoDB 서버 내부적으로 rs.config() 명령으로 priority 를 변경하는 것과 rs.stopDown() 명령의 처리 로직(소스 코드상)은 동일 합니다. 단 하나의 차이가 있다면 rs.reconfig() 명령으로 priority 가 변경되는 경우에는 rs.stepDown(60,10,true) 을 실행하는 것과 같은 의미가 되는 것입니다.
여기에서 rs.stepDown() 의 첫 번재 인자 60은 stepDownSecs의 기본값이며, 두 번째 인자인 10은 secondaryCatchUpPeriodSecs의 기본값입니다. 그리고 rs.stepDown() 마지막 인자는 강제 모드(force 옵션)을 활성화할 것인지 결정하는 옵션입니다.
rs.stepDown() 명령에 앞에 있는 2개의 인자만 사용하는 경우에는 강제(force) 모드는 false 로 실행되지만, rs.reconfig() 명령은 강제(force) 모드를 true 로 실행하게 되는 것입니다.
rs.reconfig() 명령으로 Priority 를 변경해서 프라이머리를 스위칭하는 작업(이 방식을 MongoDB 메뉴얼에서는 Priority Takeover 라고 기재되어 있습니다)은 secondaryCatchUpPeriodSescs 를 무시하게 됩니다. 즉 rs.config() 명령어로 프라이머리를 스위칭 하게 되면 새롭게 프라이머리가 될 세컨더리 멤버가 복제 동기화를 완료할 시간을 주지 않고 바로 프라이머리로 선출이 수행되게 됩니다.
그래서 데이터 변경이 빈번한 경우에는 데이터 롤백이 발생할 가능성이 높습니다.
Priority 조정 시 고려할 점
MongoDB 3.2 버전부터는 레플리카 셋 멤버의 priority(우선 순위) 를 0 또는 1 만 사용할 것을 권한하고 있습니다.
그렇지 않으면 rs.stepDown() 명령어를 통해서 프라이머리 스위칭을 할 수 없으며 rs.reconfig() 명령으로 Priority 를 더 높여서 스위칭을 진행해야 하고, 이 방식으로는 복제가 완료되지 못한 변경 내용들은 롤백 될 수 있기 때문입니다.
또한 priority(우선순위) 변경으로 프라이머리 변경한 경우, 예를 들어 우선순위 1인 3개 멤버 중 하나를 1에서 2로 변경하여 프라이머리로 선출하여 사용하고 있던 중에 프라이머리 멤버가 문제가 생겼을 경우 케이스도 고려를 해야 합니다.
Failover가 발생되어서 나머지 2개 멤버 중 하나가 프라이머리로 승격되어 사용하던 중에 문제가 발생한 이전 프라이머리(우선 순위2)가 다시 Replica Set에 연결될 경우 해당 멤버의 우선 순위가 더 높기 때문에 다시 투표가 진행되어 프라이머리가 변경되게 됩니다.
즉, 잦은 프라이머리 변경이 발생할 수 있다는 것을 의미합니다.
그래서 명시적인 프라이머리 멤버의 교체는 가급적 우선 순위 변경보다는 rs.stepDown()을 이용하는 것이 좋스니다.
참고로 Priority 0 인 멤버는 프라이머리가 될 수가 없습니다.
프라이머리 선출 시나리오
MongoDB 레플리카 셋에서 프라이머리 멤버가 하드웨어 장애나 네트워크 문제로 인해서 다른 멤버와 통신이 되지 않을 경우(하트비트 메세지를 정상적으로 주고받지 못할 경우)에 MongoDB 레플리카 셋은 고가용성을 보장하기 위해서 세컨드리 멤버가 자동으로 새로운 프라이머리를 선출하기 위한 투표를 실행하도록 설계되어 있습니다.
정상적인 상태의 레플리카 셋에서 각 세컨더리들은 프라이머리가 처리한 데이터 변경 내역을 복제하면서 데이터를 동기화를 하게 됩니다. 그리고 한편으로는 레플리카 셋의 각 멤버들은 서로 하트비트 메세지를 주고받으면서 레플리카 셋의 각 멤버가 정상적으로 연결되어 있는지를 주기적으로 체크하게 됩니다.
이때 아래 그림과 같이 레플리카 셋의 모든 멤버는 서로 간에 하트비트 메세지를 전송하고 응답 메세지를 받게 됩니다.
즉 레플리카 셋이 3개의 멤버로 구성되어 있다면 한 번 체크 주기에 6개의 하트비트 메세지(3개의 멤버가 나머지 2개의 멤버에서 메세지를 전송하므로 3x2개의 메세지)가 오고 가는 것입니다.
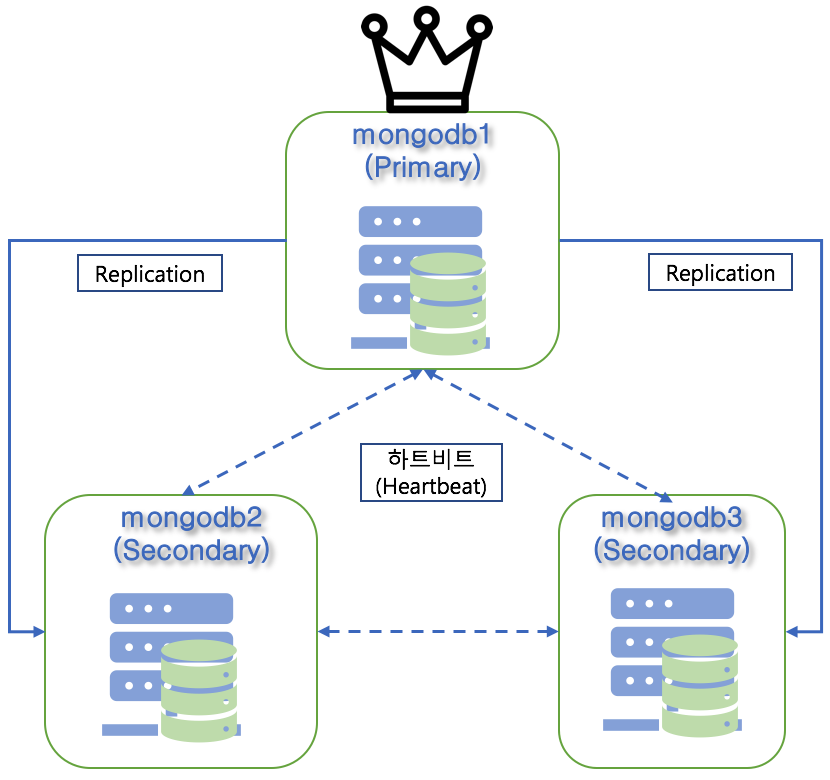
만약 7개의 멤버로 구성 되어있을 경우에는 42개의 하트비트 메세지가 오고 가게 됩니다. 그래서 MongoDB의 레플리카 셋에서 많은 멤버로 인하여 많은 멤버가 투표에 참여하게 되면 부담이 커질 수 있게 됩니다.
세컨더리 멤버는 다른 멤버로 전송한 하트비트 메세지에 대해서 지정된 시간(electionTimeoutMillis) 동안 응답을 기다리게 됩니다.
electionTimeoutMillis의 기본값은 10000ms (10 seconds) 입니다.
만약 이시간동안 응답이 없다면 그냥 그 멤버가 응답 불가능 상태라고 인지만 하게 됩니다. 하지만 프라이머리 멤버가 응답이 없다면 세컨더리 멤버는 즉시 새로운 프라이머리를 선출해야 한다는 것을 알고 새로운 투표를 시작하게 됩니다.

만약 프라이머리 멤버의 하드웨어와 MongoDB 서버는 정상적으로 작동하고 있지만, 멤버 간의 네트워크 연결에만 문제가 있을 때에는 프라이머리 멤버는 여전히 사용자의 데이터 변경 요청을 처리할 수는 있는 상태입니다.
하지만 이렇게 멤버 간의 네트워크 연결이 끊어졌는데도 프라이머리가 여전히 사용자의 요청을 처리하게 되면 스플릿 브레인(Split-brain) 현상이 발생할 수도 있습니다. 그래서 스프릿 브레인을 막기 위해서 전체의 과반수 멤버와 통신이 되지 않으면 자동으로 프라이머리에서 세컨더리 멤버로 강등(Demotion)되게 설계 되어있습니다.
멤버 간의 네트워크 문제가 발생했거나 프라이머리 멤버 서버에 문제가 있어서 기존 프라이머리 멤버는 두 세컨더리로 부터 연결이 불가능 할태가 되었을 경우 레플리키 셋에 남은 두 세컨드리는 둘 중에서 하나를 프라이머리로 선출하게 됩니다.
MongoDB의 프라이머리 선출 과정에서 중요한 부분은 아래 그림과 같은 Self-Election 입니다.

Self-Election 은 자가 선출로 해석할 수 있으며, MongoDB의 프라이머리 선출 알고리즘에서는 절대 다른 세컨더리 멤버를 프라이머리 후보로 추천하지 않습니다.
즉, 레플리카 셋에서 프라이머리가 없어지면 기본적인 요건만 채워지면 자기 자신이 바로 프라이머리 선출 투표를 개시하게 되는데 이때 후보는 반드시 자기 자신이 되게 됩니다.
MongoDB가 Self-Election 방식을 채택한 이유는 프라이머리 선출 과정이 복잡 하지 않고 쉽게 구현할 수 있으며, 직관적으로 작동하기 때문입니다.
먼저 세컨더리 mongodb2 가 프라이머리 선출을 시작하면 세컨더리 mongodb2 는 세컨더리 mongodb3에게 "내가 이번 Term 의 프라이머리가 되고자 한다. 당신은 내가 프라이머리가 되는 것을 찬성하는가?" 라는 메세지를 전달하게 됩니다.
그러면 세컨더리 mongodb3 는 몇 가지 현재 상태를 체크하고 세컨더리 mongodb2 에게 프라이머리가 돼도 좋을지 등의 결과를 전달하게 됩니다. 이때 세컨더리 mongodb3 가 체크하는 사항으로는 아래와 같은 내용이 있습니다.
- 세컨더리 mongodb2 가 현재 나(세컨더리 mongodb3) 와 같은 레플리카 셋 소속의 멤버인가?
- 세컨더리 mongodb2 의 우선순위가 현재 레플리카 셋에 있는 모든 멤버의 우선순위와 같거나 더 큰 값을 가지고 있는가?
- 세컨더리 mongodb2 가 요청한 투표의 Term이 내(세컨더리 mongodb3)가 지금까지 참여하였던 투표의 텀(Term) 보다 큰 값인가?
- 세컨더리 mongodb2 가 요청한 투표의 Term에 내(세컨더리 mongodb3)가 투표한적이 없는가?
- 세컨더리 mongodb2 가 나(세컨더리 mongodb3) 보다 더 최신의 데이터를 가지고 있거나 동등한 데이터를 가지고 있는가?(OpLog의 OpTime이 더 최신이거나 동등한 시점인가?)
위의 5가지의 체크 사항이 모두 참(True) 이라면 세컨더리 mongodb3 는 세컨더리 mongodb2 에게 "찬성" 메세지를 보내고 세컨더리 mongodb2 는 새로운 프라이머리가 되게 됩니다.
만약 5개의 체크 사항에 대해서 하나라도 거짓(False)이면 세컨더리 mongodb3 는 세컨더리 mongodb2의 투표 요청에 "거부(veto)" 의사를 표시하게 됩니다.
MongoDB의 프라이머리 선출에서는 "찬성" 또는 "거부" 만 가능하고 레플리카 셋의 멤버 중에서 과반수 이상의 멤버가 통신이 가능한 상태에서만 투표를 실시할 수 있으며, 그 멤버들 중 하나라도 "거부" 하게 되면 프라이머리 선출을 실패하게 됩니다(전원합의체)
MongoDB 3.0 버전까지는 프라이머리 선출에 "Protocol Version 0" 이 사용되었으며 이때는 레플리카 셋의 멤버가 투표에 대해서 "거부" 를 실행할 수 있었습니다. 하지만 3.2 버전의 "Protocol Version 1" 부터는 레플리카 셋의 멤버 "거부" 를 실행할 필요가 없어졌습니다.
"Protocol Version 0" 에서는 투표가 30초에 한 번만 실행될 수 있었기 때문에 멤버의 거부권 행사가 필요 하였습니다.
하지만 "Protocol Version 1" 에서는 프라이머리 선출 Term 만 증가시키면 지연 없이 얼마든지 새로운 투표를 시작할 수 있으므로 투표에 참여하는 멤버는 굳이 거부권을 행사할 필요가 없어졌습니다.
즉, 지금 새로운 프라이머리가 되고자 하는 멤버가 적절하지 않다고 판단되면 투표에 참여하는 멤버는 언제든지 새로운 투표를 시작해 버리기만 하면 거부권이 행사됨과 동시에 새로운 투표가 시작되게 되는 것입니다.
Reference
Reference Book
• Real MongoDB
Reference URL
• mongodb.com/replica-configuration
• mongodb.com/replica-set-arbiter
• mongodb.com/replica-set-protocol-versions
다음 이어지는 글
관련된 다른 글

Principal DBA(MySQL, AWS Aurora, Oracle)
핀테크 서비스인 핀다에서 데이터베이스를 운영하고 있어요(at finda.co.kr)
Previous - 당근마켓, 위메프, Oracle Korea ACS / Fedora Kor UserGroup 운영중
Database 외에도 NoSQL , Linux , Python, Cloud, Http/PHP CGI 등에도 관심이 있습니다
purityboy83@gmail.com / admin@hoing.io
